-
Bug
-
Resolution: Done
-
 Critical
Critical
-
None
-
Logging 5.6.0, Logging 5.7.0
-
False
-
-
False
-
NEW
-
NEW
-
-
-
Log Collection - Sprint 235, Log Collection - Sprint 236, Log Collection - Sprint 237, Log Collection - Sprint 238
Description of problem:
On perfscale group we have tried to reach the limits of openshift-logging deployment.
Tried the tech-preview installation of vector for collector, as fluentd is deprecated (https://docs.openshift.com/container-platform/4.12/logging/v5_6/logging-5-6-release-notes.html#logging-release-notes-5-6-0_logging-5.6-release-notes)
Running following test to evaluate throughput of messages to be stored on ES: https://github.com/cloud-bulldozer/e2e-benchmarking/tree/master/workloads/logging
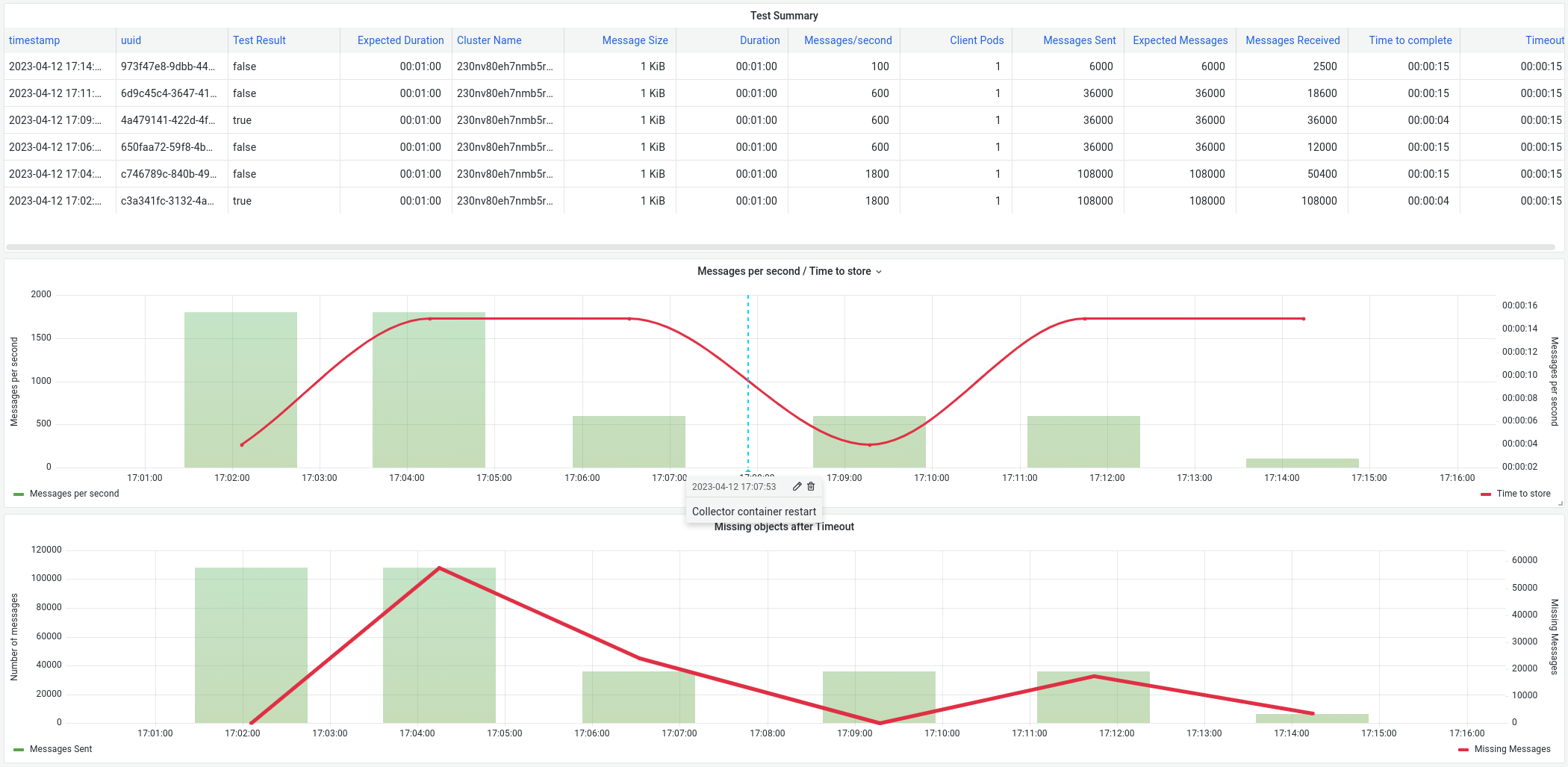
After executing with different sizes and messages/second, we found that vector starts to give following errors on the collector pod
{{{{2023-04-05T09:54:21.763268Z ERROR source
{component_kind="source" component_id=raw_container_logs component_type=kubernetes_logs component_name=raw_container_logs}
: vector::internal_events::kubernetes_logs: Failed to annotate event with namespace metadata. event=Log(LogEvent { fields: Object({"file": Bytes(b"/var/log/pods/benchmark-operator_log-generator-8e194d80-wnkgz_55347171-e0a0-40e7-a226-b157ea2661dd/log-generator/0.log"), "hostname": Bytes(b"ip-10-0-157-8.us-east-2.compute.internal"), "kubernetes": Object({"annotations": Object({"k8s.ovn.org/pod-networks": Bytes(b"{\"default\":{\"ip_addresses\":[\"10.128.0.32/23\"],\"mac_address\":\"0a:58:0a:80:00:20\",\"gateway_ips\":[\"10.128.0.1\"],\"ip_address\":\"10.128.0.32/23\",\"gateway_ip\":\"10.128.0.1\"}}"), "k8s.v1.cni.cncf.io/network-status": Bytes(b"[{\n \"name\": \"ovn-kubernetes\",\n \"interface\": \"eth0\",\n \"ips\": [\n \"10.128.0.32\"\n ],\n \"mac\": \"0a:58:0a:80:00:20\",\n \"default\": true,\n \"dns\": {}\n}]"), "k8s.v1.cni.cncf.io/networks-status": Bytes(b"[{\n \"name\": \"ovn-kubernetes\",\n \"interface\": \"eth0\",\n \"ips\": [\n \"10.128.0.32\"\n ],\n \"mac\": \"0a:58:0a:80:00:20\",\n \"default\": true,\n \"dns\": {}\n}]"), "openshift.io/scc": Bytes(b"anyuid")}), "container_id": Bytes(b"cri-o://29277be6ca8b5ff2120940f26286072348ee417b623f442faf6e4ace04a5f3cb"), "container_image": Bytes(b"quay.io/morenod/log_generator:logging"), "container_name": Bytes(b"log-generator"), "labels": Object(
{"app": Bytes(b"log-generator-8e194d80"), "benchmark-uuid": Bytes(b"8e194d80-2c64-4fc4-81d4-16cfa319bd8c"), "controller-uid": Bytes(b"69416009-09c5-47e3-940a-5d61cdbcab87"), "job-name": Bytes(b"log-generator-8e194d80")}
), "namespace_name": Bytes(b"benchmark-operator"), "pod_id": Bytes(b"55347171-e0a0-40e7-a226-b157ea2661dd"), "pod_ip": Bytes(b"10.128.0.32"), "pod_ips": Array([Bytes(b"10.128.0.32")]), "pod_name": Bytes(b"log-generator-8e194d80-wnkgz"), "pod_owner": Bytes(b"Job/log-generator-8e194d80")}), "message": Bytes(b"2023-04-05T09:54:21.242240875+00:00 stdout F ESC7AMML8S3HRVHQ0GK05H56EFW6TF8QL0U1CMEXL38RPHC911LK6I51JDUUTVYMATGEN4ARDRD6X9QF4O4BU6RGNYE2LMG0HYBPINOHPCAN5G2L3WHG4RI4XADL8ORLMDFZ4ARTF3TG8Q0XLRFMHNX8L0J6YBXCB4G266R1JYQ3ZPQL4VXK2JKWQWRVFP5MJI90PW0BMBZFBGC1T6IN4QVL4YHFNTMC0KKL2VGASQK4A94YNJW2HTGHDFX0A02SQ90IV57U52DY5TAYOM5BYG9KDU0941DOY3OC1VW70GS0P6ECSNTODY8RZQQOYLVWAF812PYQHB8V5401HMQPRRKGNJYM4S62311LFMI7PNC998AQPROTQM06KXA4DLQKUK75M67KE8TE8VV0VFIYBVCUF11E4TLU2A5MOCYGW0LG0G6OD3Q3QLLC0JJQAKQYE6EZZPR61DC9MS0QHUK6OI67SEVLGI7XX4O1QG2ZNFFFNZK3TF4P0GLAYWXFPAUU2VZB2174ON81ZQ3OJVCGTKOC3YZRG2XIU1B9QP3318ICF4KGULSEFYVYS4I2KBFRJZH6R9K3JBX6X8AQVMO51ZFOSGU50WATUDVH5TAWMD7DG3SKNIRCNCWEI7VCQP7H9KAMQA9OPKW87FJ3019AZFX1ZTWU83L158LA6HEZF3HBJPMJ5P6E970LPJQKZNK0PWIC3R05QM0W1FUJST9TYSNABIKKOAFWPZA0DY71LVDMNNOTOAUSGBZ9G9POEGKDNX1GDLXK1H1D8UNVJ6RON7V4D8H316G534WW4ER89U7QBUNEUFZ30EVNKWJLWY0DYV5FLFO2HNSQ9JZ4KHACTIFG8XB453PYF4N7DEE8R89WWL02DS7YCLD3QP5TMXUA2W006HLE9R6FLSXREPX83CS7XRXK0CZ5YLKHZL1QIA4OAMO6CKAVYX84H6Q6AB886NFHRZ9N4O7DCNH3X8WD1YQJDYBL28A3VEUFG8ELFE05B4DK8MCBUB47A948E5OQ"), "source_type": Bytes(b"kubernetes_logs"), "timestamp": Timestamp(2023-04-05T09:54:21.763252989Z)}), metadata: EventMetadata { datadog_api_key: None, splunk_hec_token: None, finalizers: EventFinalizers([]), schema_definition: Definition { collection: Collection { known: {}, unknown: None }, meaning: {}, optional: {} } } }) error_code="annotation_failed" error_type="reader_failed" stage="processing" rate_limit_secs=10}}}}
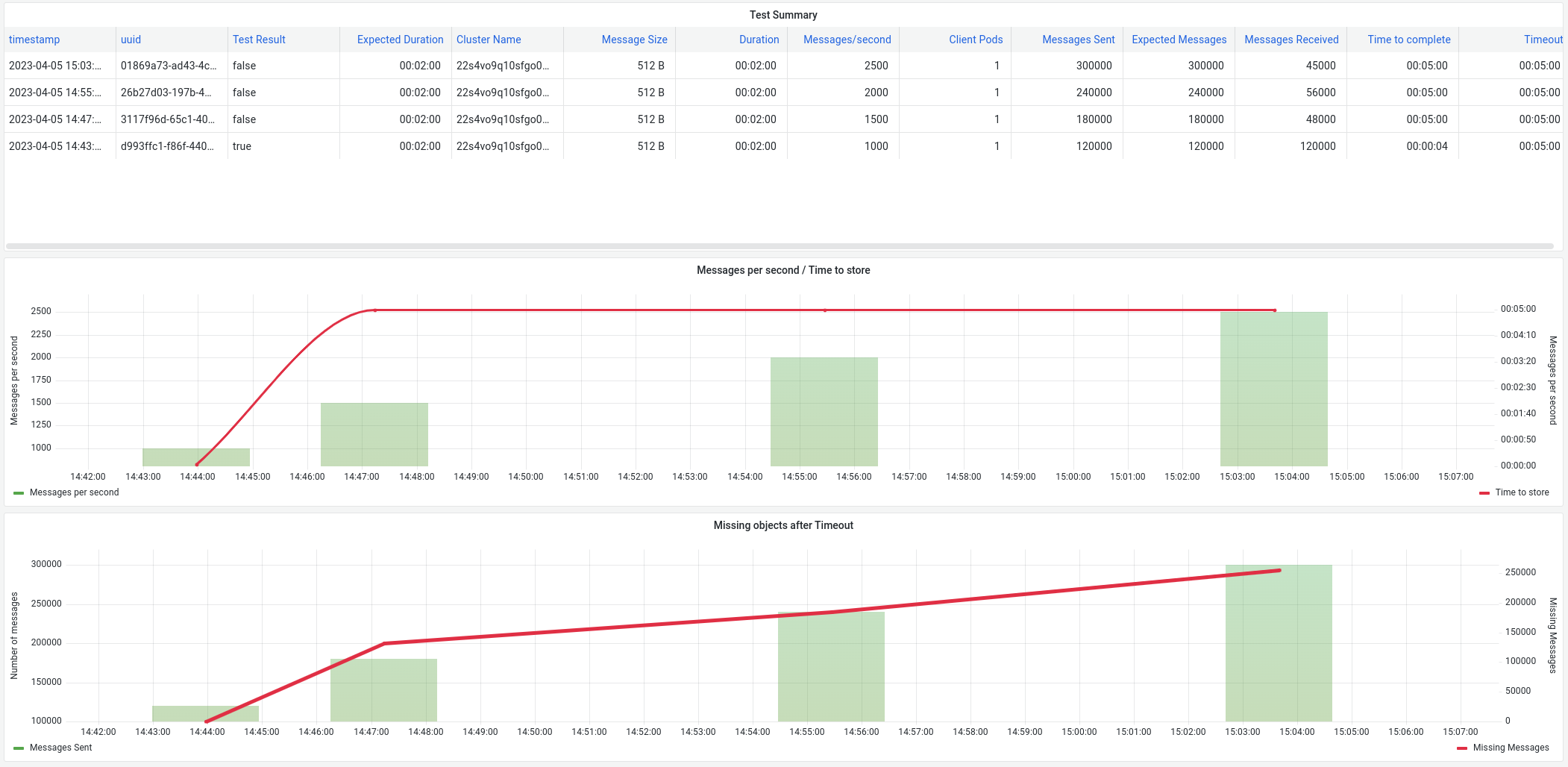
After that, any message is stored on ES, and it never recovers, we have execute follwing tests, where we can see that even decreasing the number of messages/second, if fails again
First value is sending 1000 msg/sec during 2 minutes, everything works and all messages are stored.
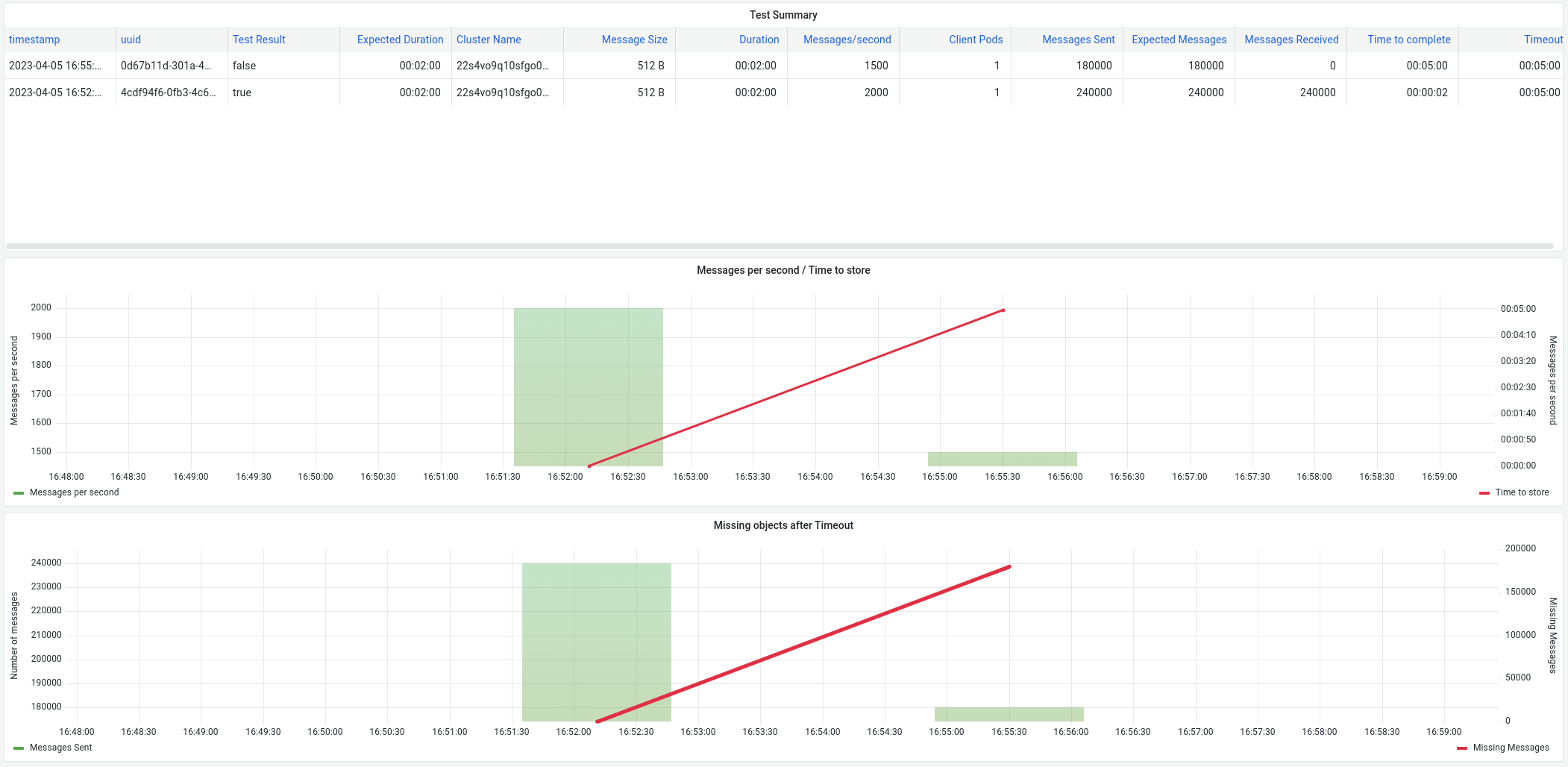
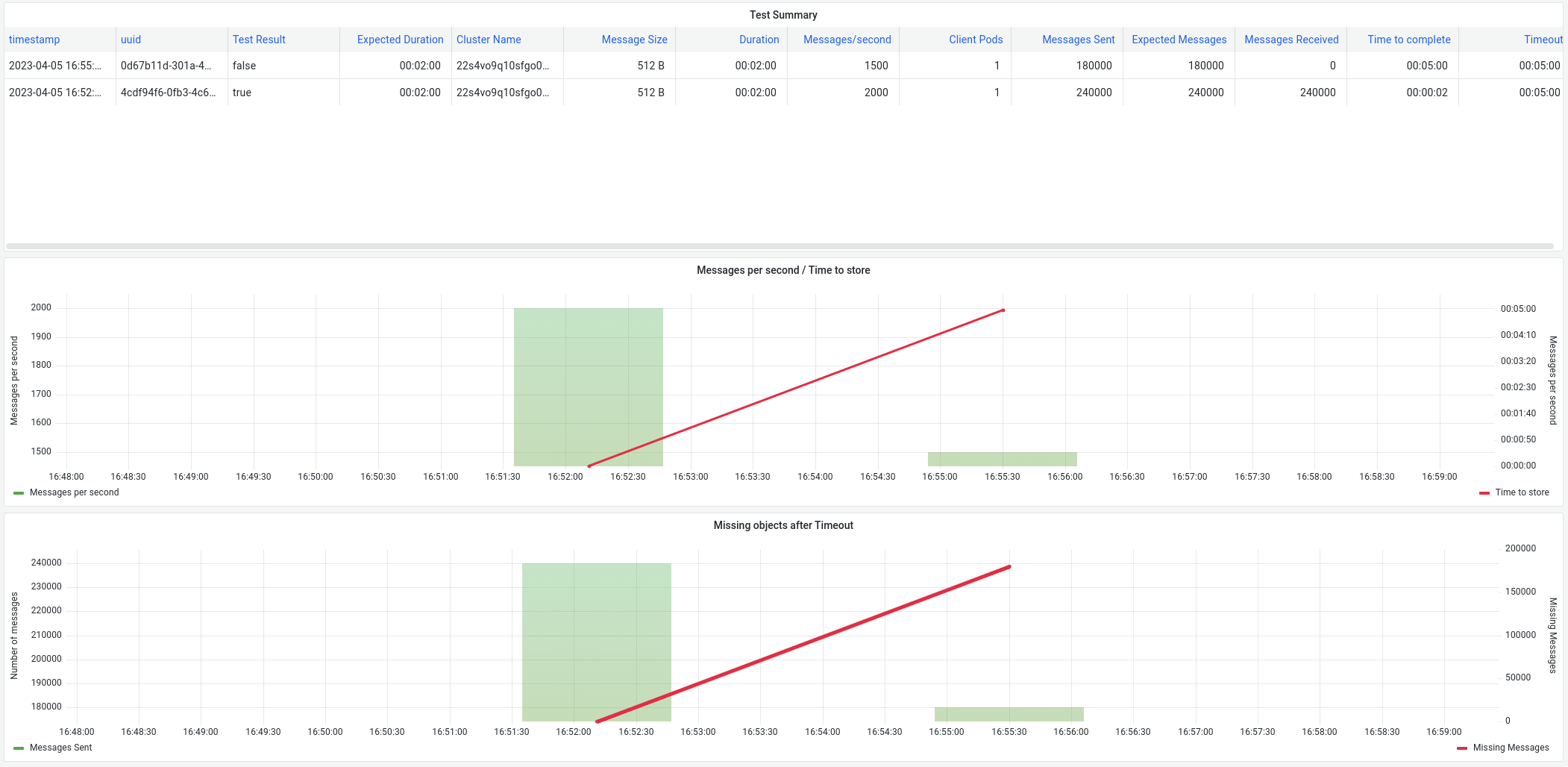
Second test is sending 1500 msg/sec during 2 minutes, we sent 180000 and we received 48000
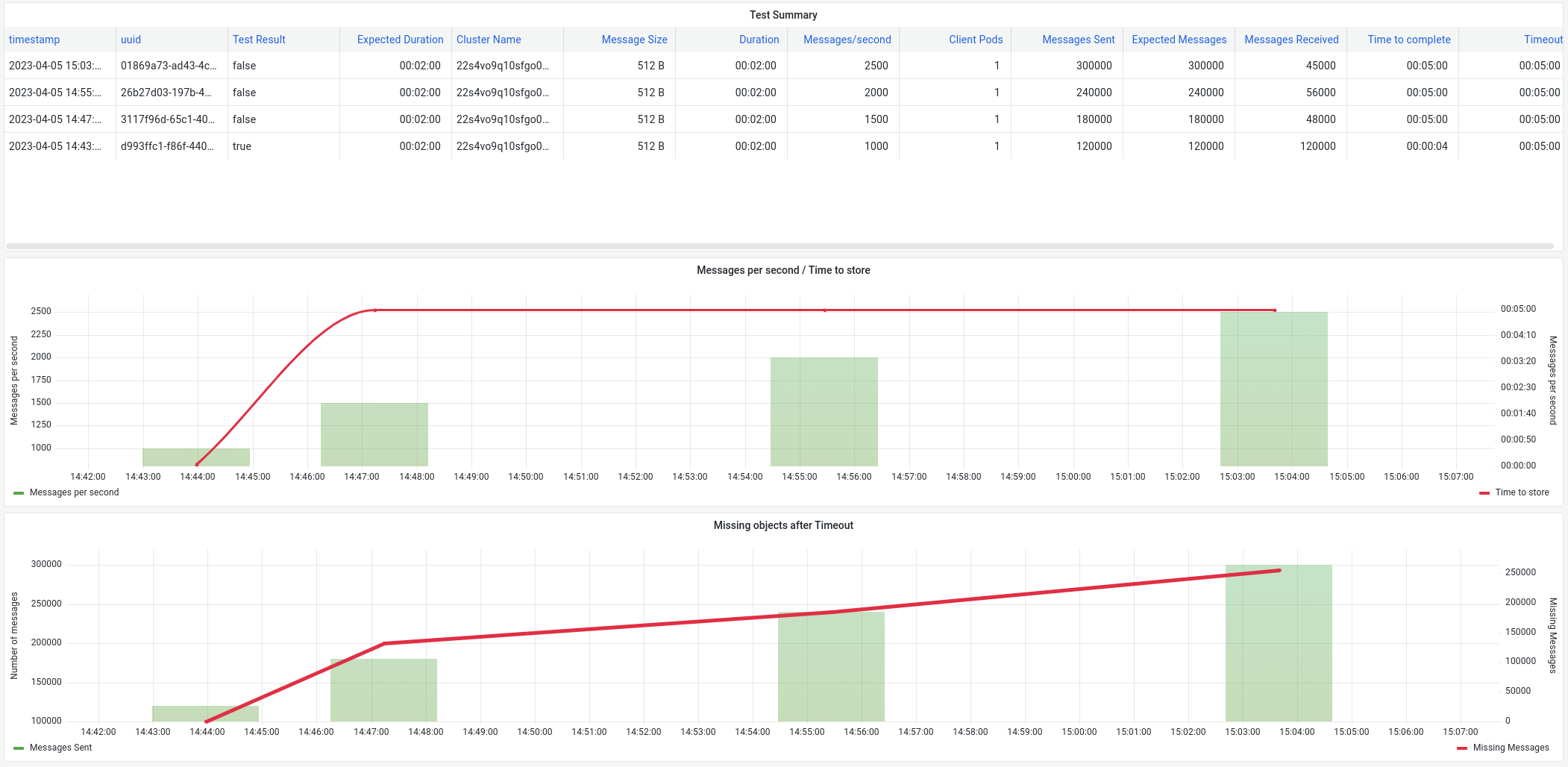
In this case, we sent 2000 messages/sec during 2 minutes (more than failed one on previous test) and receive all of them but after that, we sent 1500 and it failed