-
Bug
-
Resolution: Done
-
 Normal
Normal
-
Logging 5.8.0
-
False
-
-
False
-
NEW
-
VERIFIED
-
-
-
Log Collection - Sprint 239, Log Collection - Sprint 240, Log Collection - Sprint 241, Log Collection - Sprint 242, Log Collection - Sprint 243
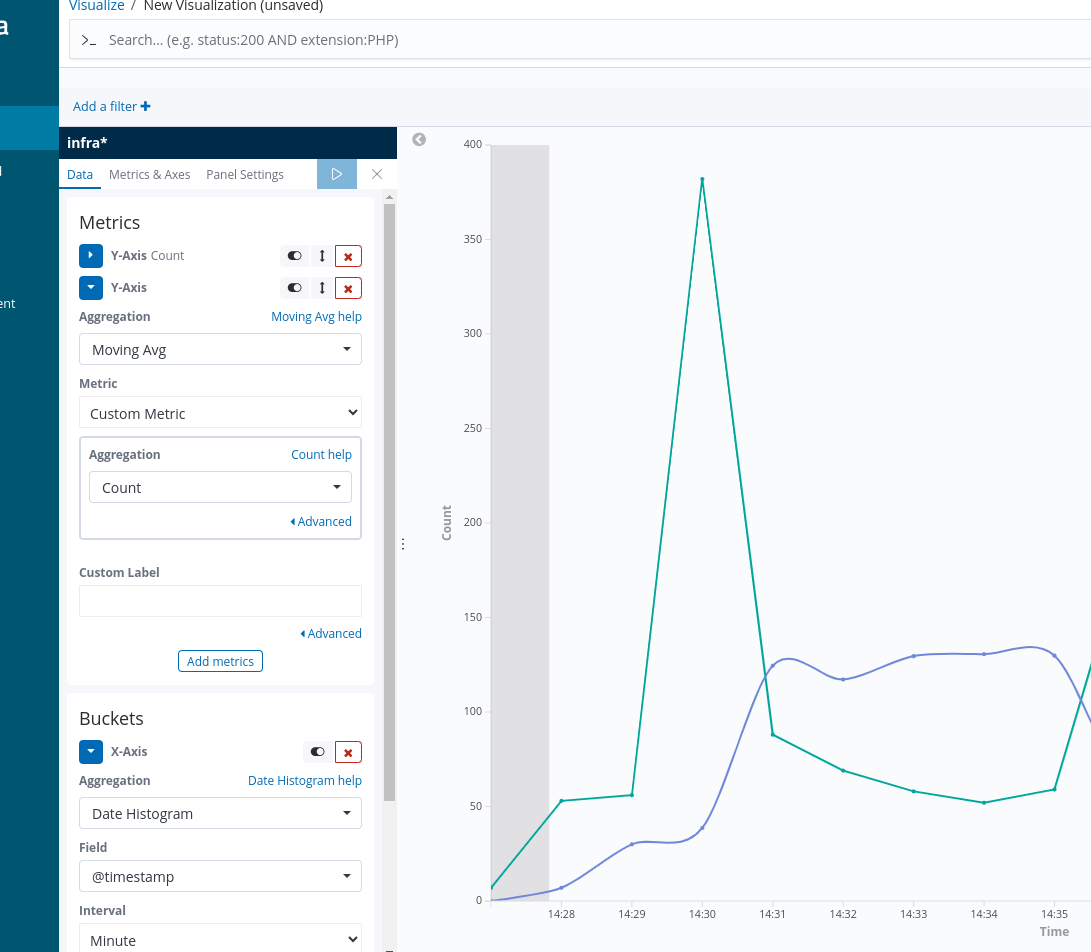
Description of problem:
Create 3 projects, and deploy some pods in these projects, each container generates 6000 records/minute:
$ oc get pod -n multiple-containers --show-labels NAME READY STATUS RESTARTS AGE LABELS centos-logtest-5np54 3/3 Running 0 13m run=centos-logtest,test=centos-logtest $ oc get pod -n multiple-pods --show-labels NAME READY STATUS RESTARTS AGE LABELS logging-centos-logtest-724mp 1/1 Running 0 12m run=centos-logtest,test=centos-logtest logging-centos-logtest-8txrf 1/1 Running 0 12m run=centos-logtest,test=centos-logtest logging-centos-logtest-j9dpv 1/1 Running 0 12m run=centos-logtest,test=centos-logtest $ oc get pod -n test-1 --show-labels NAME READY STATUS RESTARTS AGE LABELS logging-centos-logtest-brbr5 1/1 Running 0 11m run=centos-logtest,test=centos-logtest
Create a CLF with below yaml:
apiVersion: logging.openshift.io/v1 kind: ClusterLogForwarder metadata: name: instance namespace: openshift-logging spec: inputs: - application: groupLimit: maxRecordsPerSecond: 20 selector: matchLabels: run: centos-logtest test: centos-logtest name: limited-rates pipelines: - inputRefs: - limited-rates - infrastructure - audit name: to-default outputRefs: - default
Deploy logging, use vector as the collector, and using lokistack as the log store.
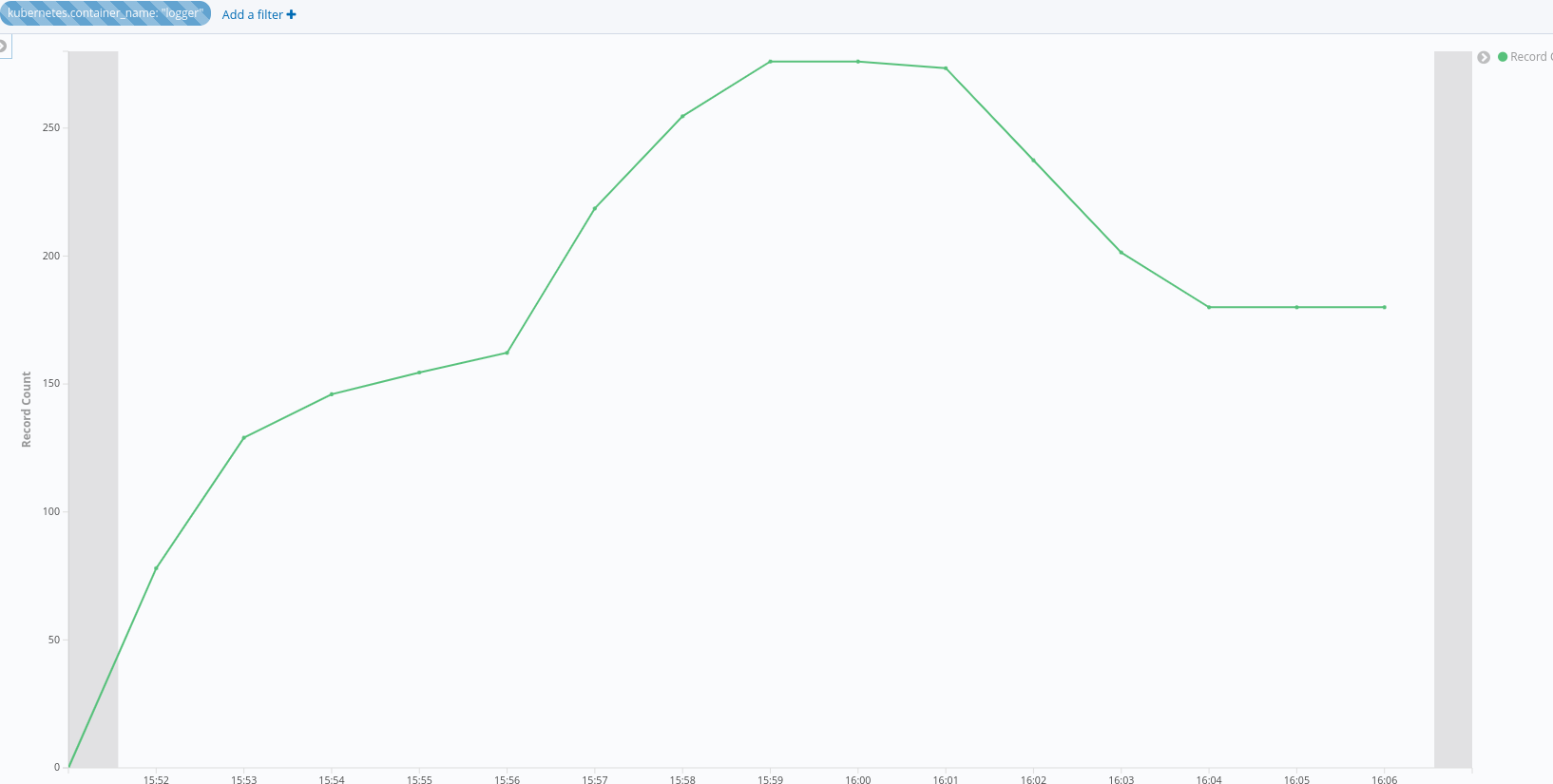
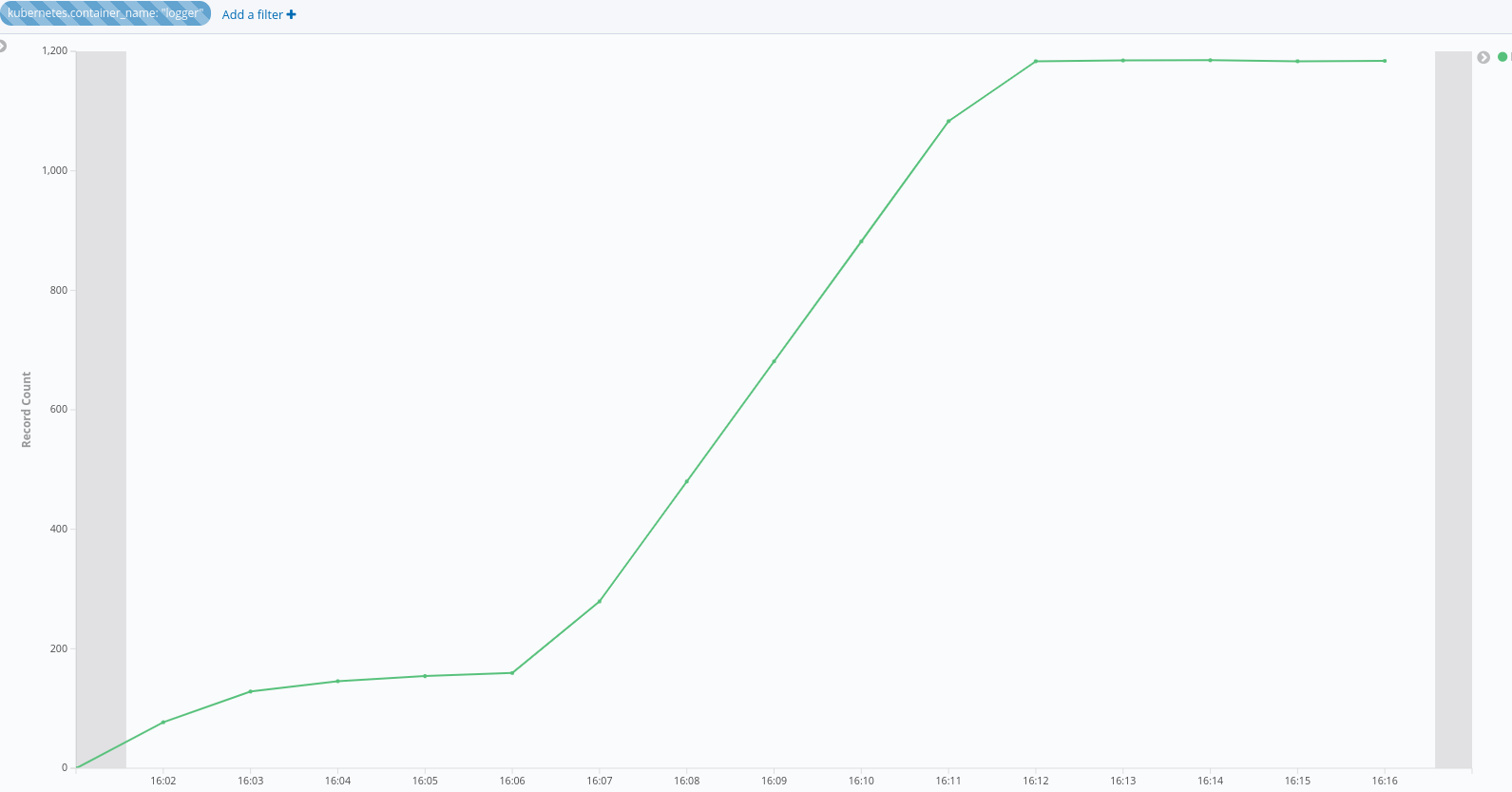
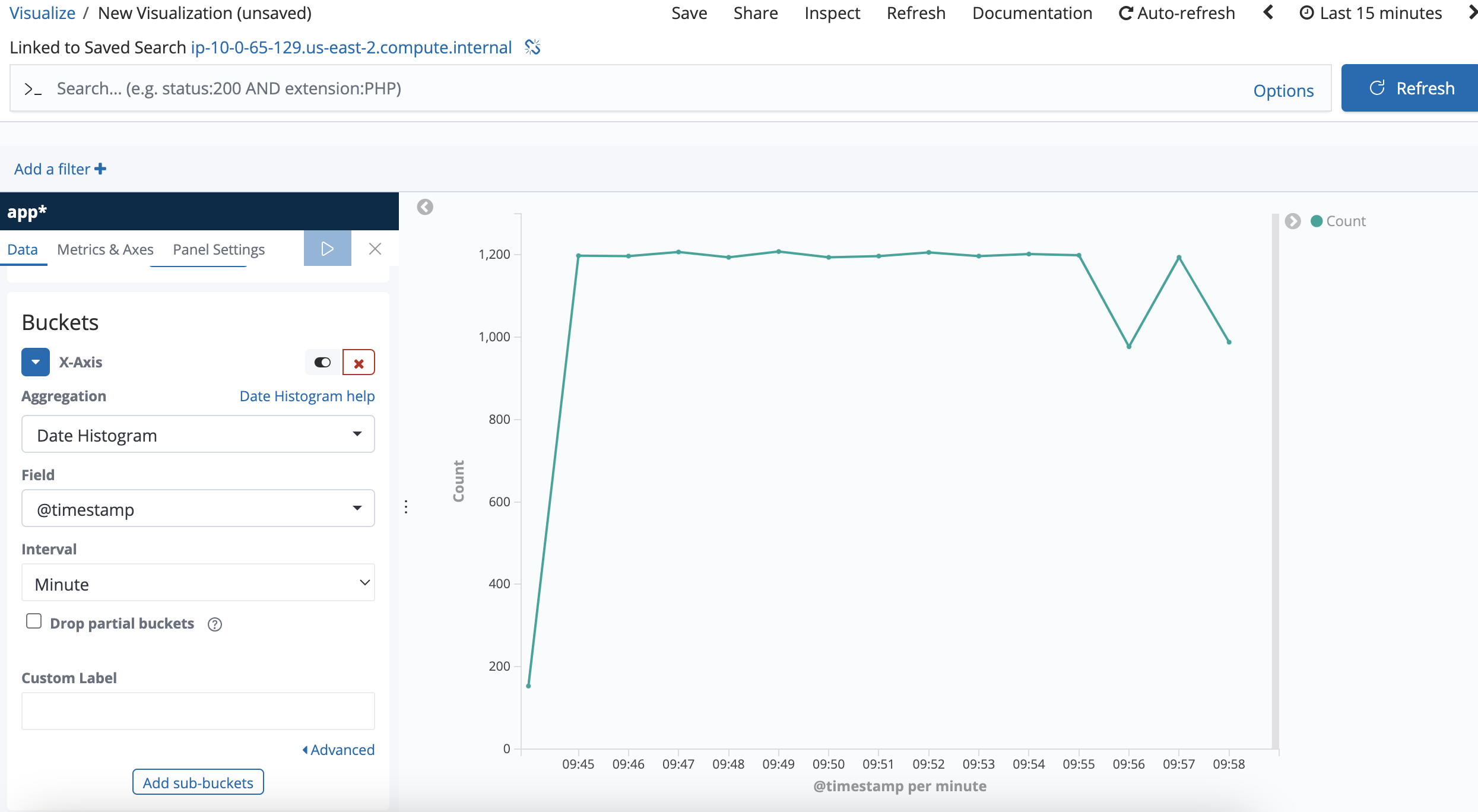
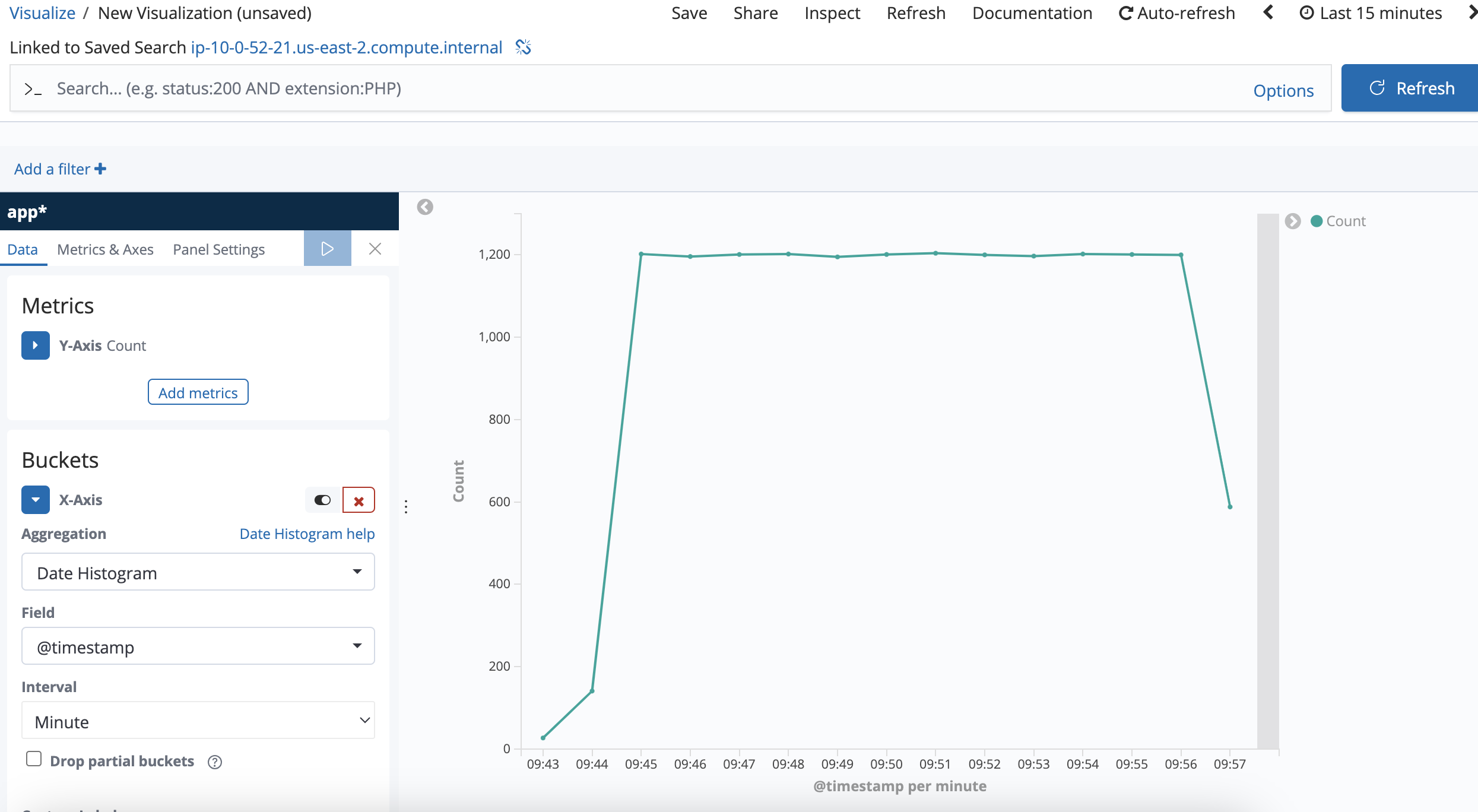
Wait for 2 minutes, then check data in lokistack:
sum by(log_type)(count_over_time({log_type=\"application\"}[1m])):
{
"metric": {
"log_type": "application"
},
"values": [
[
1689729244,
"798"
],
[
1689729272,
"2481"
],
[
1689729300,
"3580"
],
[
1689729328,
"3590"
],
[
1689729356,
"3584"
],
[
1689729384,
"3589"
]
]
}
sum by(kubernetes_pod_name, kubernetes_namespace_name)(count_over_time({log_type=\"application\"}[1m])):
"result": [
{
"metric": {
"kubernetes_namespace_name": "multiple-containers",
"kubernetes_pod_name": "centos-logtest-5np54"
},
"value": [
1689729385.518,
"41"
]
},
{
"metric": {
"kubernetes_namespace_name": "multiple-pods",
"kubernetes_pod_name": "logging-centos-logtest-724mp"
},
"value": [
1689729385.518,
"1200"
]
},
{
"metric": {
"kubernetes_namespace_name": "multiple-pods",
"kubernetes_pod_name": "logging-centos-logtest-8txrf"
},
"value": [
1689729385.518,
"11"
]
},
{
"metric": {
"kubernetes_namespace_name": "multiple-pods",
"kubernetes_pod_name": "logging-centos-logtest-j9dpv"
},
"value": [
1689729385.518,
"1145"
]
},
{
"metric": {
"kubernetes_namespace_name": "test-1",
"kubernetes_pod_name": "logging-centos-logtest-brbr5"
},
"value": [
1689729385.518,
"1191"
]
}
],
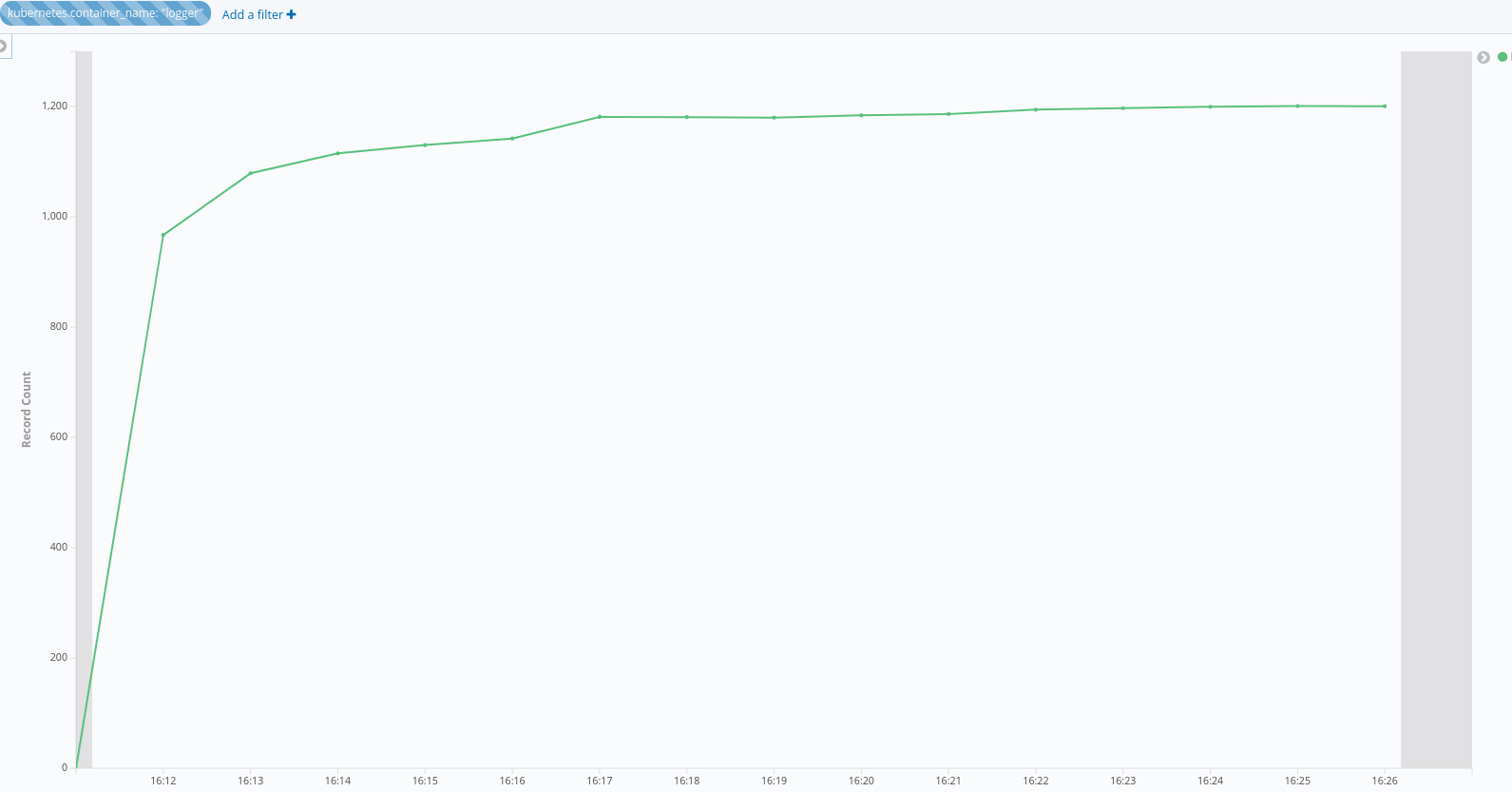
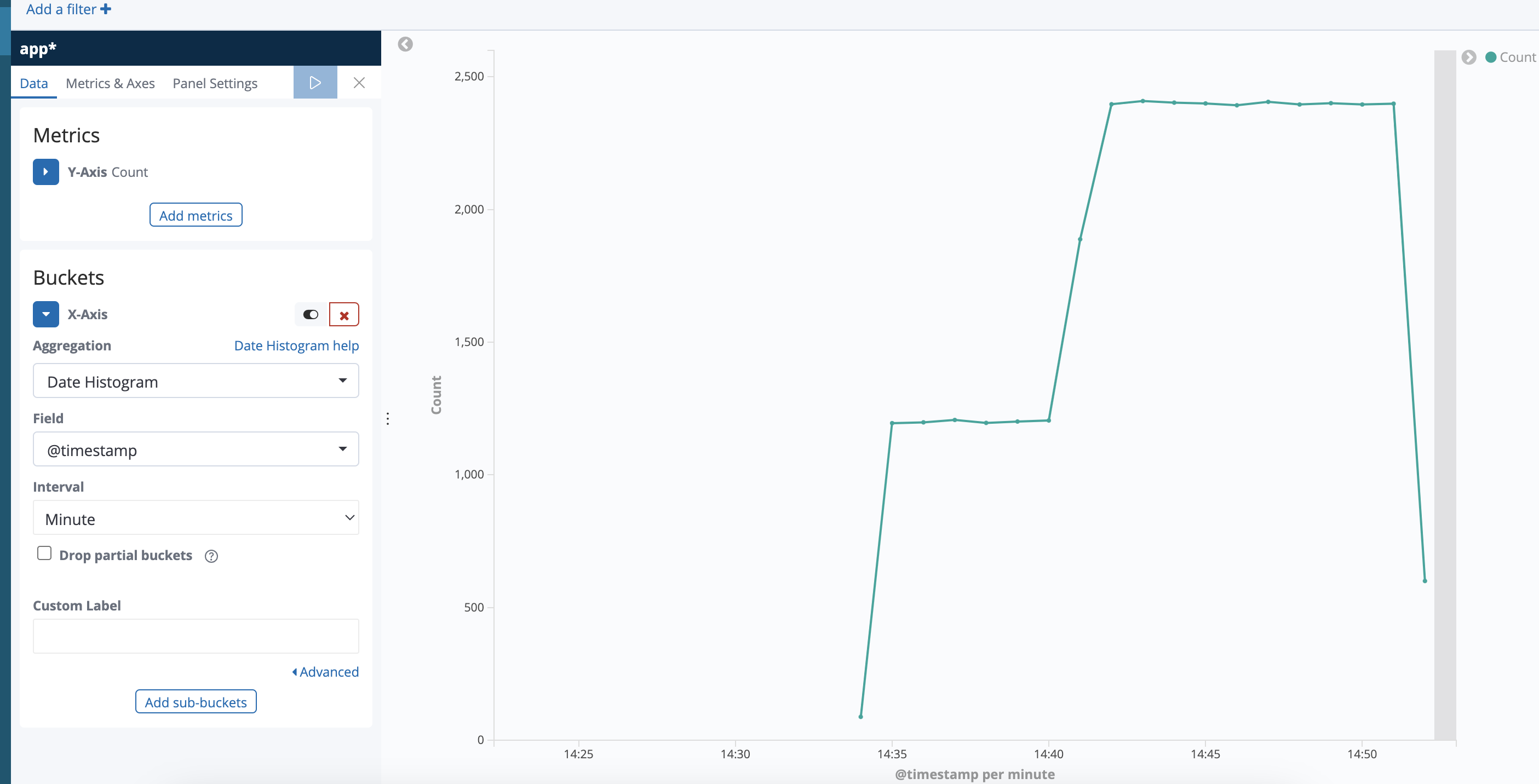
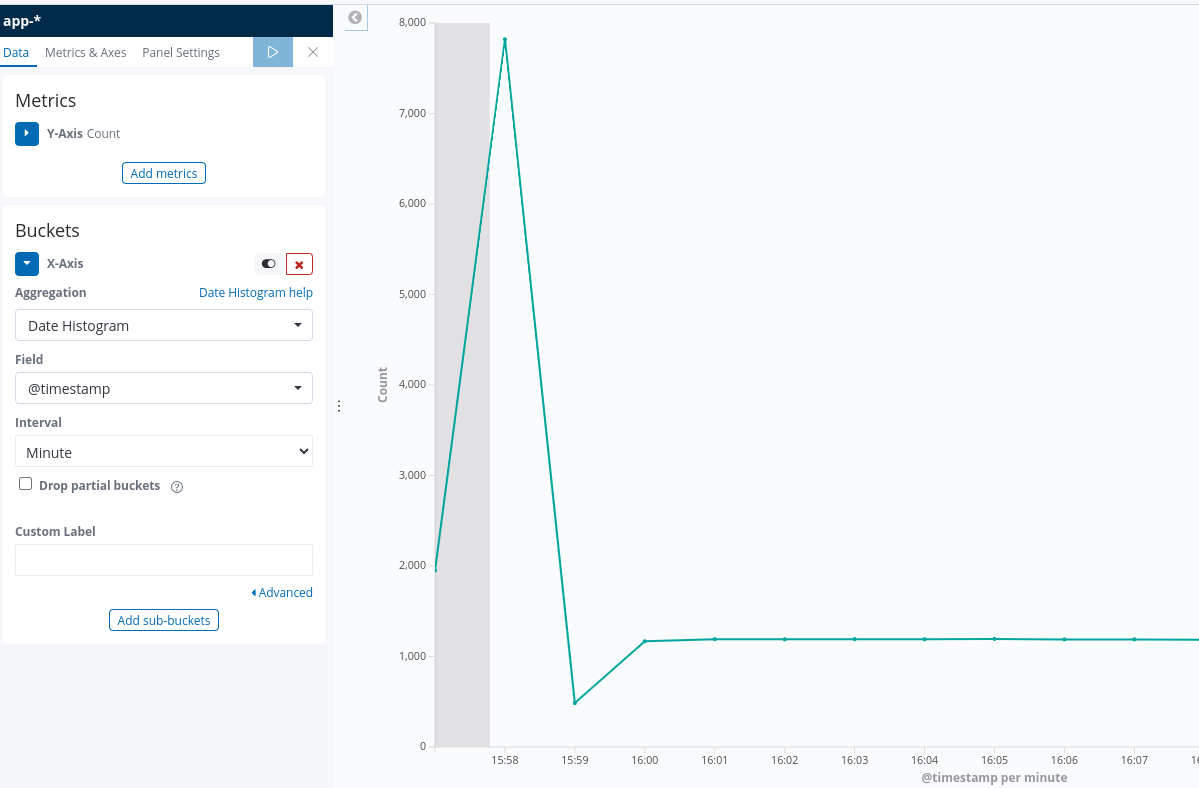
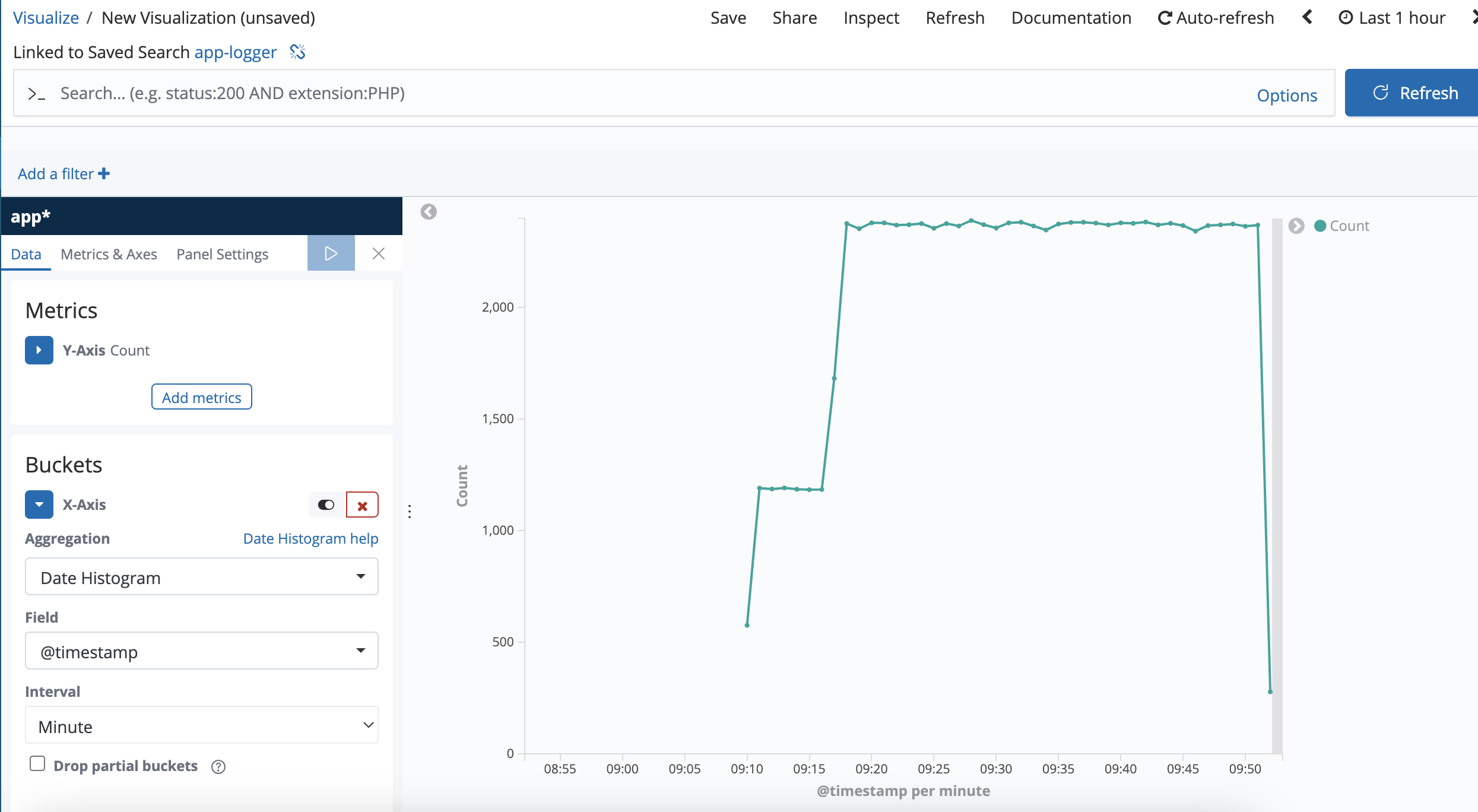
The records count in every minute is approximately equal to 3600, which exceeds the groupLimit 1200.
vector.toml: vector.toml![]()
Version-Release number of selected component (if applicable):
openshift-logging/cluster-logging-rhel9-operator/images/v5.8.0-79
How reproducible:
Always
Steps to Reproduce:
In `Description` part.
Actual results:
Expected results:
Records count in every minute should not exceed groupLimit.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}