-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
3.0.8.Final, 3.1.0.Beta1
-
None
-
False
-
None
-
False
In order to make your issue reports as actionable as possible, please provide the following information, depending on the issue type.
Bug report
For bug reports, provide this information, please:
What Debezium connector do you use and what version?
2.7.4, but I see the same code on master branch too
What is the connector configuration?
{
"name": "check-olr",
"config": {
"driver.oracle.jdbc.timezoneAsRegion": false,
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"database.connection.adapter": "olr",
"database.dbname": "XE",
"database.hostname": "oracle-sourcedb-vm.cdc.local",
"database.port": "1521",
"database.password": "USR1PWD",
"database.user": "USR1",
"database.query.timeout.ms": "600000",
"converters": "number-to-boolean",
"decimal.handling.mode": "double",
"number-to-boolean.type": "io.debezium.connector.oracle.converters.NumberOneToBooleanConverter",
"include.schema.changes": "false",
"openlogreplicator.host": "oracle-sourcedb-vm.cdc.local",
"openlogreplicator.port": "27017",
"openlogreplicator.source": "XE",
"store.only.captured.tables.ddl": "true",
"table.ignore.builtin": "false",
"table.include.list": "USR1.PPerson, null.PPerson",
"tasks.max": "1",
"topic.prefix": "cdc",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "schema-changes.inventory",
"schema.history.internal.store.only.captured.tables.ddl": "true"
}
}
What is the captured database version and mode of deployment?
Local Oracle Databse is in docker
What behavior do you expect?
I expect connector not to skip single transaction
What behavior do you see?
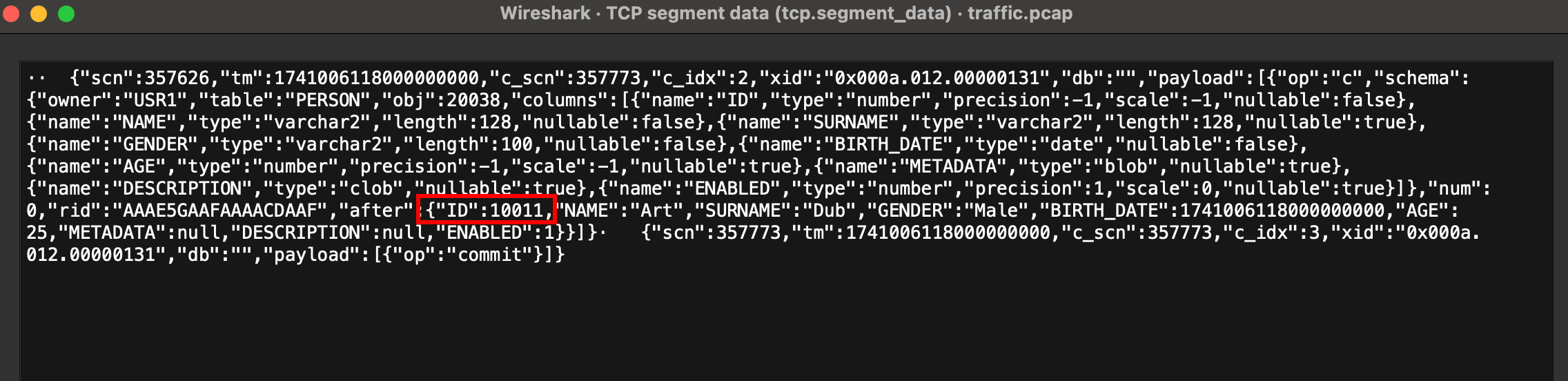
After snapshot reading is completed connector has no scn_idx in offset context.
There is no scn_idx assignment:
It involves that there is no chance to not to skip scn transaction:
Because it leads to skipToStartScn is always true after snapshot.
And finally, we got skipped scn (that could mean we lost a transaction):
Why is there a code to skip scn? I haven't found the reason of it.
Do you see the same behaviour using the latest released Debezium version?
(Ideally, also verify with latest Alpha/Beta/CR version)
Yes, by code, check links below
Do you have the connector logs, ideally from start till finish?
(You might be asked later to provide DEBUG/TRACE level log)
I lost them, but if it's needed I'll provide
How to reproduce the issue using our tutorial deployment?
Start Oracle Database with single table (it's simplification to be easy reproducer).
CREATE TABLE USR1.PPerson (
id NUMBER PRIMARY KEY,
name VARCHAR2(128) NOT NULL,
surname VARCHAR2(128),
gender VARCHAR2(100) NOT NULL,
birth_date DATE NOT NULL,
age NUMBER,
metadata BLOB,
description CLOB,
enabled NUMBER(1)
);
Run some inserts before running connector
INSERT INTO USR1.PPerson VALUES (10001, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10002, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10003, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10004, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10005, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit;
Start OLR with config(OLR is not necessary because it works perfectly and send messages as needed, but connector skip it):
{
"version": "1.8.3",
"log-level": 4,
"source": [
{
"alias": "S1",
"name": "XE",
"reader": {
"type": "online",
"path-mapping": [
"/u01/app/oracle/oradata",
"/opt/oradata",
"/u01/app/oracle/fra",
"/opt/fra"
],
"user": "USR1",
"password": "USR1PWD",
"server": "//oracledb:1521/XE"
},
"format": {
"type": "json",
"column": 2,
"db": 3,
"interval-dts": 9,
"interval-ytm": 4,
"message": 2,
"rid": 1,
"schema": 7,
"scn-type": 1,
"timestamp-all": 1
},
"filter": {
"table": [
{
"owner": "USR1",
"table": ".*"
}
]
}
}
],
"target": [
{
"alias": "DEBEZIUM",
"source": "S1",
"writer": {
"type": "network",
"uri": "0.0.0.0:27017"
}
}
]
}
Start a connector and wait until snapshot read has been finished.
Then you'll get 5 records in Kafka.
Then, you can insert another 5 records:
INSERT INTO USR1.PPerson VALUES (10011, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10012, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10013, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10014, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit; INSERT INTO USR1.PPerson VALUES (10015, 'Art', 'Dub', 'Male',SYSDATE, 25, NULL, NULL, 1); commit;
After finishing of parsing you'll see that kafka has only 9 records, and there will be no record with 10011 ID
Feature request or enhancement
For feature requests or enhancements, provide this information, please:
I think there should be a reason of skipping records. IDK, but we could delete this skip phase.