-
Bug
-
Resolution: Done
-
 Critical
Critical
-
1.14.0
-
GitOps Crimson - Sprint 3264
Description of Problem:
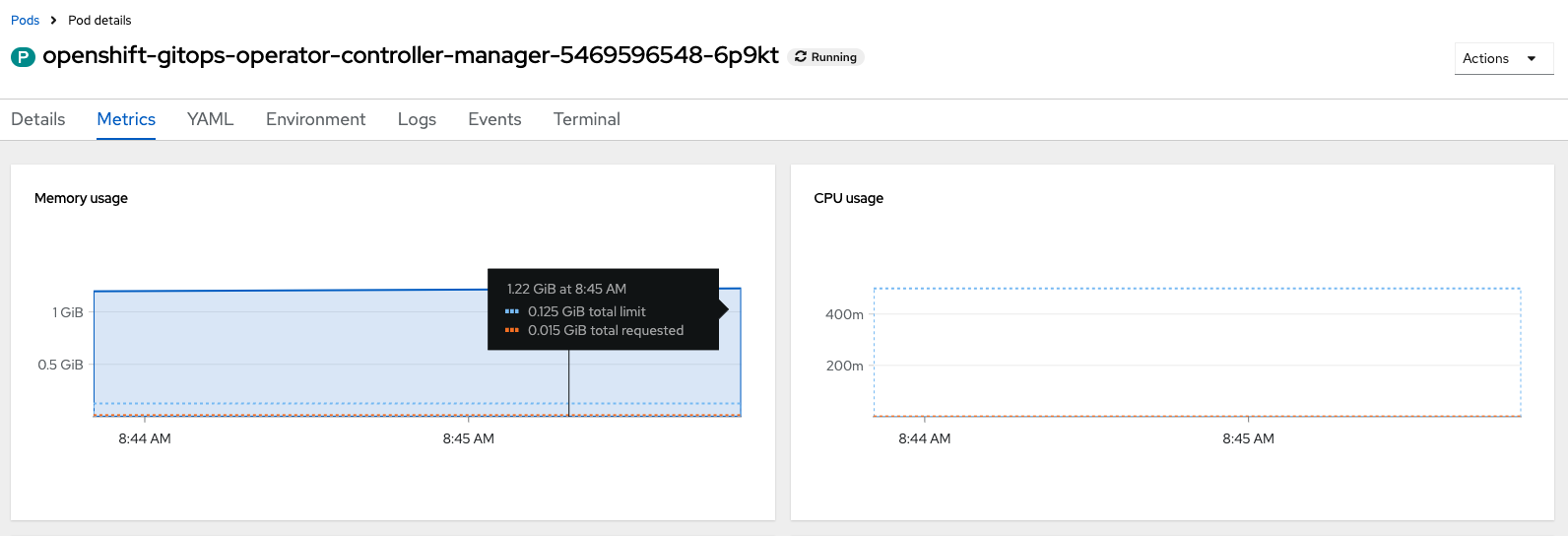
- High memory utilization of `openshift-gitops-operator-controller-manager` pod has been observed post upgrade to operator v 1.14.0
Additional Info:
- The "manager" container in the openshift-gitops-operator-controller-manager pod goes into CrashLoopBackOff state and have multiple restart count.
Prerequisites/Environment:
openshift-gitops-operator v 1.14.0
Following is the example of the status of the manager container:
Containers: manager: Container ID: cri-o:// Image: registry.redhat.io/openshift-gitops-1/gitops-rhel8-operator@sha256: Image ID: registry.redhat.io/openshift-gitops-1/gitops-rhel8-operator@sha256: Port: 9443/TCP Host Port: 0/TCP Command: /usr/local/bin/manager Args: --health-probe-bind-address=:8081 --metrics-bind-address=127.0.0.1:8080 --leader-elect State: Waiting Reason: CrashLoopBackOff Last State: Terminated Reason: OOMKilled Exit Code: 137
Expected Results:
The containers under "openshift-gitops-operator-controller-manager" pod should run successfully without modifying/updating the memory limit.
Actual Results:
The manager container in "openshift-gitops-operator-controller-manager" pod goes into CrashLoopBackOff state.
Workaround (If Possible)
Currently increasing the memory from the CSV helps bring the "openshift-gitops-operator-controller-manager" pod and its containers into optimal state.

- split to
-
GITOPS-5673 Investigate ways to reduce Operator memory consumption
-

- Closed
-
- links to
-
 RHBA-2024:139668
Errata Advisory for Red Hat OpenShift GitOps v1.14.1
RHBA-2024:139668
Errata Advisory for Red Hat OpenShift GitOps v1.14.1
- mentioned on
