Details
-
Task
-
Resolution: Not a Bug
-
 Major
Major
-
None
-
7.45.0.Final
-
None
-
2020 Week 46-48 (from Nov 9)
-
Undefined
-
NEW
-
NEW
-
---
-
---
Description
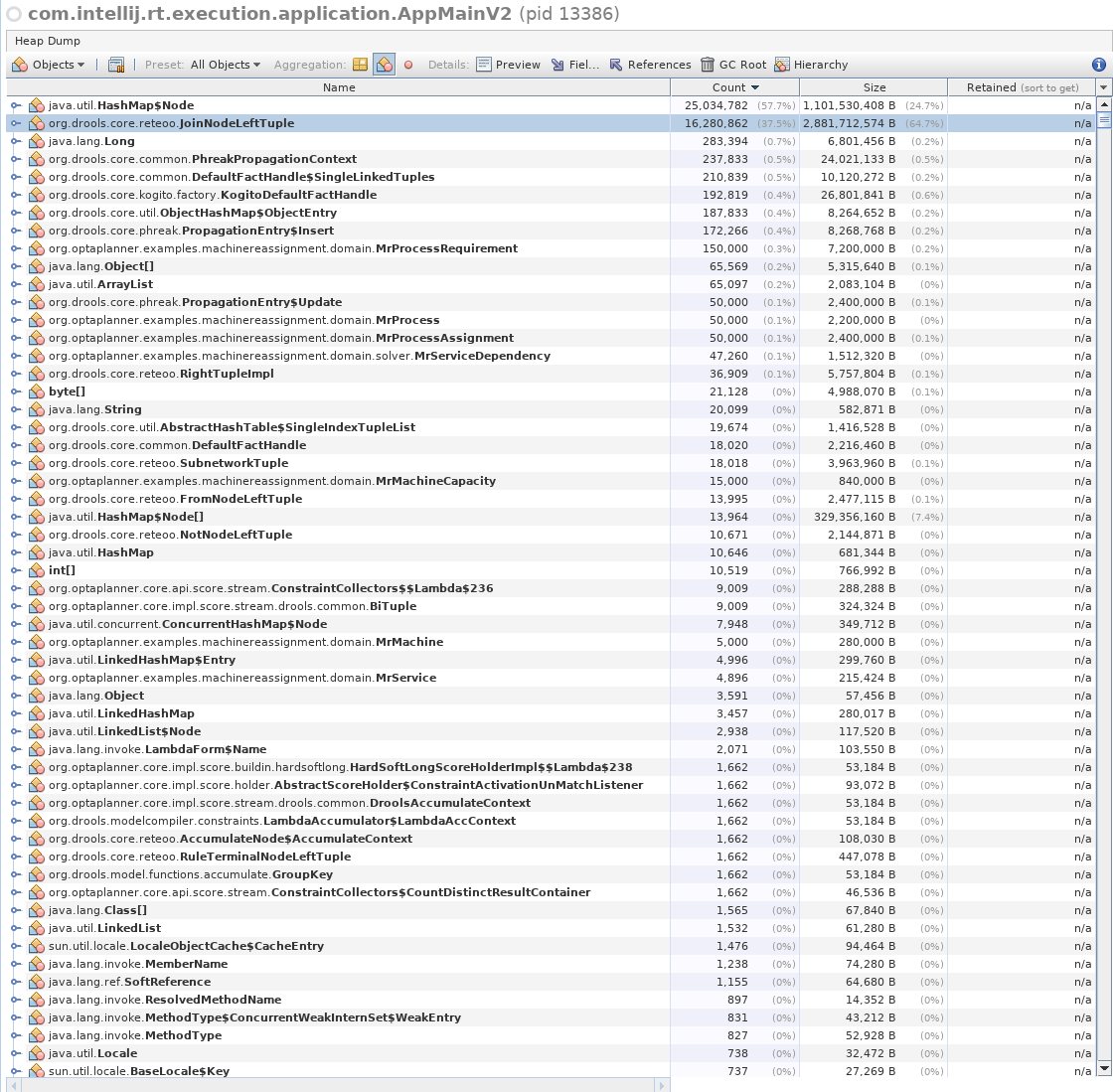
Please see the attached JMH benchmark. The source code has helpful comments.
In short:
- With problem size of 100, the performance is 6 operations per second.
- With 10_000, the performance goes to 0,06 operations per second.
- WIth 50_000, which is the full size of the problem, the benchmark crashes. Possibly due to being out of 8G of heap.
The scaling appears to be linear, which is good. But the overall throughput is the problem.
It is possible that there is no performance bottleneck - that groupBy is simply not efficient enough "by design". This issue would then turn into an enhancement request and a lengthy discussion would be necessary if there's anything that can be done about it.
My apologies for not making the benchmark a Git repo. The data set has 50 MB, which I didn't want to push into Git.