-
Bug
-
Resolution: Done
-
 Critical
Critical
-
None
-
None
-
None
-
5
-
False
-
-
False
-
Yes
-
-
-
RHOAM Sprint 34, RHOAM Sprint 37
WHAT
There is a memory leak in sendgrid service that is preventing jobs from being processed correctly after a certain point.
This might be the cause of MGDAPI-4930
In the attached screenshot, the memory started increasing from 04:00 - 10:00 and finally dropped after the container was restarted. When this pod was restarted, another pod was elected the leader and jobs were processed again.
Jobs looks to fail to list the subusers for checking sub user existance, but no error was logged or whether the subuser creation was successfull
I1216 04:17:47.093594 1 logger.go:84] executing job asynchronously, attempt 1 [scheduler=create_scheduler] [cluster_id=20kphn816rd9kjphf0hhcrfsoj8852ju] [cluster_uuid=58e86929-c92d-4b62-a7e4-06deb1a6d62b] [addon=Red Hat OpenShift Data Science] I1216 04:17:47.093614 1 logger.go:84] creating sendgrid smtp credentials [addon=Red Hat OpenShift Data Science] [scheduler=create_scheduler] [cluster_id=20kphn816rd9kjphf0hhcrfsoj8852ju] [cluster_uuid=58e86929-c92d-4b62-a7e4-06deb1a6d62b] I1216 04:17:47.096628 1 logger.go:84] checking if sub user 20kphn816rd9kjphf0hhcrfsoj8852ju exists [sendgrid=smtp_service_detail_provider] I1216 04:17:47.096644 1 logger.go:84] getting request with details endpoint=/v3/subusers host=https://api.sendgrid.com [sendgrid=sendgrid_service_api_client] I1216 04:17:47.096653 1 logger.go:84] performing api request with details, url=https://api.sendgrid.com/v3/subusers method=GET [sendgrid=sendgrid_service_api_client] I1216 04:17:47.494238 1 logger.go:84] [opid=2Iyqeka7ESYwjb8Yj5whCjOypnb] {"request_method":"GET","request_url":"/api/ocm-sendgrid-service","request_remote_ip":"10.129.16.1:45940"} I1216 04:17:47.495390 1 logger.go:84] getting request with details endpoint=/v3/subusers host=https://api.sendgrid.com [sendgrid=sendgrid_service_api_client] I1216 04:17:47.495408 1 logger.go:84] performing api request with details, url=https://api.sendgrid.com/v3/subusers method=GET [sendgrid=sendgrid_service_api_client] I1216 04:17:47.504409 1 logger.go:84] [opid=2Iyqeka7ESYwjb8Yj5whCjOypnb][tx_id=89209291] {"elapsed":"10.143628ms"} I1216 04:17:52.494358 1 logger.go:84] [opid=2IyqfJvIA8XVZLpp5xS8H6WFVL7] {"request_method":"GET","request_url":"/api/ocm-sendgrid-service","request_remote_ip":"10.129.16.1:49310"} I1216 04:17:52.497901 1 logger.go:84] [opid=2IyqfJvIA8XVZLpp5xS8H6WFVL7][tx_id=89209297] {"elapsed":"3.484438ms"} I1216 04:17:53.083448 1 logger.go:84] found no new jobs [scheduler=create_scheduler]
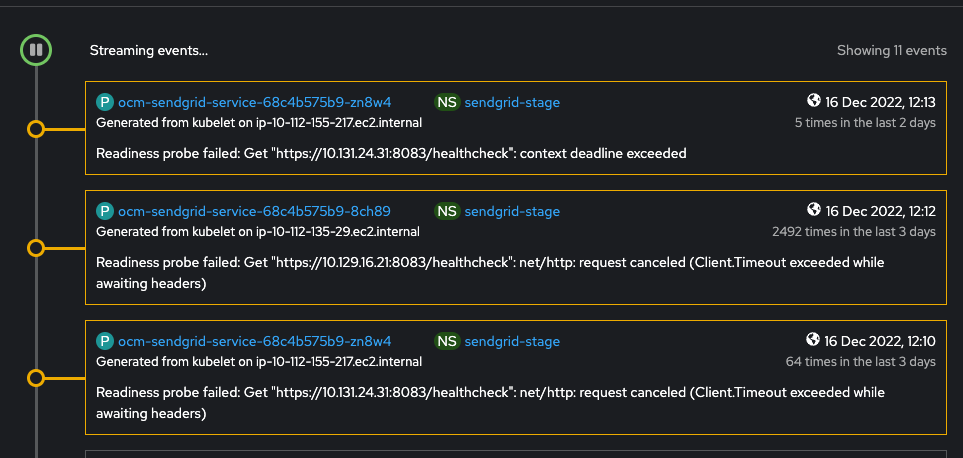
Additionally there is failing healthchecks from the events
HOW
TESTS
<List of related tests>
DONE
- Sendgrid memory leak fixed