-
Bug
-
Resolution: Done
-
 Major
Major
-
None
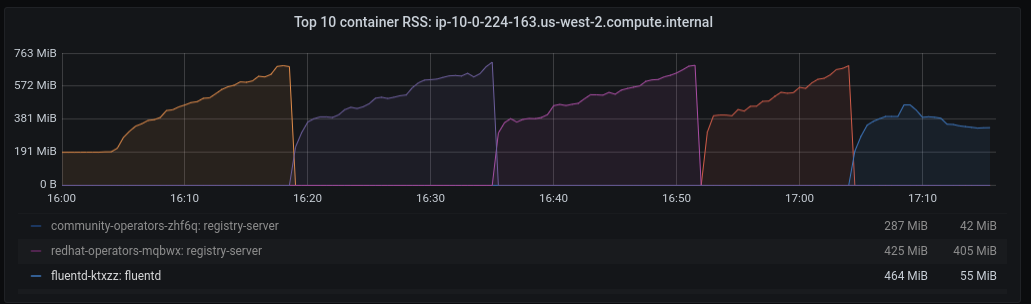
Running ROSA Cloudwatch Logging PerfScale tests per https://docs.google.com/document/d/10vv_SVC7fUammkvdn6-05bGrzdAtXxiJ_Z6QMzfUL4A/edit#
I am seeing fluentd OOM looping about every 15 minutes when running:
220 log-generator pods (on a single node) ; single container per pod
250 messages per minute per pod
512 byte message size
Snip from the fluentd pod describe
```
State: Running
Started: Tue, 02 Feb 2021 16:34:42 +0000
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Tue, 02 Feb 2021 16:18:32 +0000
Finished: Tue, 02 Feb 2021 16:34:38 +0000
Ready: True
Restart Count: 2
Limits:
memory: 736Mi
Requests:
cpu: 100m
memory: 736Mi
```
To replicate the issue (assumes a cluster with cluster logging addon installed):
Create log-generator namespace
Pick a worker node that has 220 pod space available (ie less than 30 pods are currently running on the host)
apply:
```
apiVersion: batch/v1
kind: Job
metadata:
name: log-generator
namespace: log-generator
spec:
parallelism: 110
completions: 110
template:
metadata:
labels:
name: log-generator
spec:
nodeSelector:
kubernetes.io/hostname: ip-10-0-224-163
containers:
- image: quay.io/dry923/log_generator
name: log-generator
command: ["/usr/bin/python3", "/log_generator.py"]
args: ["--size", "512", "--duration", "60", "--messages-per-minute", "250"]
imagePullPolicy: Never
restartPolicy: Never
```
sleep 30 seconds (the openshift QPS will cause image back offs if you try and deploy all 220 at once; you will still see some but they recover quickly)
apply
```
apiVersion: batch/v1
kind: Job
metadata:
name: log-generator2
namespace: log-generator
spec:
parallelism: 110
completions: 110
template:
metadata:
labels:
name: log-generator2
spec:
nodeSelector:
kubernetes.io/hostname: ip-10-0-224-163
containers:
- image: quay.io/dry923/log_generator
name: log-generator
command: ["/usr/bin/python3", "/log_generator.py"]
args: ["--size", "512", "--duration", "60", "--messages-per-minute", "250"]
imagePullPolicy: Never
restartPolicy: Never
```
CPU usage for this pod is ~80% and the memory climbs from ~350Mb to its cap over 15-20 minutes causing the pod to OOM