-
Bug
-
Resolution: Won't Do
-
 Blocker
Blocker
-
None
-
7.1.0.DR19
-
Regression
-
-
-
-
-
-
-
Customer Impact: Server can crash on OOME during long running execution. It's a regression against previous DRs and EAP 7.0.
There is OOME in one of the SOAK tests. OOME seems to be random as it was in 1 of 2 runs. SOAK is running complex test scenario with temporary queues, message selectors, core and JMS bridges, remote JCA and topics with durable subscription.
See 1st comment to download the heap dump, all logs, message journal, ...
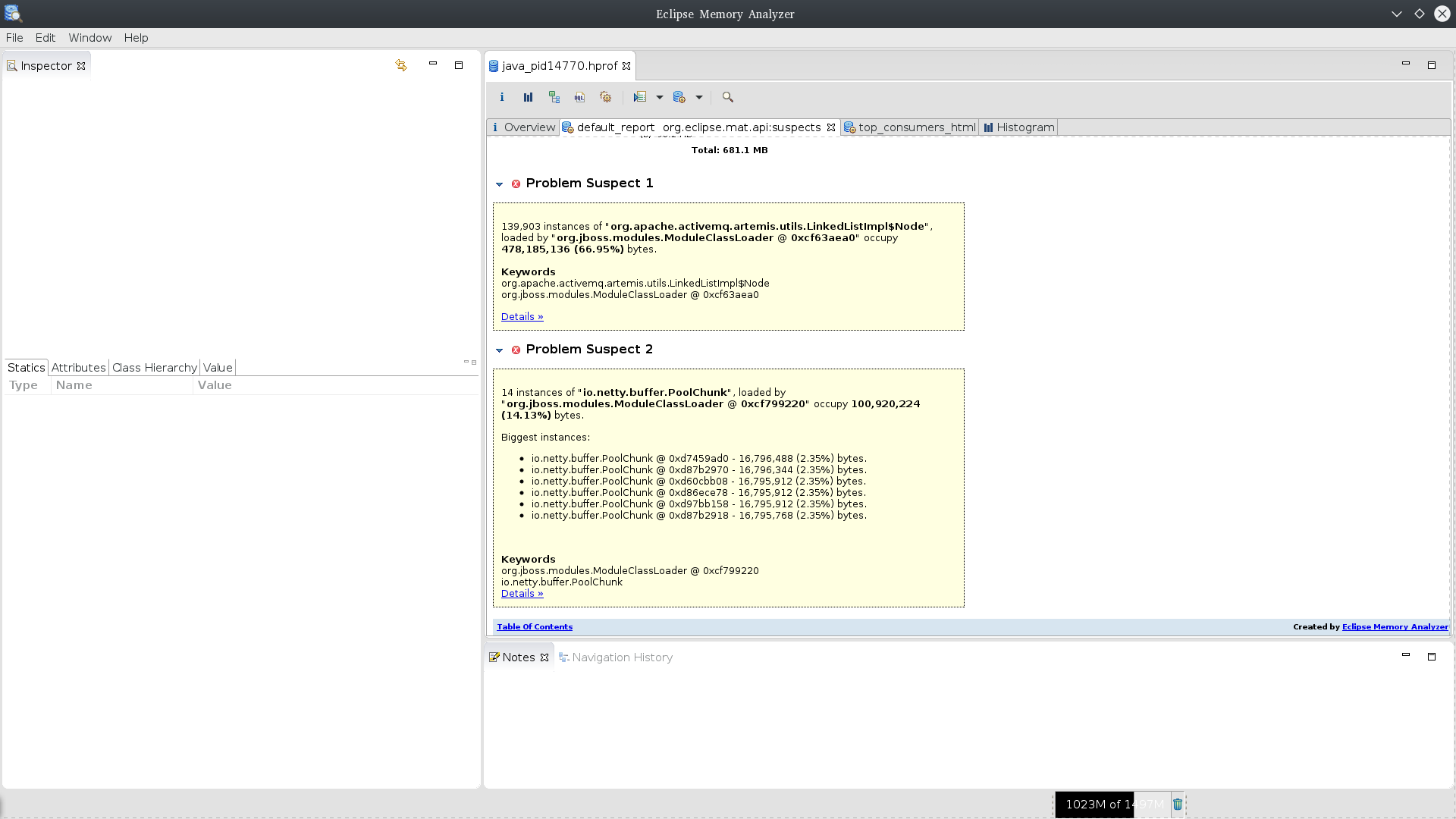
Eclipse memory analyzer shows 2 suspects for memory leak - see attachment. The 1st one seems to be responsible for OOME. There are 139,903 instances of org.apache.activemq.artemis.utils.LinkedListImpl$Node taking 456MB. Number of org.apache.activemq.artemis.utils.LinkedListImpl$Node instances seems to be equivalent to number of messages in journal for all destinations as they're references to messages.
Attaching all graphs (memory, cpu, gc statistics, ...) from SOAK. Interesting is mainly memory graph as it seems that OOME happened when not all heap memory was consumed.
It almost looks like that GC did not manage to free enough memory in time and last GC cycles took more time. (it's not so good visible from gc measurement graph but it's there) By looking at the way how instances in LinkedListImpl are removed, there is interesting thing:
private void removeAfter(Node<E> node) { Node<E> toRemove = node.next; ... //Help GC - otherwise GC potentially has to traverse a very long list to see if elements are reachable, this can result in OOM //https://jira.jboss.org/browse/HORNETQ-469 toRemove.next = toRemove.prev = null; }
There is chance that GC traversed over 100k instances to check whether there are references to some object in the list and it took a lot of time. In the mean time server crashed on OOME. But this is a theory.
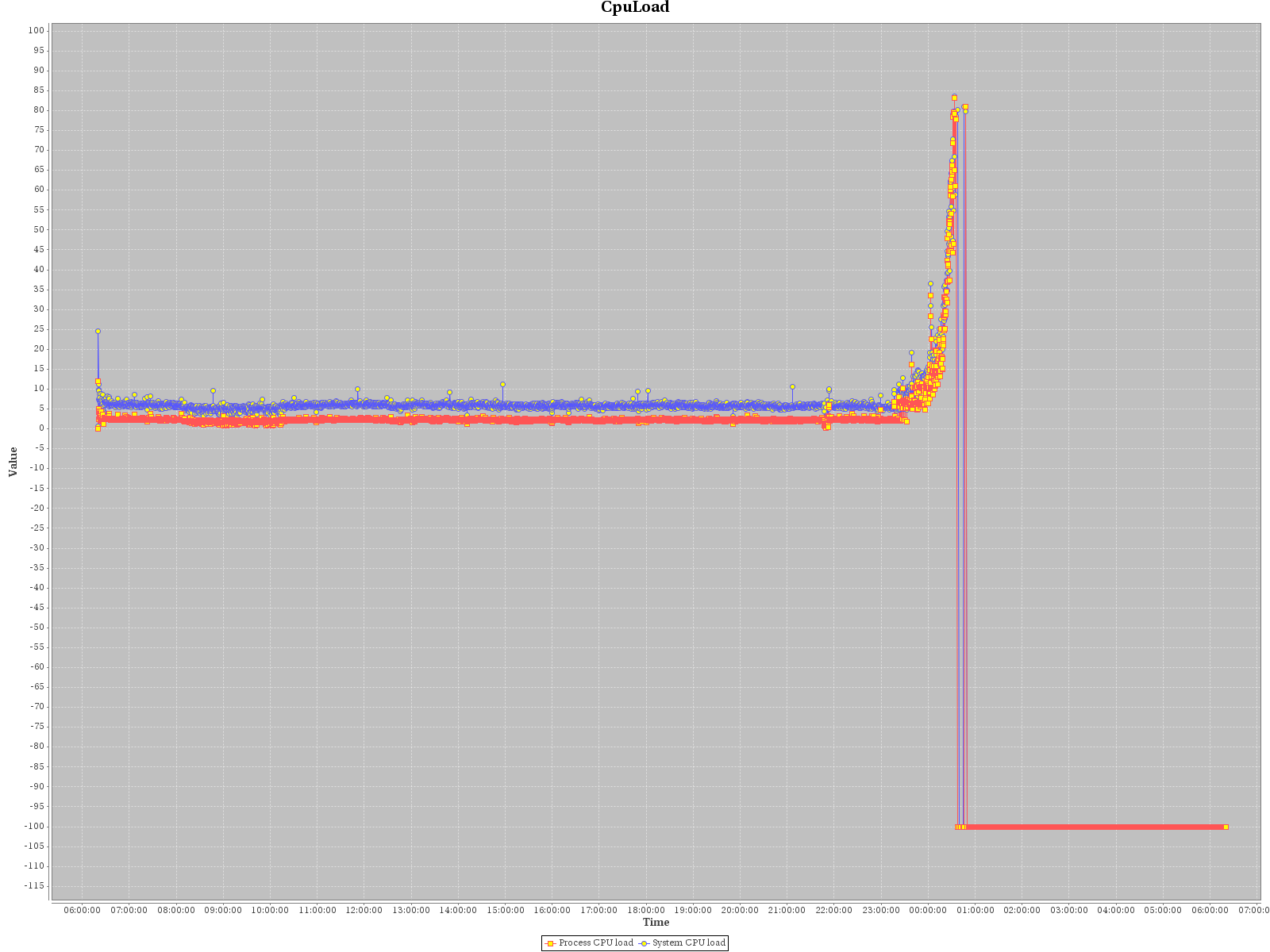
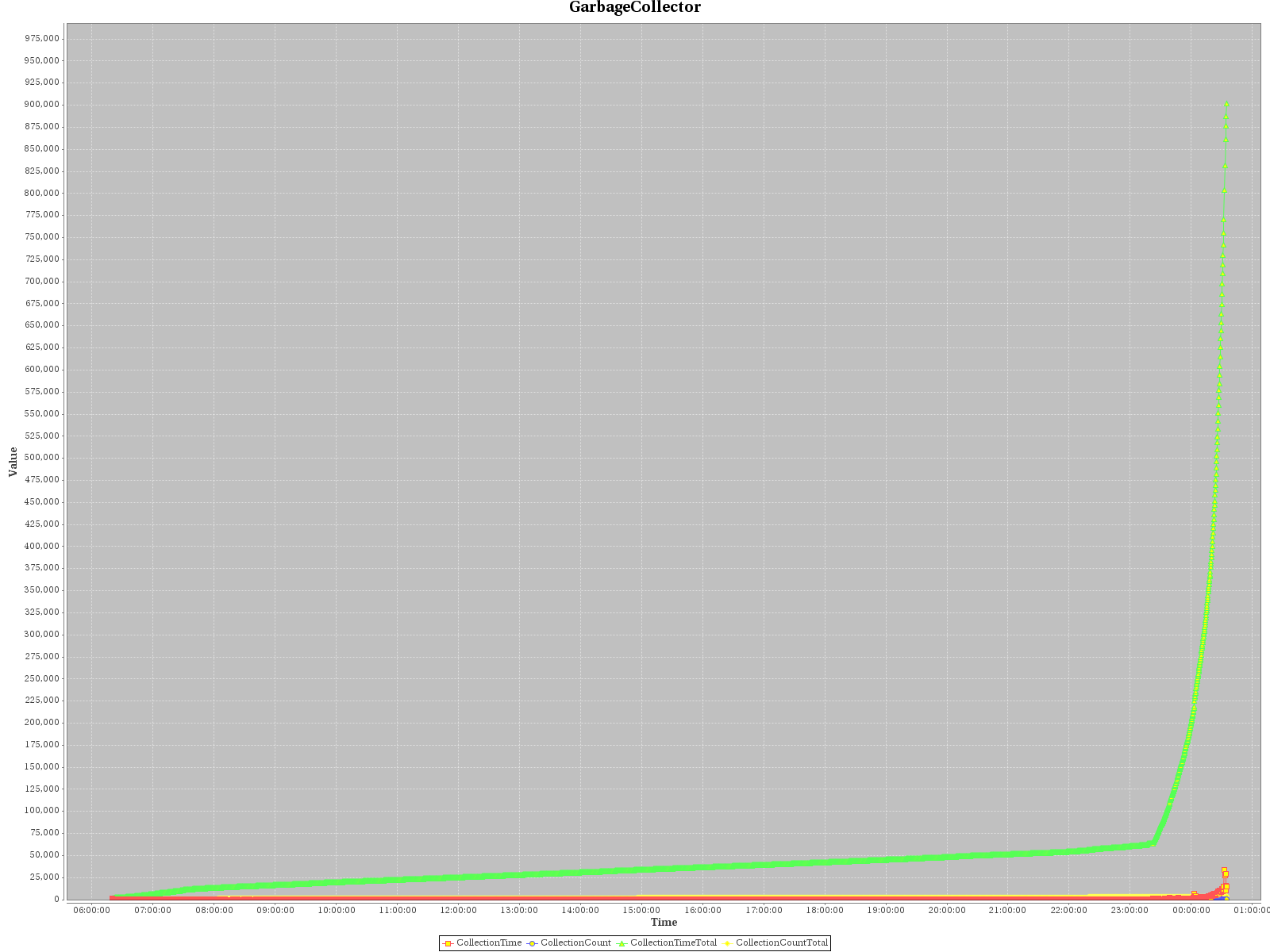
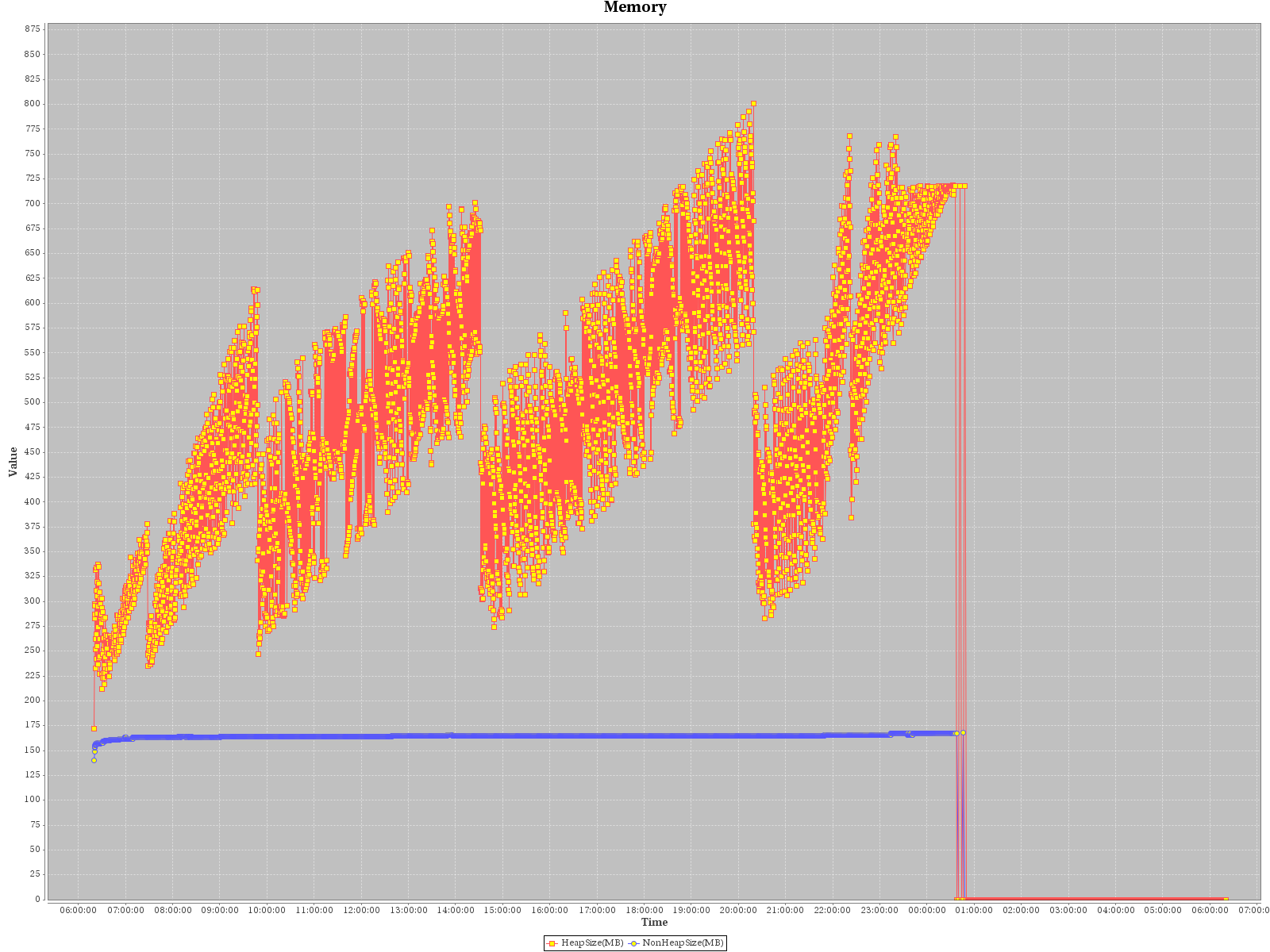

- is related to
-
-

- Closed
-
-
-
- Closed
-
