-
Bug
-
Resolution: Obsolete
-
 Major
Major
-
2.6.0.Beta1
-
False
-
-
False
Bug report
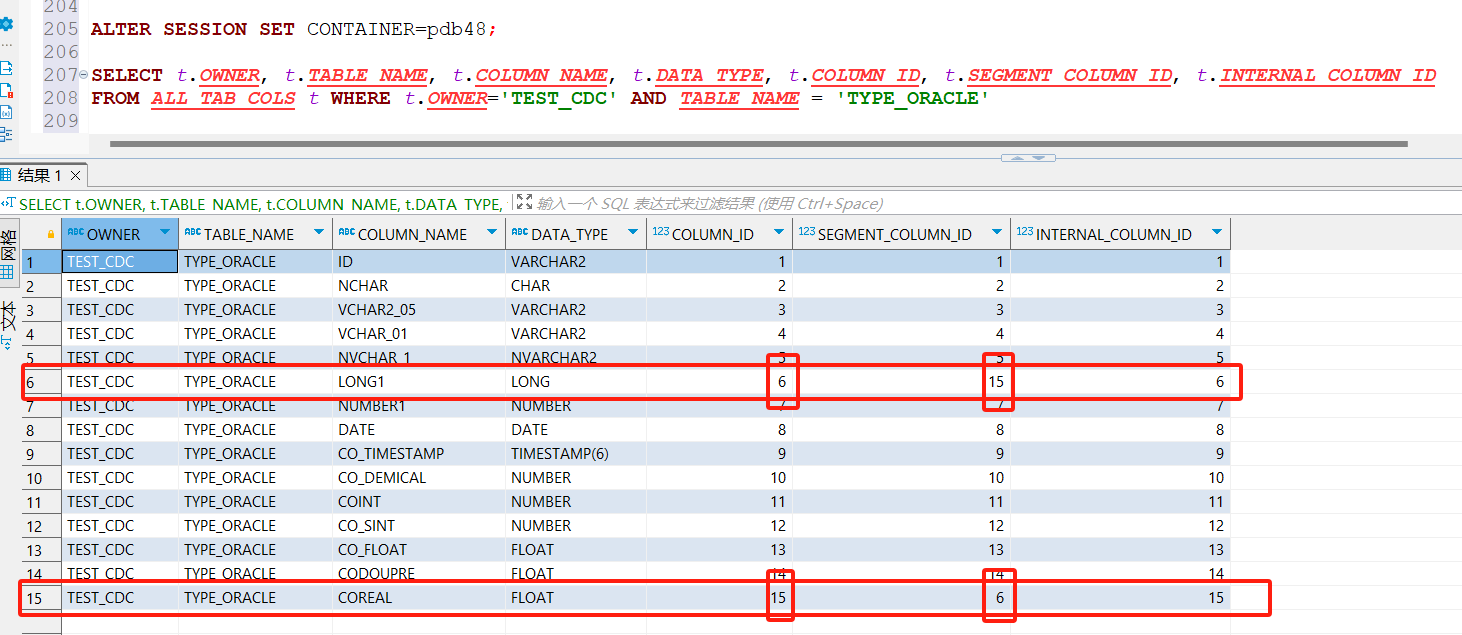
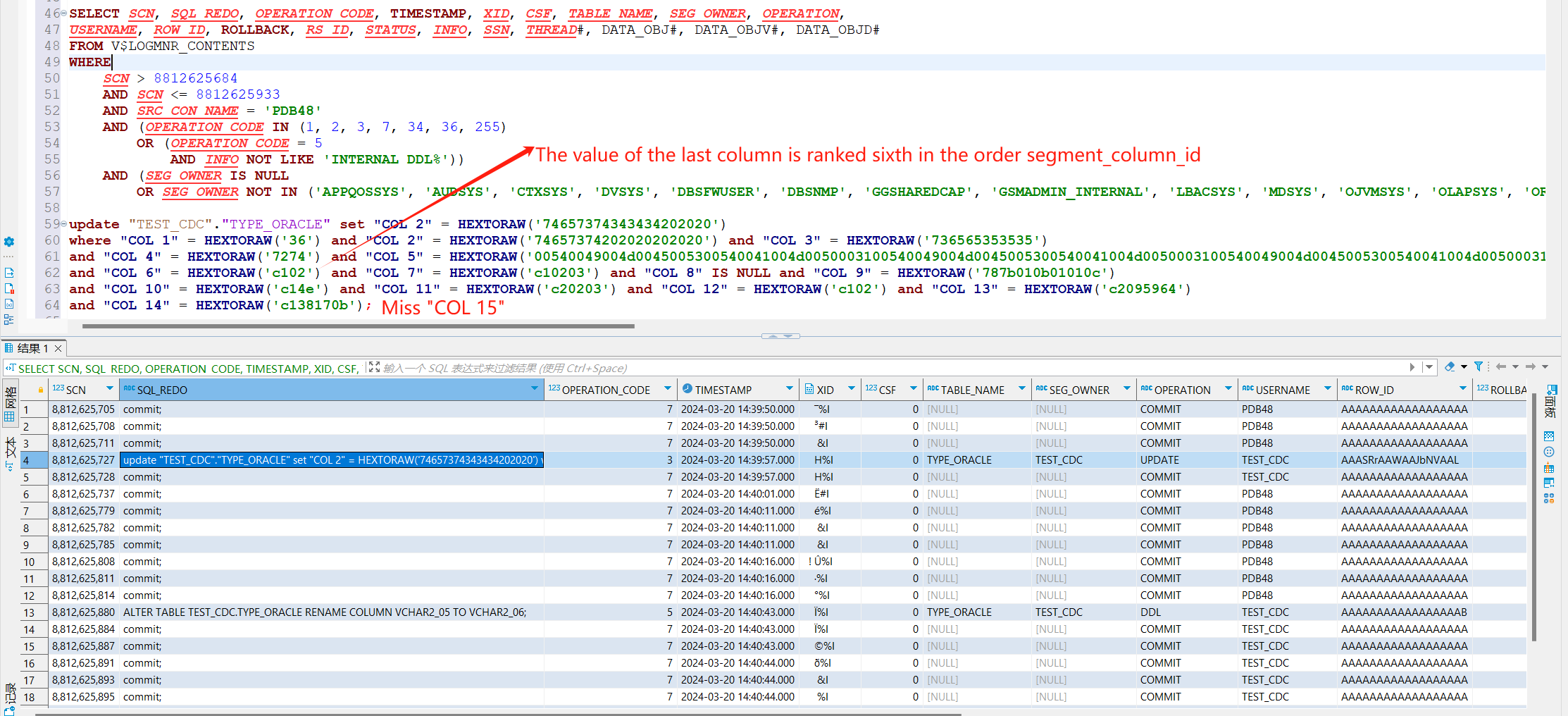
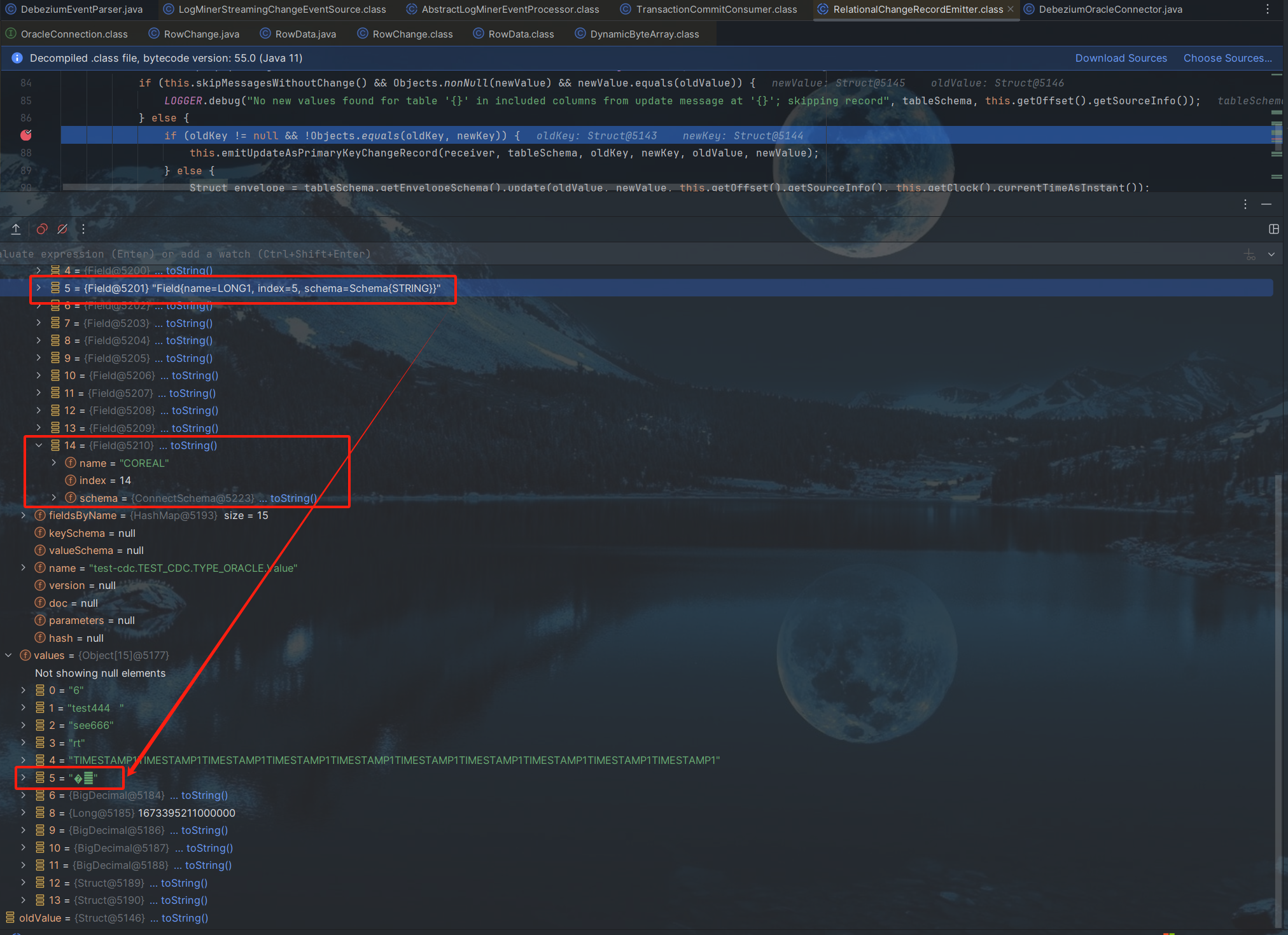
In the Oracle database, column_id and segment_column_id are inconsistent in the column information queried in the ALL_TAB_COLS view. This phenomenon is reflected in the database that columns displayed in the database client software are displayed in the ascending order of column_id. When you change the value of a field in the table, then change the field name in the table. Then, the columns in sql_redo obtained by logminer log mining are combined in ascending order according to segment_column_id. Because the table field values are updated first and then the table structure is modified, the names of sql_redo fields mined in the log are COL X, not actual field names, but sql_redo is combined according to the segment_column_id of the fields. If the column_id and segment_column_id are inconsistent, Debezium will encounter a mismatch between the field name and the field value during parsing. Do you need segment_column_id as the actual order of the columns?
What Debezium connector do you use and what version?
debezium-connector-oracle-2.6.0.Beta1
What is the connector configuration?
connector.class = io.debezium.connector.oracle.OracleConnector
snapshot.locking.mode = none
log.mining.buffer.drop.on.stop = true
schema.include.list = TEST_CDC
log.mining.strategy = hybrid
schema.history.internal.store.only.captured.tables.ddl = true
schema.history.internal.file.filename = ./test-cdc/logminer/storage/dbhistory.dat
tombstones.on.delete = false
topic.prefix = test-cdc
offset.storage.file.filename = ./test-cdc/logminer/offsets.dat
errors.retry.delay.initial.ms = 300
value.converter = org.apache.kafka.connect.json.JsonConverter
key.converter = org.apache.kafka.connect.json.JsonConverter
database.user = C##TESTCDC
database.dbname = ORCLCDB
offset.storage = org.apache.kafka.connect.storage.FileOffsetBackingStore
database.pdb.name = PDB48
database.connection.adapter = logminer
log.mining.buffer.type = memory
offset.flush.timeout.ms = 5000
errors.retry.delay.max.ms = 10000
schema.history.internal.skip.unparseable.ddl = true
database.port = 1521
offset.flush.interval.ms = 60000
schema.history.internal = io.debezium.storage.file.history.FileSchemaHistory
errors.max.retries = -1
database.hostname = 10.10.92.48
database.password = ********
name = test-cdc
skipped.operations = none
table.include.list = TEST_CDC.TYPE_ORACLE,TEST_CDC.TYPE_ORACLE_2,TEST_CDC.TYPE_ORACLE_001
snapshot.mode = when_needed
What is the captured database version and mode of depoyment?
Oracle 19.3.0.0.0
What behaviour do you expect?
Column names and column values correspond one to one.
What behaviour do you see?
Column names and column values do not correspond.
Do you see the same behaviour using the latest relesead Debezium version?
(Ideally, also verify with latest Alpha/Beta/CR version)
<Your answer>
Do you have the connector logs, ideally from start till finish?


How to reproduce the issue using our tutorial deployment?
1. Find a table whose column_id and segment_column_id queried in the ALL_TAB_COLS view are inconsistent. I was just creating the table normally when this happened, and I can't repeat it now.
2. Start the Oracle connector to record the current position and table structure, and then close the Oracle connector.
3. Modify a record in the table and submit it. Then modify the name of a field in the table and submit it.
4. If you restart the Oracle connector, the problem occurs again
Feature request or enhancement
For feature requests or enhancements, provide this information, please:
Which use case/requirement will be addressed by the proposed feature?
<Your answer>
Implementation ideas (optional)
For Oracle, rewrite "OracleDatabaseMetaData.getColumns" method, the query using "segment_column_id" instead of "column_id".
{kind=link}
{kind=link}
{kind=link}