-
Enhancement
-
Resolution: Done
-
 Blocker
Blocker
-
3.6.0.Final
-
None
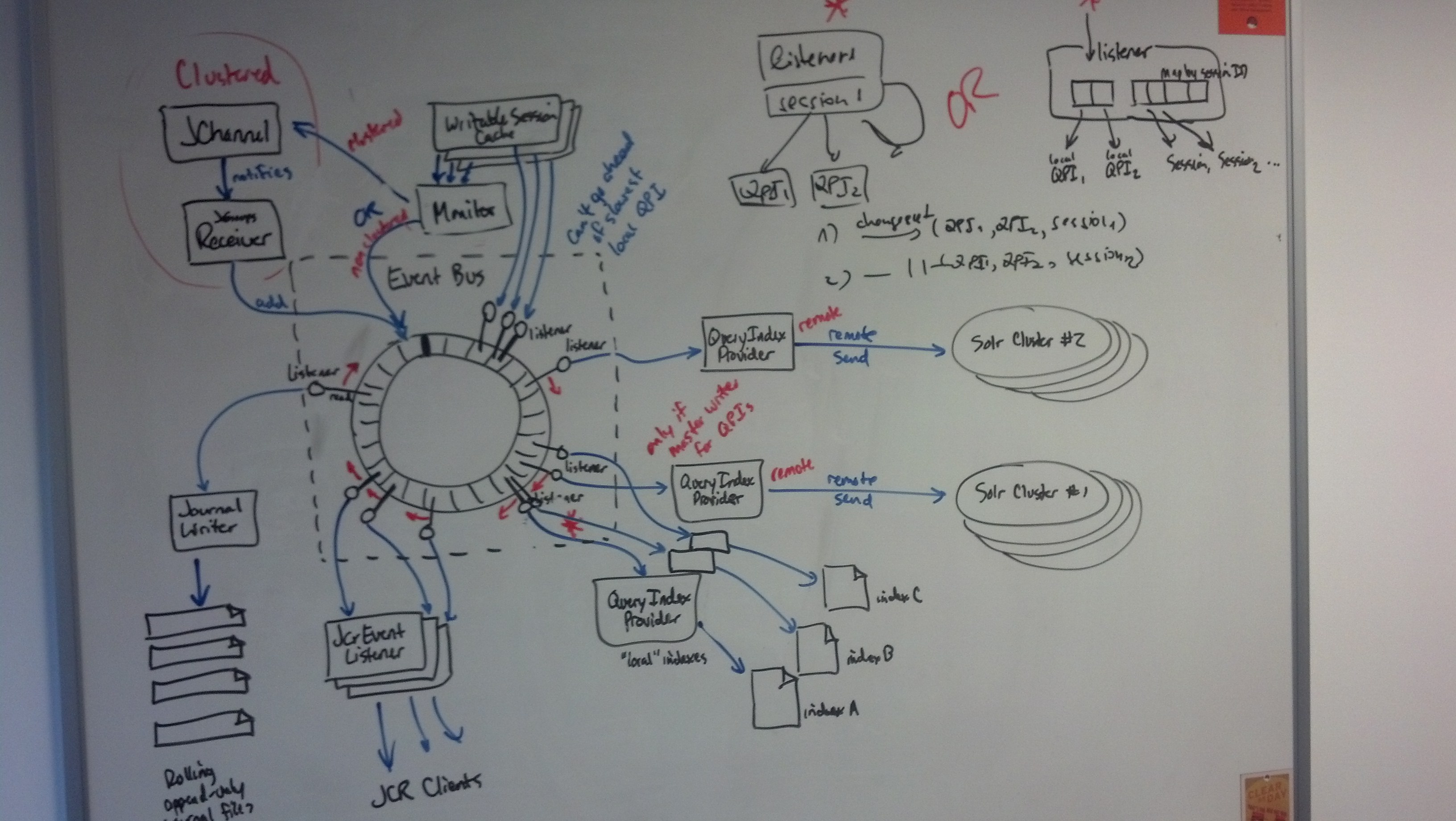
Our current event bus uses a separate queue for each listener. This becomes expensive with more and more listeners, and with 4.0 we are going to increase the number of internal listeners.
Rather than use separate queues, the bus should use a single ring buffer that each listener can process independently. This will reduce the memory overhead, and we can even do things like monitor the size of the ring buffer (which will pop off events automatically as soon as the last listener has processed those events) and dynamically respond via some policy to try to slow down the production of events (such as adding short waits within the Session saves). We can use a JGroups channel to signal to all processes that such throttling needs to be done across the cluster.
- blocks
-
-

- Resolved
-
