-
Feature Request
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
False
-
-
False
In order to make your issue reports as actionable as possible, please provide the following information, depending on the issue type.
Bug report
For bug reports, provide this information, please:
What Debezium connector do you use and what version?
2.5.4.Final
What is the connector configuration?
{
"name": "vms__staffing_request_src_connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "${file:/secrets/rds.properties:hostname}",
"database.port": "${file:/secrets/rds.properties:port}",
"database.user": "${file:/secrets/rds.properties:user}",
"database.password": "${file:/secrets/rds.properties:password}",
"database.dbname": "vms__staffing_request",
"database.server.name": "vms__abilitystack",
"topic.prefix": "vms__staffing_request",
"plugin.name": "pgoutput",
"slot.name": "vms_staffing_request_slot",
"include.unknown.datatypes": "true",
"schema.include.list": "debezium, master_data, staffing_request, hiring_workflow, candidate",
"table.include.list": "master_data.role, master_data.specialty, master_data.request_type, master_data.shift, master_data.shift_timing, master_data.staffing_request_status, staffing_request.staffing_request, staffing_request.staffing_request_supplier, staffing_request.supplier_tier, staffing_request.staffing_request_audit, hiring_workflow.candidate_staffing_request_xref, hiring_workflow.hiring_workflow_audit, hiring_workflow.offer, candidate.candidate, candidate.candidate_document, master_data.candidate_management_stage, master_data.candidate_management_sub_stage, master_data.compliance_documents_status, staffing_request.staffing_request_helper, staffing_request.staffing_request_approver",
"transforms.unwrap.drop.tombstones": "false",
"time.precision.mode": "connect",
"snapshot.mode": "always",
"decimal.format": "NUMERIC",
"json.output.decimal.format": "NUMERIC",
"decimal.handling.mode": "precise",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "true",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "true",
"heartbeat.interval.ms": "5000",
"heartbeat.action.query": "update debezium.debezium_heartbeat set last_heartbeat_ts = now();"
}
}
What is the captured database version and mode of depoyment?
(E.g. on-premises, with a specific cloud provider, etc.)
RDS Postgres
What behaviour do you expect?
<Your answer>
What behaviour do you see?
Caused by: org.apache.kafka.connect.errors.ConnectException: Failed to resolve column type for schema: ARRAY (null)
Do you see the same behaviour using the latest relesead Debezium version?
(Ideally, also verify with latest Alpha/Beta/CR version)
Yes There is no support for the mentioned data type `text[]`
Do you have the connector logs, ideally from start till finish?
(You might be asked later to provide DEBUG/TRACE level log)
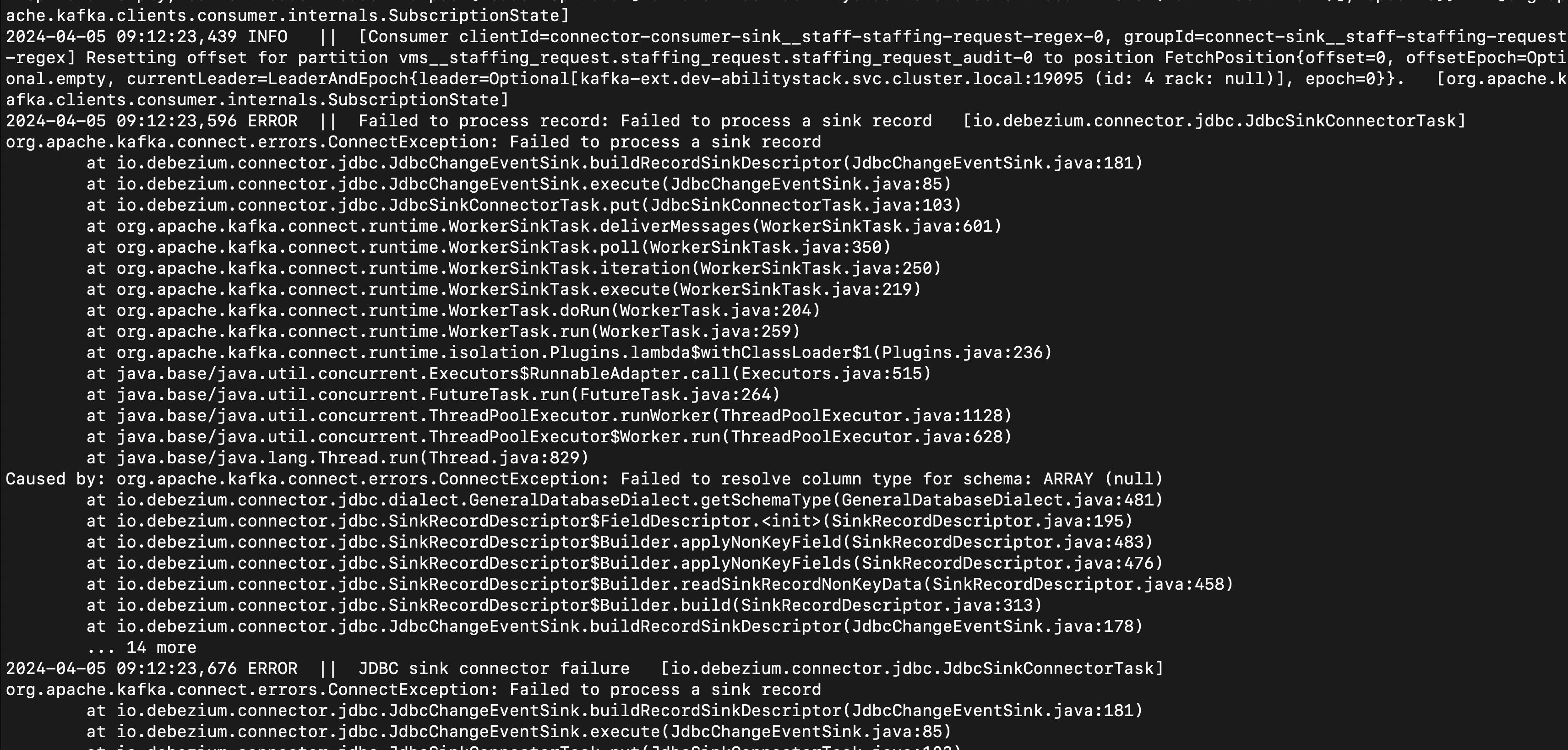
INFO
[Consumer clientId=connector-consumer-sink
_staff-staffing-request-regex-0, groupId=connect-sink.
staff-staffing-request
regex] Resetting offset for partition vms__staffing_request.staffing_request.staffing_request_audit to position FetchPositionfoffset=@, offsetEpoch=Opti
onal.empty, currentLeader=LeaderAndEpoch{leader=Optional[kafka-ext.dev-abilitystack.svc.cluster.local:19095 (id: 4 rack: null)], epoch=0}}.
[org.apache.k
afka.clients.consumer.internals.SubscriptionState]
2024-04-05 09:12:23,596 ERROR || Failed to process record: Failed to process a sink record
[io.debezium.connector.jdbc.JdbcSinkConnectorTask]
org.apache.kafka.connect.errors.ConnectException: Failed to process a sink record
at io.debezium.connector.jdbc.JdbcChangeEventSink.buildRecordSinkDescriptor(JdbcChangeEventSink.java:181)
at io.debezium.connector.jdbc.JdbcChangeEventSink.execute(JdbcChangeEventSink.java:85)
at io.debezium.connector.jdbc.JdbcSinkConnectorTask.put(JdbcSinkConnectorTask.java:103)
at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:601)
at org.apache.kafka.connect.runtime.WorkerSinkTask.poll(WorkerSinkTask.java:350)
at org.apache.kafka.connect.runtime.WorkerSinkTask.iteration(WorkerSinkTask.java:250)
at org.apache.kafka.connect.runtime.WorkerSinkTask.execute(WorkerSinkTask.java:219)
at
org.apache.kafka.connect.runtime.WorkerTask.doRun(WorkerTask.java:204)
at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:259)
at org.apache.kafka.connect.runtime.isolation.Plugins.lambda$withClassLoader$1(Plugins.java:236)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run/ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run (Thread.java:829)
Caused by: org.apache.kafka.connect.errors.ConnectException: Failed to resolve column type for schema: ARRAY (null)
at io.debezium.connector.jdbc.dialect.GeneralDatabaseDialect.getSchemaType(GeneralDatabaseDialect.java:481)
at
io.debezium.connector.jdbc.SinkRecordDescriptor$FieldDescriptor.<init>(SinkRecordDescriptor.java:195)
at io.debezium.connector.jdbc.SinkRecordDescriptor$Builder.applyNonKeyField(SinkRecordDescriptor.java:483)
at io.debezium.connector.jdbc.SinkRecordDescriptor$Builder.applyNonKeyFields(SinkRecordDescriptor.java:476)
at
io.debezium.connector.jdbc.SinkRecordDescriptor$Builder.readSinkRecordNonKeyData(SinkRecordDescriptor.java:458)
at
io.debezium.connector.jdbc.SinkRecordDescriptor$Builder.build(SinkRecordDescriptor.java:313)
at io.debezium.connector.jdbc.JdbcChangeEventSink.buildRecordSinkDescriptor(JdbcChangeEventSink.java:178)
14 more
2024-04-05 09:12:23,676 ERROR || JDBC sink connector failure
[io.debezium.connector.jdbc.JdbcSinkConnectorTask]
org.apache.kafka.connect.errors.ConnectException: Failed to process a sink record
at io.debezium.connector.jdbc.JdbcChangeEventSink.buildRecordSinkDescriptor(JdbcChangeEventSink.java:181)
How to reproduce the issue using our tutorial deployment?
<Your answer>
Feature request or enhancement
Support for ARRAY data types for postgres - text[]
Which use case/requirement will be addressed by the proposed feature?
<Your answer>
Implementation ideas (optional)
<Your answer>
- causes
-
DBZ-7938 Multiple ARRAY types in single table causing error
-
- Closed
-
- links to
-
 RHEA-2024:139598
Red Hat build of Debezium 2.5.4 release
RHEA-2024:139598
Red Hat build of Debezium 2.5.4 release
