-
Enhancement
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
False
-
-
False
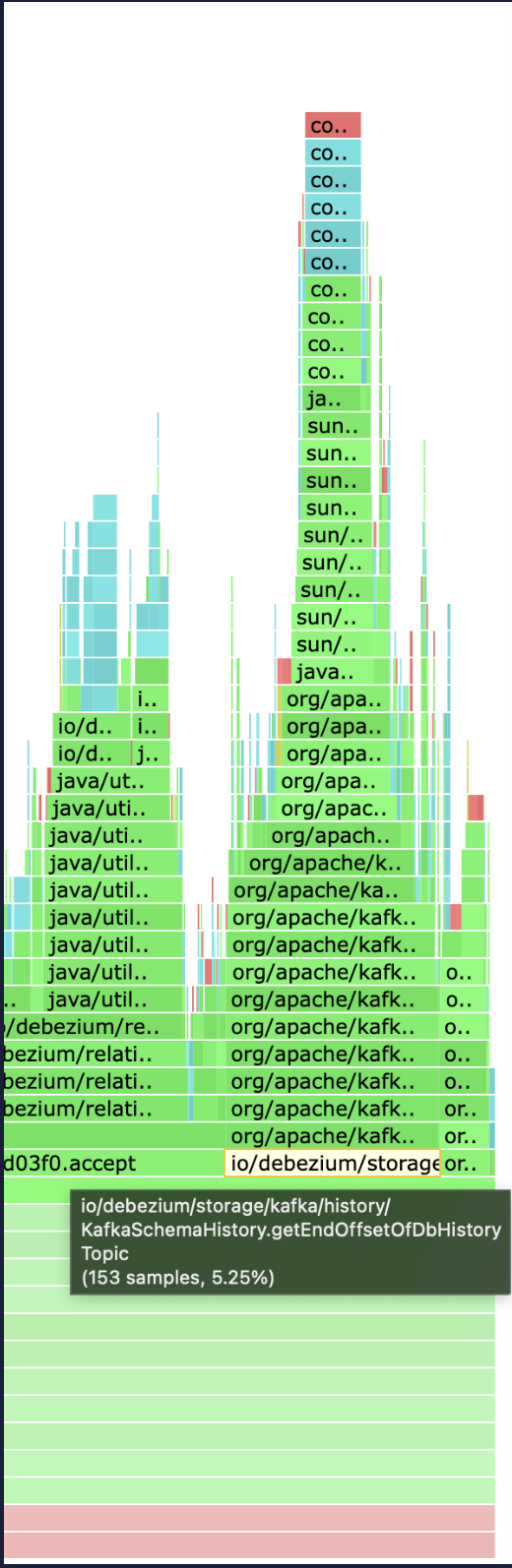
The recover function in KafkaSchemaHistory does the below in loop.
- checks the end offset, compares with last seen end offset and prints a warn log in case these are different
- polls topic for data and processes that data
Steps 1 and 2, both are executed in every iteration. Step 2, is the core recovery process, however step1 is an attempt to detect cases where the history topic is being shared amongst multiple connectors. On checking CPU profile in one of the cases where history recovery was in progress for a long history topic, i saw that CPU spent in step1 was more than step2.
To fix this and save some CPU cycles, we should not do step1 in every iteration. The CPU profile observed by me are attached.


- is related to
-
DBZ-4959 Improve performance of DB history recovery
-
- Closed
-
- links to
-
 RHEA-2025:154266
Red Hat build of Debezium 3.2.4 release
RHEA-2025:154266
Red Hat build of Debezium 3.2.4 release