-
Bug
-
Resolution: Obsolete
-
 Major
Major
-
3.1.0.Final
-
False
-
-
False
-
Moderate
In order to make your issue reports as actionable as possible, please provide the following information, depending on the issue type.
Bug report
For bug reports, provide this information, please:
What Debezium connector do you use and what version?
MySQL Connector, version v3.0.8.Final and later versions [Issue still exists in latest version because it has not been addressed.]
What is the connector configuration?
Any MySQL connector configuration that performs initial snapshots, particularly when:
- Large tables are being snapshotted
- Network connectivity to Kafka broker is unstable
- Consumer applications may disconnect during snapshot operations
- High volume snapshot operations that may trigger queue buffering
What is the captured database version and mode of deployment?
MySQL 8.0+ (any version)
Deployment mode: Any (on-premises, cloud providers like AWS RDS, GCP Cloud SQL, Azure Database for MySQL)
What behavior do you expect?
When a MySQL connector task is stopped or fails during a snapshot operation:
- The task should shut down gracefully within a reasonable time (< 30 seconds)
- All coordinator threads should be properly cleaned up
- Memory should be released without accumulation or leaks
- Buffered snapshot records should be handled gracefully without causing indefinite blocking
- Subsequent connector restarts should work normally without memory pressure
What behavior do you see?
- Memory Accumulation: Coordinator threads get stuck indefinitely when trying to flush buffered snapshot records
- Thread Leaks: Snapshot cleanup threads remain blocked and never terminate, holding memory references
- Indefinite Blocking: The modifyAndFlushLastRecord method blocks forever when the consumer queue is full and no consumer is available
- Resource Exhaustion: Over time, multiple failed snapshot attempts lead to accumulated memory usage and thread pool exhaustion
- Delayed Shutdown: Task shutdown can take extremely long or never complete when coordinator threads are stuck
Specific symptoms:
- Connector tasks that never finish shutting down
- Memory usage that continues to grow after task failures
- Thread dumps showing blocked threads in ChangeEventQueue.doEnqueue() and MySqlChangeEventSourceFactory.modifyAndFlushLastRecord()
- OutOfMemoryError in environments with repeated snapshot failures
Do you see the same behaviour using the latest released Debezium version?
Yes, this issue exists in Debezium v3.0.8.Final and affects all subsequent versions that don't include the proposed fix. The issue is particularly prevalent in production environments with:
- Intermittent network connectivity
- Large snapshot operations
- High-availability setups where consumer applications may restart frequently
Do you have the connector logs, ideally from start till finish?
(You might be asked later to provide DEBUG/TRACE level log)
Typical log patterns showing the issue:
[Coordinator thread] DEBUG - Attempting to flush buffered record during snapshot cleanup [Coordinator thread] WARN - Flush attempt timed out, coordinator thread may be stuck [Task shutdown] INFO - Stopping MySQL connector task [Task shutdown] WARN - Task shutdown taking longer than expected, coordinator threads may be blocked
How to reproduce the issue using our tutorial deployment?
- Setup: Use the standard Debezium MySQL tutorial setup with a database containing large tables
- Configure: Set up MySQL connector with initial snapshot mode
- Trigger: Start the connector to begin initial snapshot of large tables
- Simulate failure: During snapshot operation, either:
- Stop the Kafka Connect worker abruptly
- Disconnect the consumer application
- Fill up the Kafka topic to cause backpressure
- Introduce network latency/disconnection to Kafka broker
- Observe: Monitor memory usage and thread counts during and after the failure
- Verify: Attempt to restart the connector and observe memory accumulation over multiple failure cycles
Root Cause Analysis:
- Simple Blocking Flush: The original modifyAndFlushLastRecord method had a simple implementation:
private void modifyAndFlushLastRecord(Function<SourceRecord, SourceRecord> modify) throws InterruptedException { queue.flushBuffer(dataChange -> new DataChangeEvent(modify.apply(dataChange.getRecord()))); queue.disableBuffering(); }
- No Queue Shutdown: The ChangeEventQueue had no mechanism to signal shutdown to waiting threads.
- No Coordinated Shutdown: The MySqlConnectorTask.doStop() method did not coordinate with the queue to unblock waiting threads.
Feature request or enhancement (Bug Fix)
For feature requests or enhancements, provide this information, please:
Which use case/requirement will be addressed by the proposed feature?
This enhancement addresses critical production reliability requirements:
- High Availability Operations: Ensures MySQL connectors can handle broker outages and consumer failures gracefully without memory leaks
- Resource Management: Prevents memory accumulation that can lead to OutOfMemoryError in production environments
- Operational Stability: Enables reliable connector lifecycle management with predictable shutdown behavior
- Scalability: Supports large-scale deployments where snapshot operations are frequent and failures are expected
- Production Resilience: Improves connector robustness in unstable network environments or high-load scenarios
Implementation ideas (optional)
- Queue Shutdown Mechanism: Add a shutdown() method to ChangeEventQueue that signals waiting threads to unblock gracefully
- Enhanced Snapshot Cleanup: Improve modifyAndFlushLastRecord() in MySqlChangeEventSourceFactory to handle interruptions and use the queue shutdown signal
- Coordinated Task Shutdown: Modify MySqlConnectorTask.doStop() to trigger queue shutdown early in the shutdown process
Testing of the proposed implementation
The proposed implementation above was tested locally, under following conditions:
Database in picture: A 200 row, 10MB each row data. [DELIBERATE SELECTION OF TABLE SIZE TO REPRO THE ISSUE]
Cluster: Standard
Task Failing Cause: Due to standard cluster max.request.size is 8388698, so task was failing with
WorkerSourceTask{id=lcc-devckv61v2-0} Task threw an uncaught and unrecoverable exception. Task is being killed and will not recover until manually restartedorg.apache.kafka.connect.errors.ConnectException: Unrecoverable exception from producer send callback at org.apache.kafka.connect.runtime.WorkerSourceTask.maybeThrowProducerSendException(WorkerSourceTask.java:343) at org.apache.kafka.connect.runtime.WorkerSourceTask.prepareToSendRecord(WorkerSourceTask.java:135) at org.apache.kafka.connect.runtime.AbstractWorkerSourceTask.sendRecords(AbstractWorkerSourceTask.java:445) at org.apache.kafka.connect.runtime.AbstractWorkerSourceTask.execute(AbstractWorkerSourceTask.java:391) at org.apache.kafka.connect.runtime.WorkerTask.doRun(WorkerTask.java:272) at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:328) at org.apache.kafka.connect.runtime.AbstractWorkerSourceTask.run(AbstractWorkerSourceTask.java:88) at org.apache.kafka.connect.runtime.isolation.Plugins.lambda$withClassLoader$7(Plugins.java:341) at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:572) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:317) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642) at java.base/java.lang.Thread.run(Thread.java:1583)Caused by: org.apache.kafka.common.errors.RecordTooLargeException: The message is 13981496 bytes when serialized which is larger than 8388698, which is the value of the max.request.size configuration.
Timeline of events
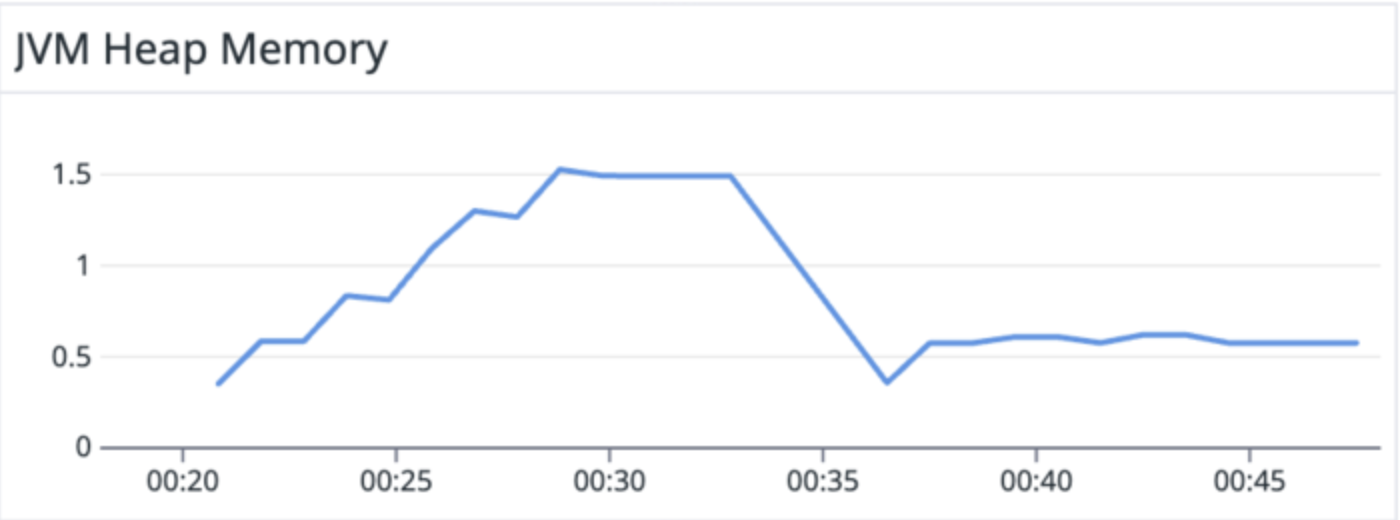
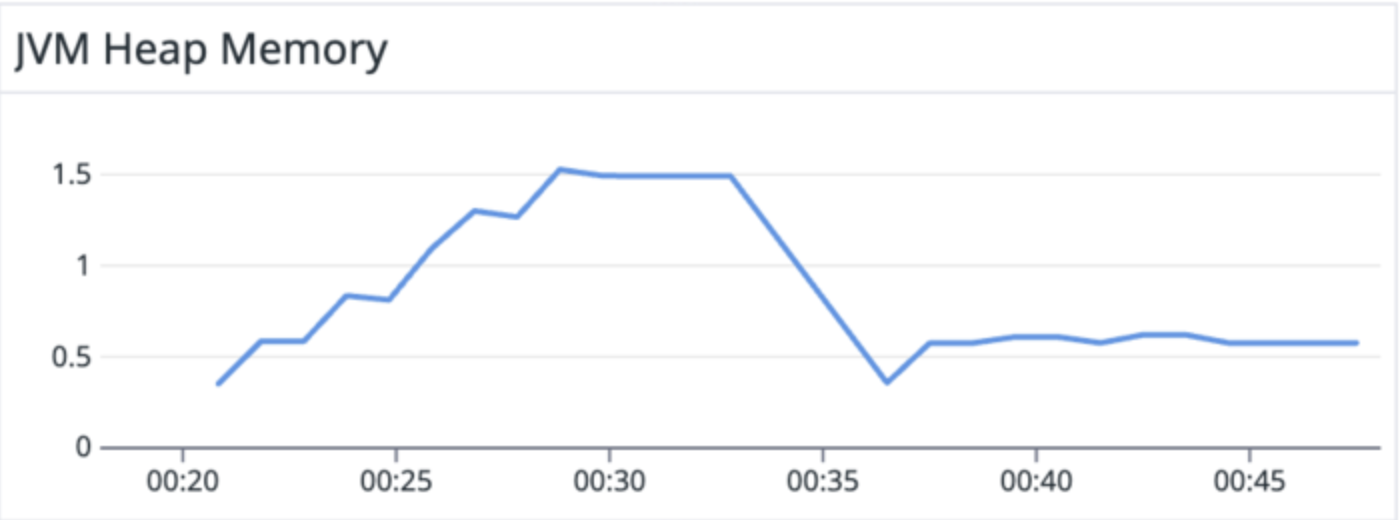
00:20 - 0:28 → Connector configured running on existing v3.0.8.Final image
00:28 → Connector deleted
00:34 → Connect pod restarted with new image (one with above changes on top of 3.0.8)
00:35 → New Connector configured with same config
Observation
On older image, at each task failure, older memory was not getting free, as we can see a step pattern in first half of the above image.
On the newer image (our fix), at each task failure, older memory was getting free, as we observe a near flatline.
Restarts in both instances of connectors were more or less same as observed from logs.