-
Story
-
Resolution: Unresolved
-
 Major
Major
-
None
-
None
-
Future Sustainability
-
False
-
-
False
-
None
-
None
-
None
-
None
-
None
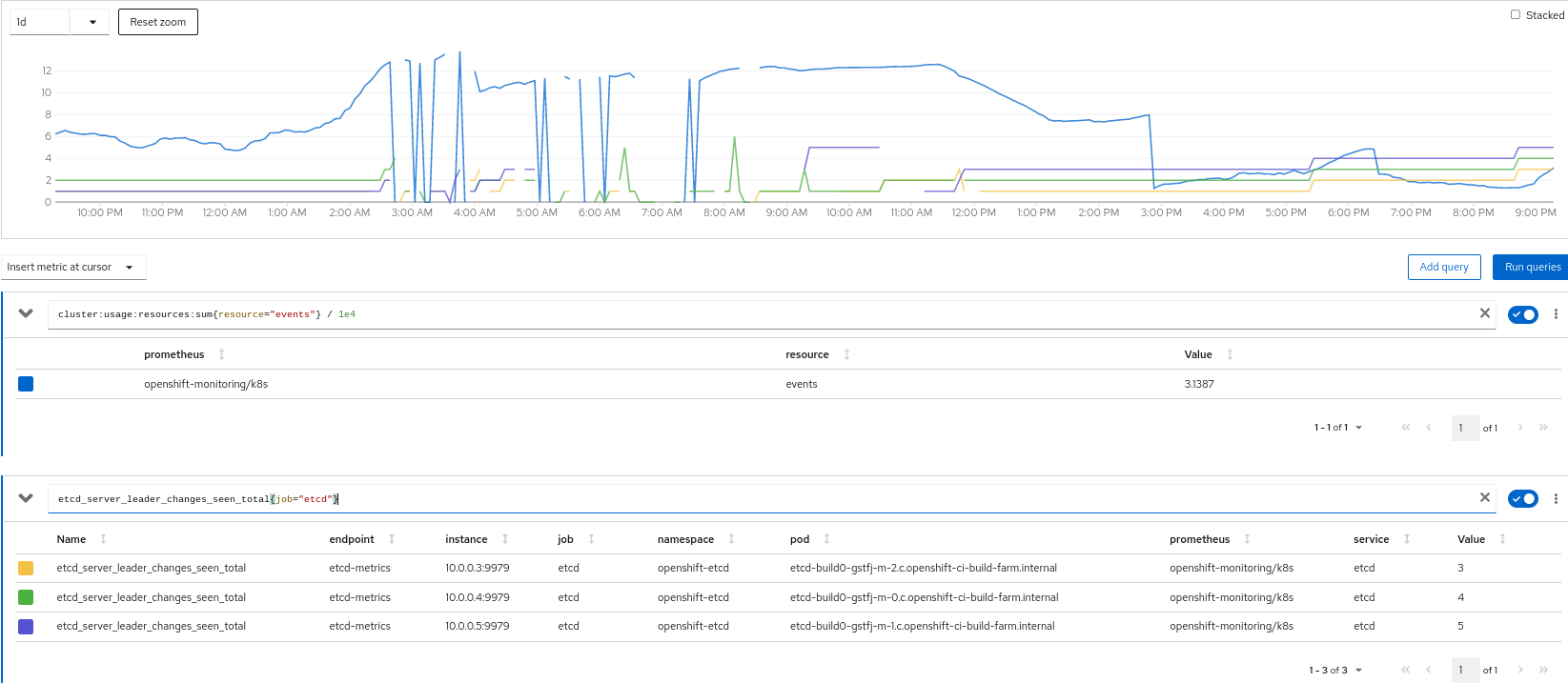
etcd#13294 points out that time-to-live clocks currently reset on leader elections (I think?). That can lead to difficulties during Event-spew incidents, with situations like:
1. Some initial trigger destabilizes etcd, and causes a leader election.
2. Events continue to flow in, because often etcd instability is correlated with a bunch of cluster components complaining about surprising things.
3. Reset TTL means etcd is no longer reaping expired Events.
4. Two hours in, we're up to ~1.6 times the events we should have, with a two our chunk of old events that should have been expired, but which the TTL reset leaves unreaped.
5. Large numbers of events lead to high resource consumption in clients that LIST events, or which are populating Event informers, etc.
6. High resource consumption destabilizes etcd, and we have a new leader election.
7. Return to step 1, but now with more old, unreaped Events in the backlog.
and so forth, until the old, unreaped Events are a huge drag on the system and it melts down.
There are a number of places where we could defend against this Event-spew scenario, but one on the etcd side would be setting --experimental-enable-lease-checkpoint near where we currently set --experimental-initial-corrupt-check (here and similar). This ticket is about figuring out whether we want to do that.
- relates to
-
-

- Closed
-