-
Bug
-
Resolution: Done
-
 Critical
Critical
-
0.8.1.Final
-
Oracle Java java 1.8.0_171
Kafka 2.0.0
Debezium Connector Postgres 0.8.1.Final
RDS PostgreSQL 9.6.8Connector config
name=debezium-db-unstable connector.class=io.debezium.connector.postgresql.PostgresConnector tasks.max=1 database.hostname=postgres-hostname.com database.port=5432 database.user=root database.dbname=unstable database.server.name=unstable table.whitelist=schema.tablename plugin.name=wal2json_rds snapshot.mode=never slot.name=debezium_unstable
Oracle Java java 1.8.0_171 Kafka 2.0.0 Debezium Connector Postgres 0.8.1.Final RDS PostgreSQL 9.6.8 Connector config name=debezium-db-unstable connector.class=io.debezium.connector.postgresql.PostgresConnector tasks.max=1 database.hostname=postgres-hostname.com database.port=5432 database.user=root database.dbname=unstable database.server.name=unstable table.whitelist=schema.tablename plugin.name=wal2json_rds snapshot.mode=never slot.name=debezium_unstable
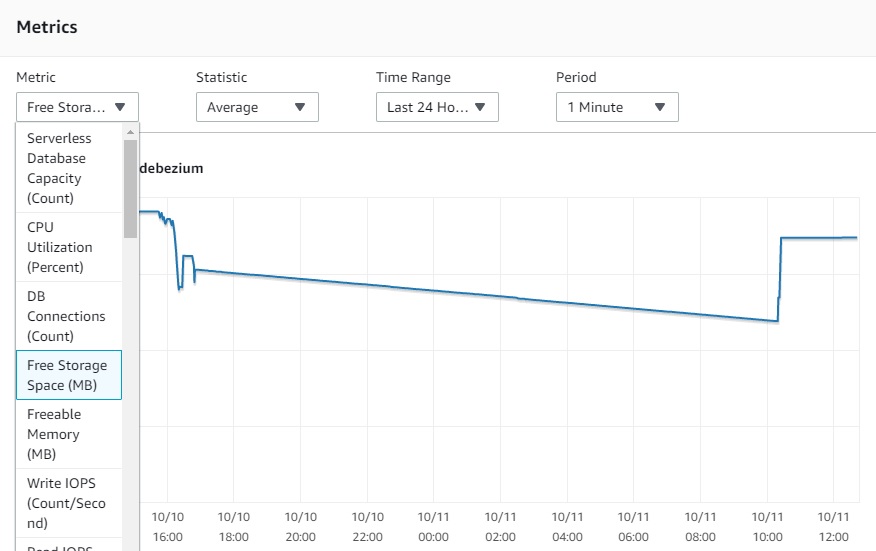
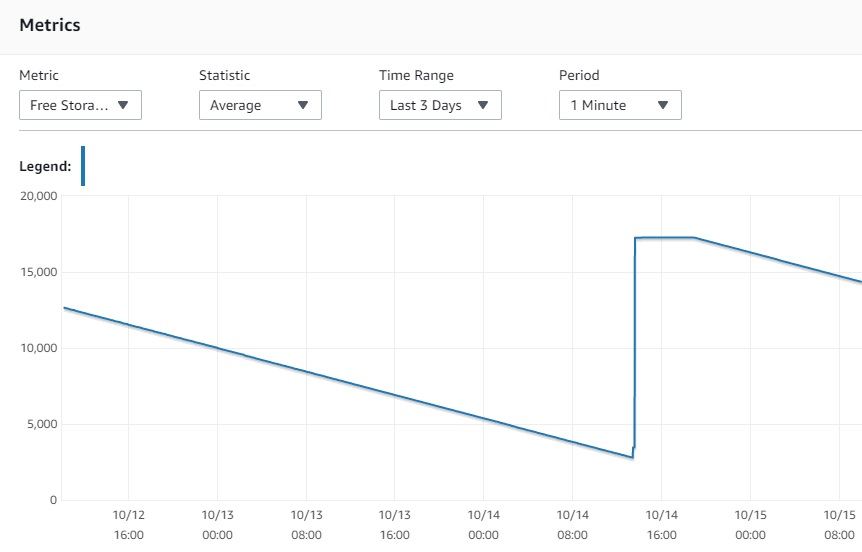
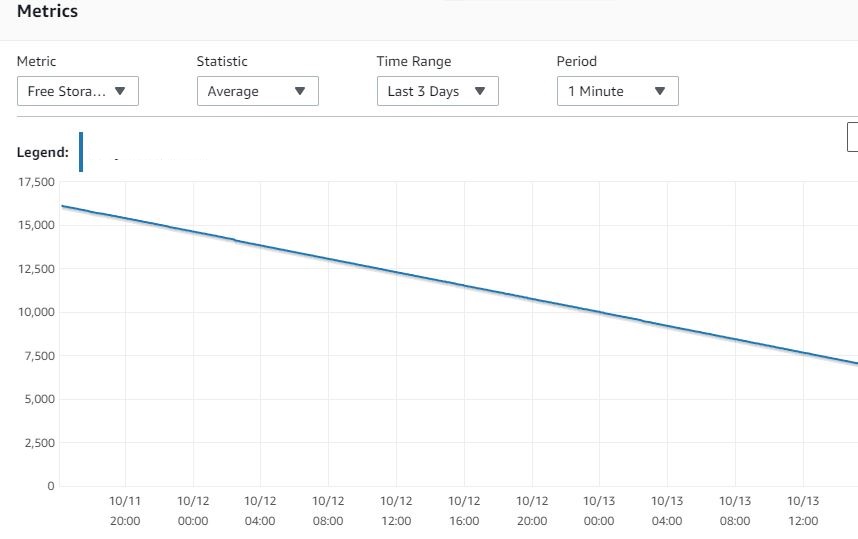
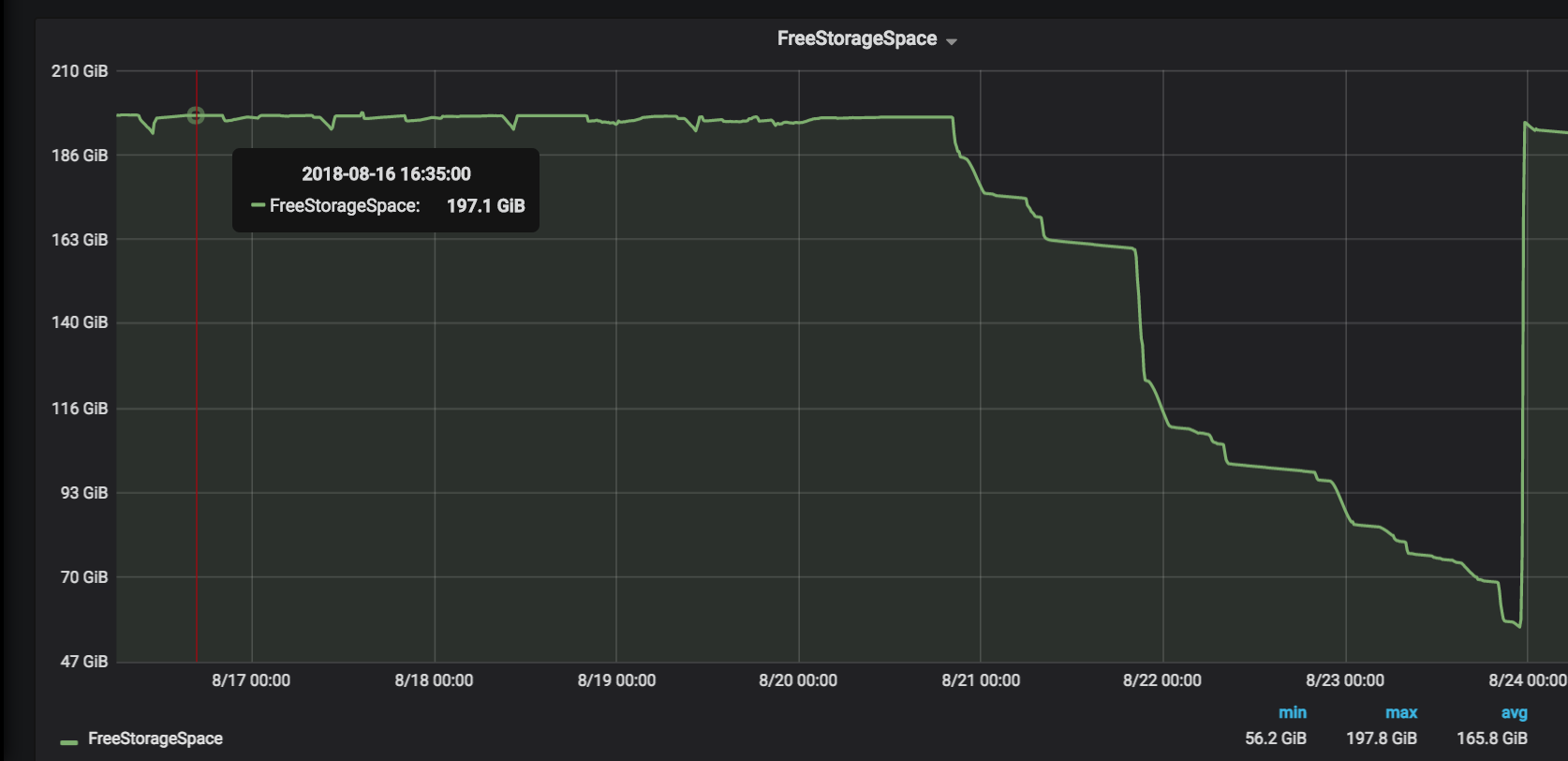
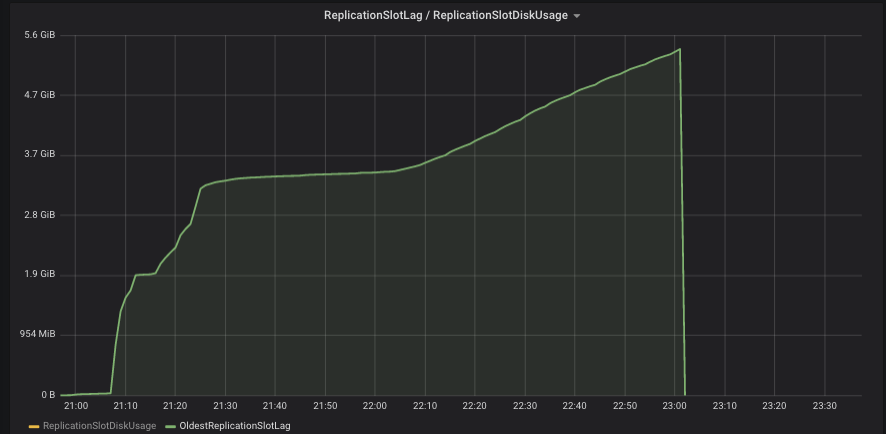
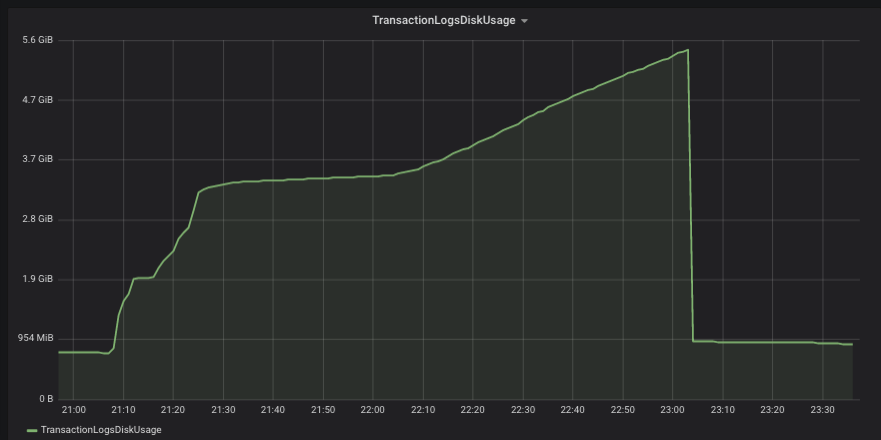
After deploying the Debezium connector for Postgres in our unstable environment we faced our Postgres instance quickly running out of space.
We have a Postgres instance where we have two databases: production and unstable.
The connector is configured to capture changes from the unstable database. The changes on unstable are few and the connector works correctly.
However, the traffic on the production database is quite high and we noticed that the disk space increases monotonically until we almost ran out of disk space.
After stopping the connector and deleting the replication slot, the disk space was freed up.
It appears to me that `replication_slots` in Postgres work across databases and the Connector is not listening to the event of other databases.
- is related to
-
-

- Closed
-


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}