-
Bug
-
Resolution: Done
-
 Normal
Normal
-
None
-
None
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
Hypershift Sprint 236
-
None
-
None
-
None
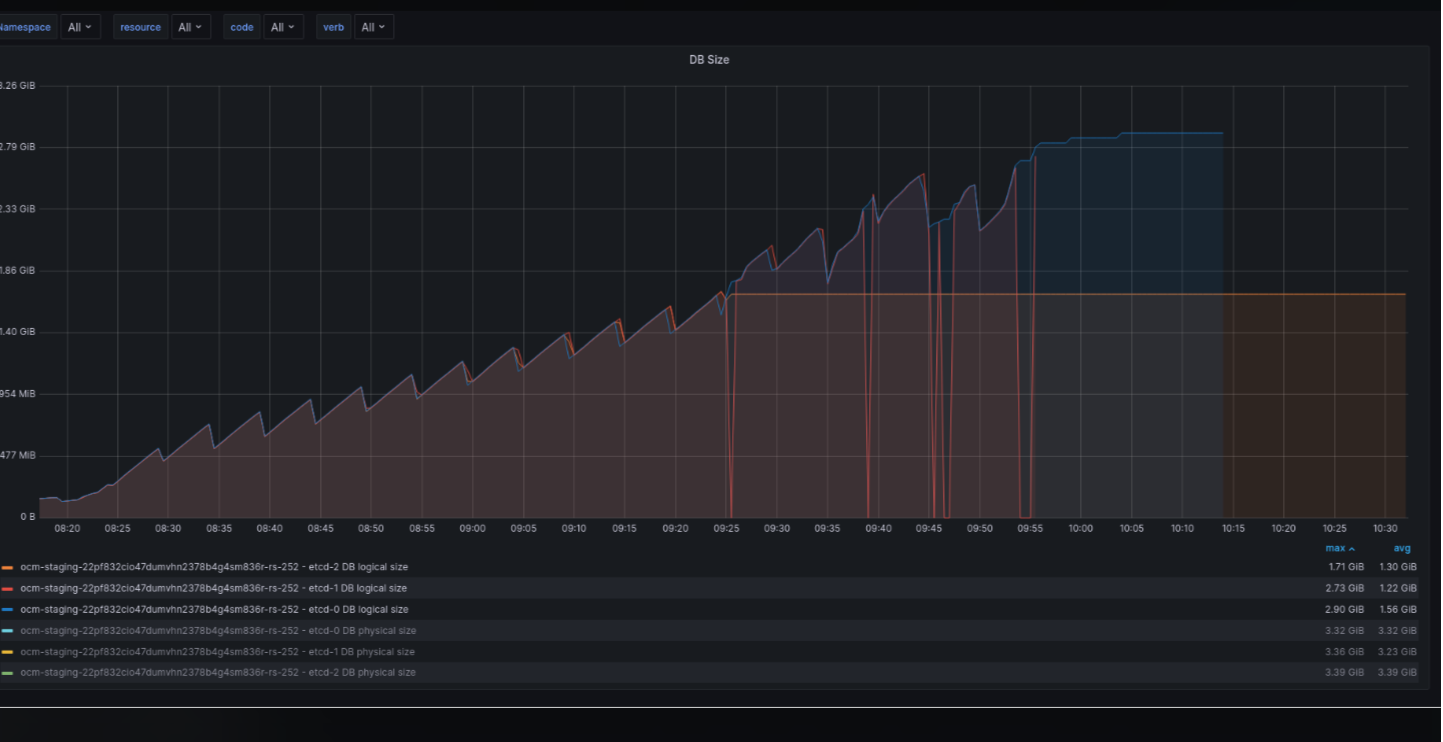
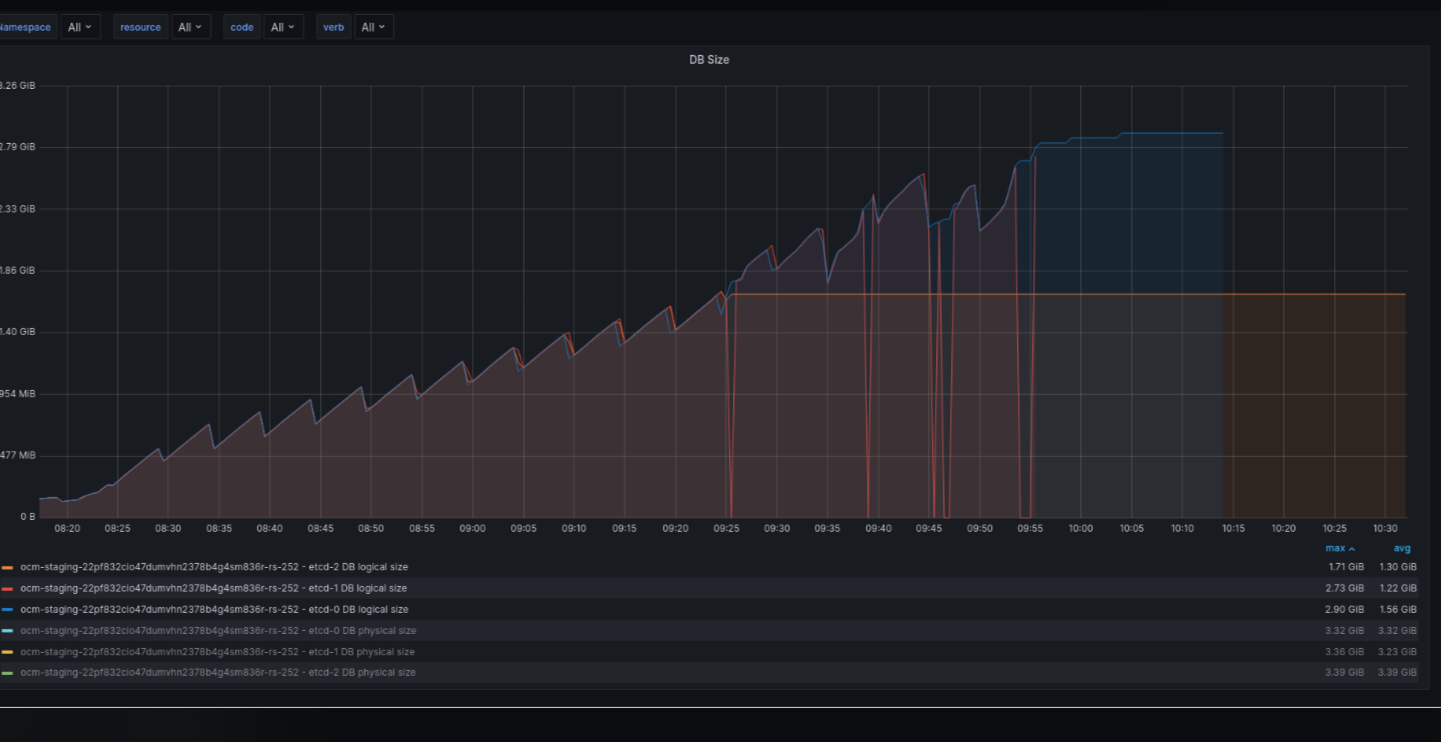
After running several scale tests on a large cluster (252 workers), etcd ran out of space and became unavailable.
These tests consisted of running our node-density workload (Creates more than 50k pause pods) and cluster-density 4k several times (creates 4k namespaces with https://github.com/cloud-bulldozer/e2e-benchmarking/tree/master/workloads/kube-burner#cluster-density-variables).
The actions above leaded etcd peers to run out of free space in their 4GiB PVCs presenting the following error trace
{"level":"warn","ts":"2023-03-31T09:50:57.532Z","caller":"rafthttp/http.go:271","msg":"failed to save incoming database snapshot","local-member-id":"b14198cd7f0eebf1","remote-snapshot-sender-id":"a4e894c3f4af1379","incoming-snapshot-index ":19490191,"error":"write /var/lib/data/member/snap/tmp774311312: no space left on device"}
Etcd uses 4GiB PVCs to store its data, which seems to be insufficient for this scenario. In addition, unlike not-hypershift clusters we're not applying any periodic database defragmentation (this is done by cluster-etcd-operator) that could lead to a higher database size
The graph below represents the metrics etcd_mvcc_db_total_size_in_bytes and etcd_mvcc_db_total_size_in_use_in_byte
- causes
-
OCPSTRAT-1701 Default to sufficient space for large etcd databases and other database operations
-
- Closed
-
- is cloned by
-
-
- Closed
-
- relates to
-
-

- Closed
-
- links to
- mentioned on
