-
Bug
-
Resolution: Can't Do
-
 Normal
Normal
-
None
-
Logging 5.7.z
-
False
-
-
False
-
NEW
-
NEW
-
Bug Fix
-
-
-
Important
Description of problem:
When used the default value for overflowAction, it's block with fluentd, when one of the outputs defined in the clusterLogForwarder reaches the totalLimitSize, fluentd stops of reading more logs and nothing more is log forwarder to the rest of the outputs defined, even, when the totalLimitSize for them are in good status
Version-Release number of selected component (if applicable):
Collector type: fluentd $ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.13.11 True False 3d6h Cluster version is 4.13.11 $ oc get csv NAME DISPLAY VERSION REPLACES PHASE cluster-logging.v5.7.6 Red Hat OpenShift Logging 5.7.6 cluster-logging.v5.7.5 Succeeded elasticsearch-operator.v5.7.6 OpenShift Elasticsearch Operator 5.7.6 elasticsearch-operator.v5.7.5 Succeeded
How reproducible:
Always
Steps to Reproduce:
For this reproducer, the totalLimitSize for the forwarder is set to 100M and it's configured the internal logStore Elasticsearch and an external output syslog.
1. Configure clusterLogging instance with the collector type fluentd as below:
$ oc get clusterlogging instance -o yaml -n openshift-logging
... spec:
collection:
logs:
type: fluentd
forwarder:
fluentd:
buffer:
totalLimitSize: 100m
logStore:
elasticsearch:
nodeCount: 3
resources:
limits:
memory: 1Gi
requests:
cpu: 500m
memory: 1Gi
storage: {}
2. Configure the clusterLogForwarder with two outputs, the internal Elasticsearch and an additional syslog output:
$ oc get clusterlogforwarder instance -o yaml -n openshift-logging ... spec: outputs: - name: syslogtest syslog: facility: local5 rfc: RFC5424 severity: info type: syslog url: tcp://syslog.example.com:9140 pipelines: - inputRefs: - infrastructure - application - audit name: all-to-default outputRefs: - default - syslogtest
The fluentd pods will fail to deliver the logs to the output defined syslogtest, then, the totalLimitSize will be reached for this output using the 100M defined on the disk. For verifying it, run the command below and observe the size of /var/lib/fluentd/syslogtest:
$ for pod in $(oc get pods -l component=collector -o name); do echo -e "\n\n### $pod ###"; oc exec $pod -- /bin/bash -c "du -khs /var/lib/fluentd/*"; done ... ### pod/collector-zhcgw ### Defaulted container "collector" out of: collector, logfilesmetricexporter 0 /var/lib/fluentd/default 24K /var/lib/fluentd/pos 0 /var/lib/fluentd/retry_default 102M /var/lib/fluentd/syslogtest
Actual results:
Fluentd stops of reading logs in global and not more logs are log forwarder to the rest of the outputs defined when one of the outputs reaches the totalLimitSize.
Verify the fluentd pos file is not more updated checking the time, meaning that not more logs are read:
$ for pod in $(oc get pods -l component=collector -o name); do echo -e "\n\n### $pod ###"; oc exec $pod -- /bin/bash -c "ls -l /var/lib/fluentd/pos"; done ... ### pod/collector-zhcgw ### Defaulted container "collector" out of: collector, logfilesmetricexporter total 24 -rw-------. 1 root root 65 Sep 21 07:21 acl-audit-log.pos -rw-------. 1 root root 59 Sep 21 07:21 audit.log.pos -rw-------. 1 root root 823 Sep 21 07:22 es-containers.log.pos -rw-------. 1 root root 139 Sep 21 07:22 journal_pos.json -rw-------. 1 root root 68 Sep 21 07:22 kube-apiserver.audit.log.pos -rw-------. 1 root root 208 Sep 21 07:22 oauth-apiserver.audit.log
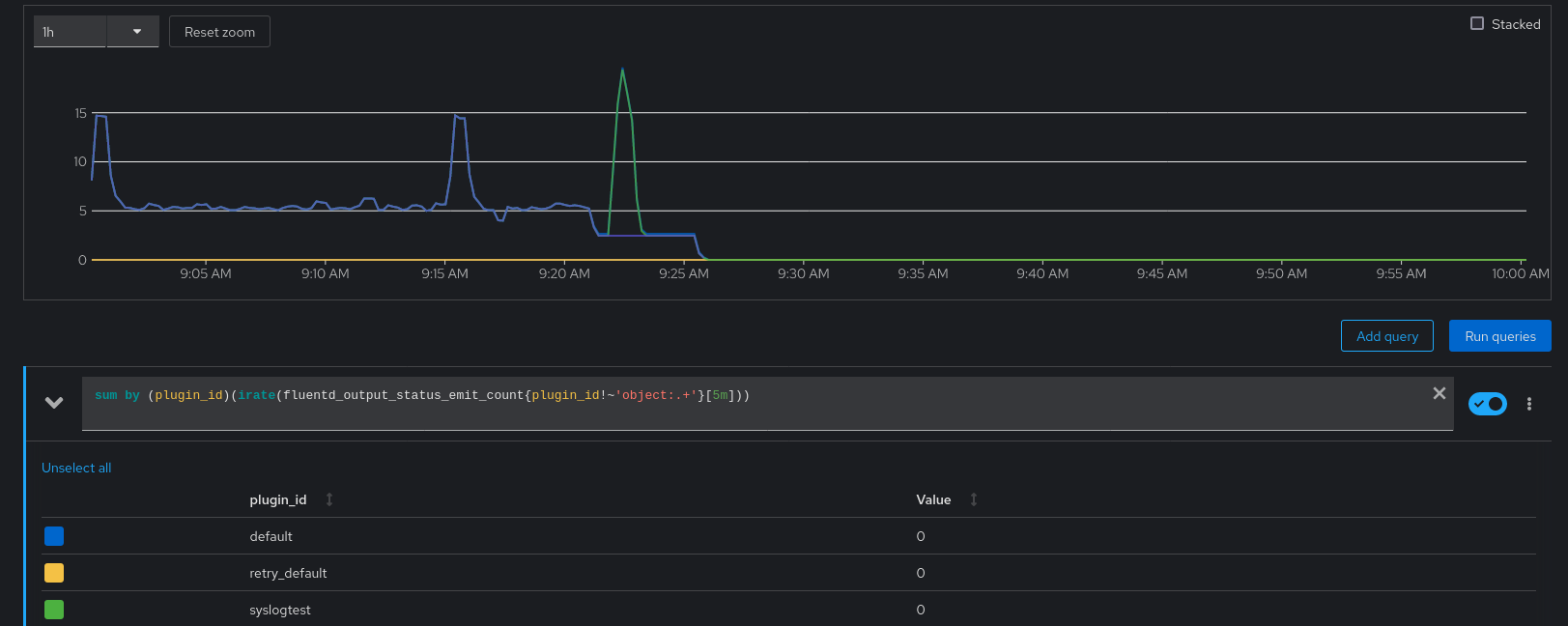
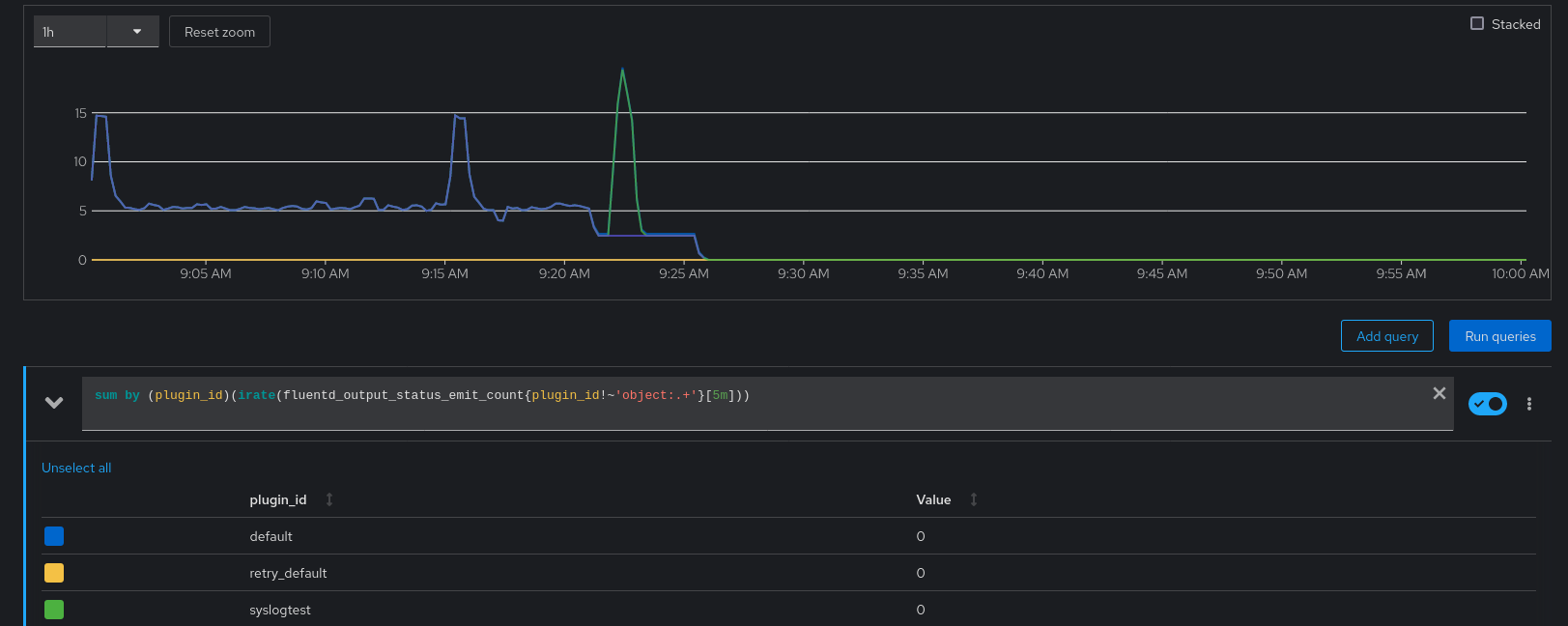
Verify the same going to the OCP Console > Observe > Metrics and run the query:
sum by (plugin_id)(irate(fluentd_output_status_emit_count{plugin_id!~'object:.+'}[5m]))
Expected results:
Fluentd continues reading logs and log forwarding to the rest of the outputs defined where the totalLimitSize is not reached.
Workaround
Even when it doesn't solve the problem for mitigate the impact, it could be changed for fluentd the overflowAction from the default: block to be drop_oldest_chunk. For more details: Advanced configuration for the Fluentd log forwarder