-
Bug
-
Resolution: Done
-
 Major
Major
-
None
-
False
-
-
False
-
NEW
-
VERIFIED
-
Before this update, alerting did not take into account multiple forward outputs. This update resolves the issue.
-
Logging (Core) - Sprint 219, Logging (Core) - Sprint 220
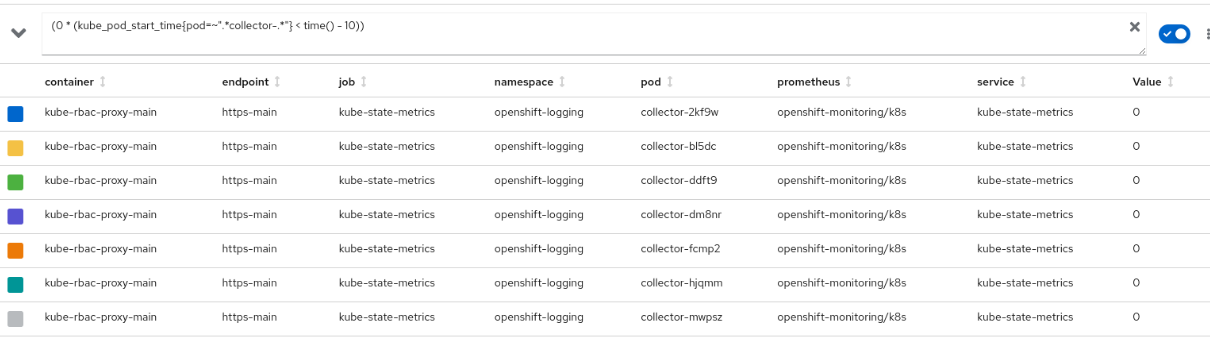
When there's more than one outputRef defined in ClusterLogForwarder, the rule FluentdQueueLengthIncreasing could fail to evaluate:
outputRefs:
- fmi-graylog
- default
then, we can see in prometheus logs:
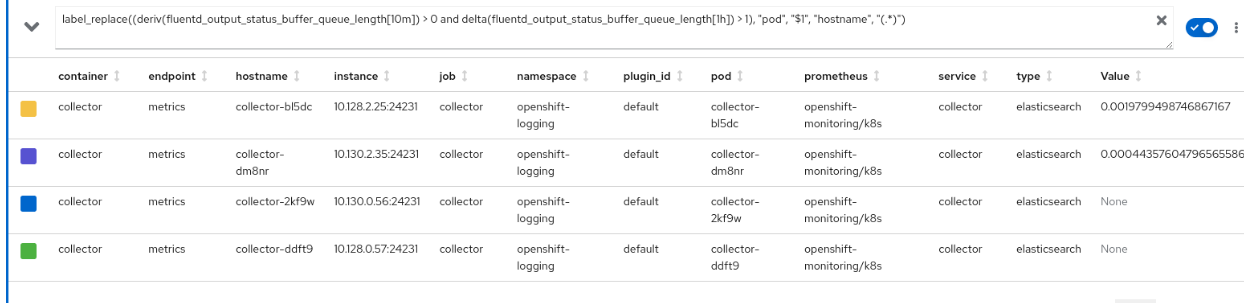
2022-04-27T13:07:30.544866833Z level=warn ts=2022-04-27T13:07:30.544Z caller=manager.go:603 component="rule manager" group=logging_fluentd.alerts msg="Evaluating rule failed" rule="alert: FluentdQueueLengthIncreasing\nexpr: (0 * (kube_pod_start_time{pod=~\".*fluentd.*\"} < time() - 3600)) + on(pod) label_replace((deriv(fluentd_output_status_buffer_queue_length[10m])\n > 0 and delta(fluentd_output_status_buffer_queue_length[1h]) > 1), \"pod\", \"$1\",\n \"hostname\", \"(.*)\")\nfor: 1h\nlabels:\n service: fluentd\n severity: error\nannotations:\n message: For the last hour, fluentd {{ $labels.instance }} average buffer queue\n length has increased continuously.\n summary: Fluentd unable to keep up with traffic over time.\n" err="found duplicate series for the match group {pod=\"collector-xxxxx\"} on the right hand-side of the operation: [{container=\"collector\", endpoint=\"metrics\", hostname=\"collector-xxxx\", instance=\"<ipaddress>:24231\", job=\"collector\", namespace=\"openshift-logging\", plugin_id=\"fmi_graylog\", pod=\"collector-xxxxx\", service=\"collector\", type=\"elasticsearch\"}, {container=\"collector\", endpoint=\"metrics\", hostname=\"collector-zntwr\", instance=\"<ipaddress>:24231\", job=\"collector\", namespace=\"openshift-logging\", plugin_id=\"default\", pod=\"collector-zntwr\", service=\"collector\", type=\"elasticsearch\"}];many-to-many matching not allowed: matching labels must be unique on one side"
So, we have these tuples:
{container=\"collector\", endpoint=\"metrics\", hostname=\"collector-sfzmg\", instance=\"<ipaddress>:24231\", job=\"collector\", namespace=\"openshift-logging\", plugin_id=\"fmi_graylog\", pod=\"collector-xxxx\", service=\"collector\", type=\"elasticsearch\"},
{container=\"collector\", endpoint=\"metrics\", hostname=\"collector-sfzmg\", instance=\"<ipaddress>:24231\", job=\"collector\", namespace=\"openshift-logging\", plugin_id=\"default\", pod=\"collector-xxxx\", service=\"collector\", type=\"elasticsearch\"}
There are two because of the "plugin_id" that is showing different in each tuple.

- clones
-
-
- Closed
-
- links to
- mentioned on
(2 mentioned on)

