-
Enhancement
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
False
-
-
False
Feature request or enhancement
For feature requests or enhancements, provide this information, please:
Which use case/requirement will be addressed by the proposed feature?
When processing big transactions that involve at least two tables, the sqlserver connector requires unbounded memory. This happens due to the fact that mssql-jdbc driver can't multiplex when multiple selects are executed over the same connection. In order to process subsequent selects, the driver buffers the current response in memory. If it has to execute a couple of selects in parallel, almost all the data ends up in memory.
At the same time, the connector doesn't limit the number of rows selected from each transaction. The only option available at the moment is `max.iteration.transaction` which works well for small transactions, but it doesn't help with big ones.
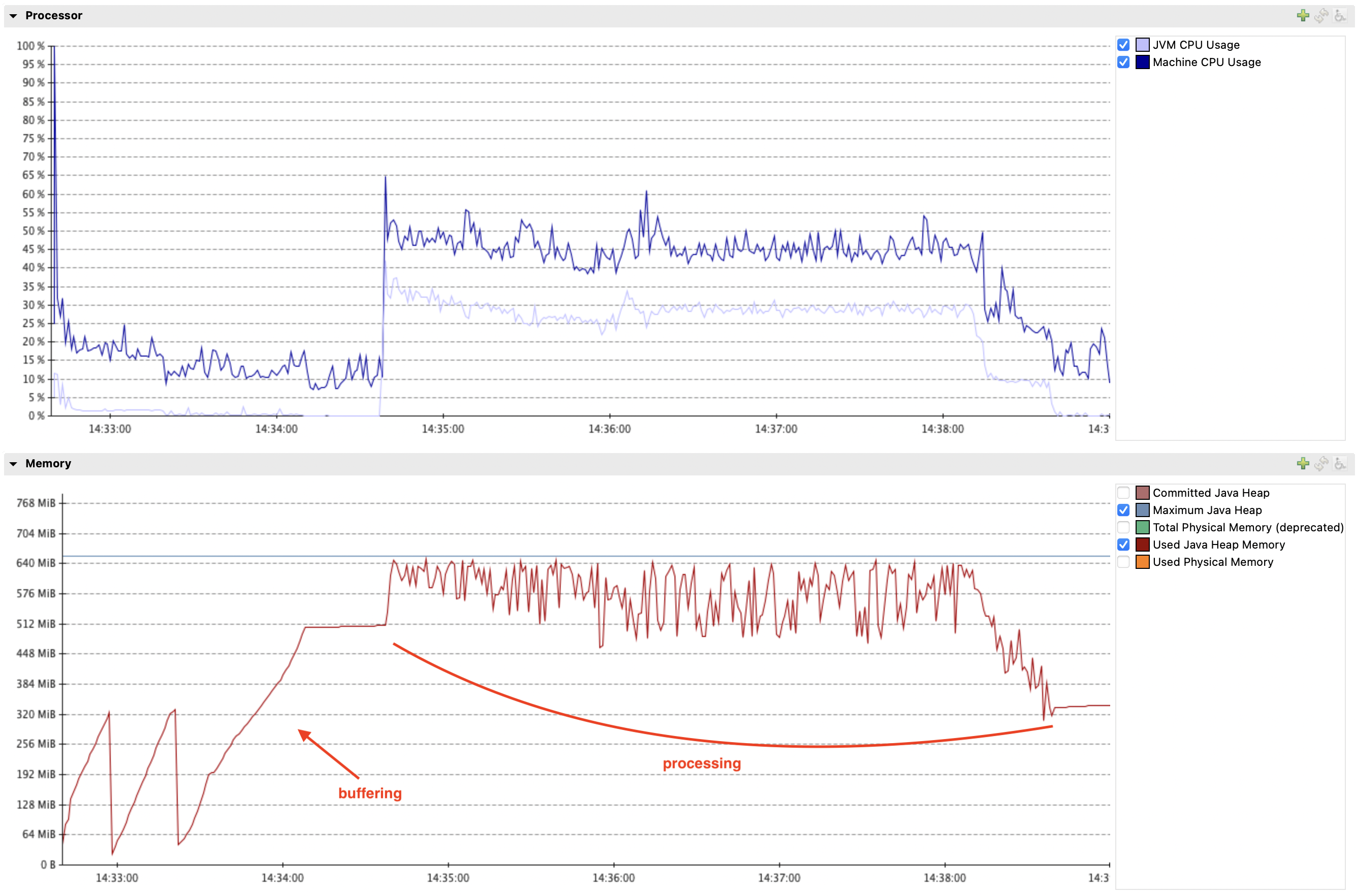
For example, here is a chart showing memory usage when processing a transaction that contains almost 2 million rows (900K updates):
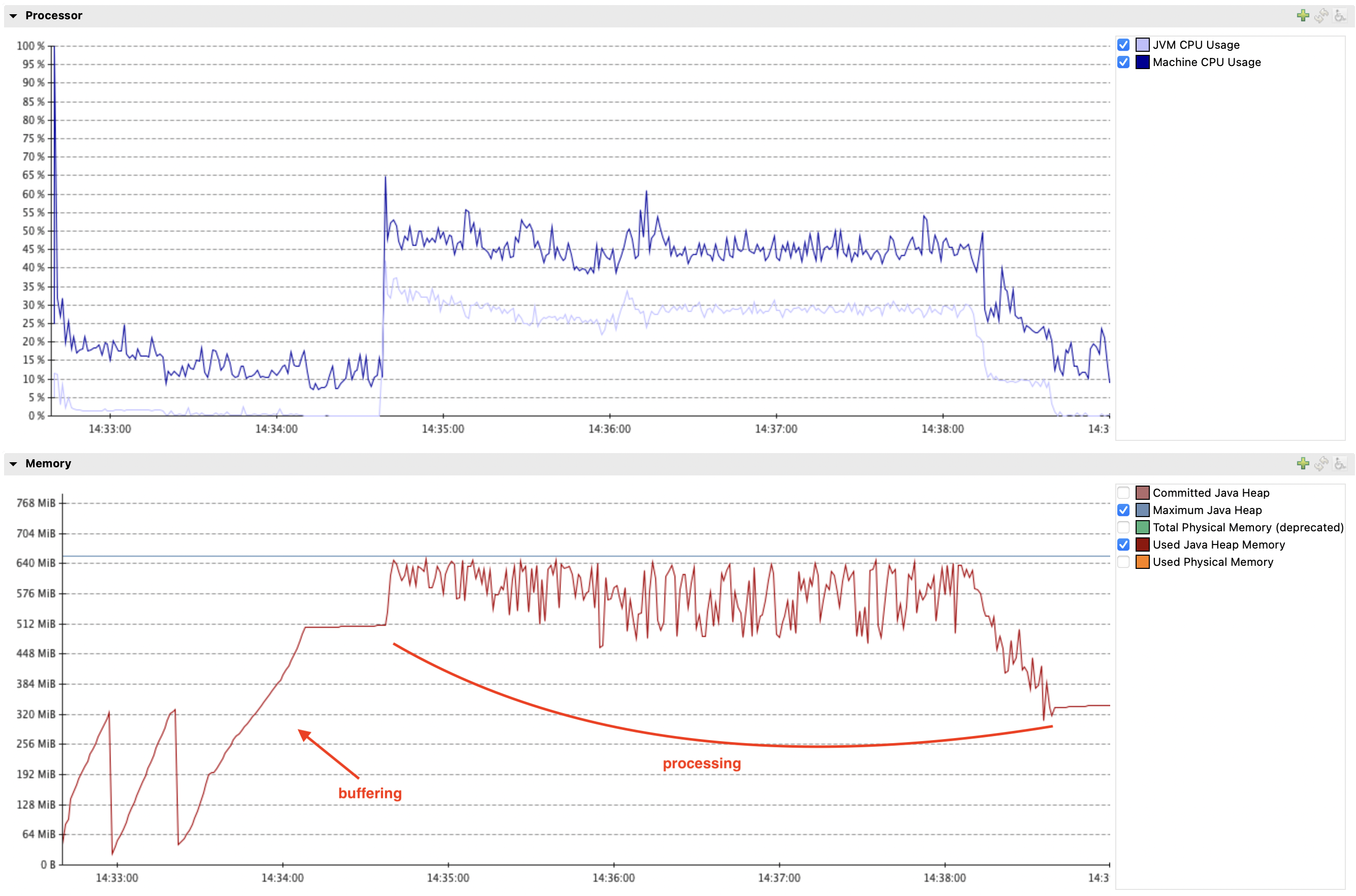
It required 650MB to process the transaction, 500 of which were needed to buffer the data. 650MB is the minimum in this case, setting -Xmx to lower value caused OOMs. max.iteration.transactions is set to 1.
Because of all that, we've been running connectors with database cursors enabled (driver.selectMethod=cursor). But cursors don't work well in all cases. We have to manually disable them when snapshoting relatively big databases, otherwise it's very slow. Also, they consume additional resources on the database side.
Implementation ideas (optional)
An obvious solution would be to paginate the query that fetches CDC data, so that at any point in time there is only a limited number of rows in memory. It can be controlled by a new setting called streaming.fetch.size (by analogy with snapshot.fetch.size).
I've implemented the suggested change in this PR: https://github.com/debezium/debezium/pull/6075.
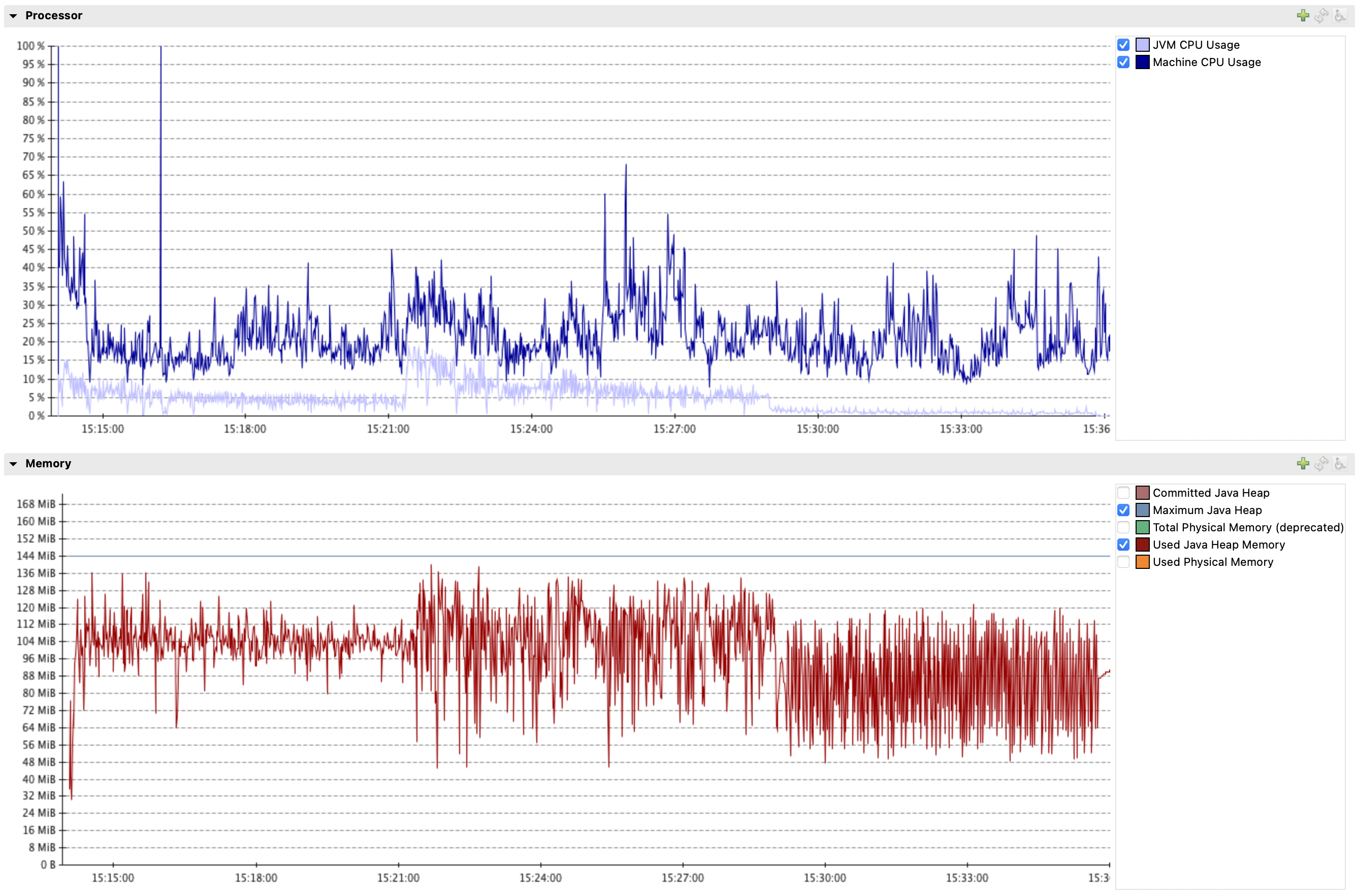
Setting streaming.fetch.size=1000 (also data.query.mode=direct, max.iteration.transactions=1 and creating an index (__$start_lsn ASC, __$seqval ASC, __$operation ASC) on all capture instances) required only 140MB to get the same transaction processed by the connector:
- links to
-
 RHEA-2025:154266
Red Hat build of Debezium 3.2.4 release
RHEA-2025:154266
Red Hat build of Debezium 3.2.4 release
