-
Enhancement
-
Resolution: Not a Bug
-
 Critical
Critical
-
None
-
2.0.1.Final
-
None
-
False
-
-
False
In order to make your issue reports as actionable as possible, please provide the following information, depending on the issue type.
Overview
Problem:
Based on performance test of debezium-connector-cassandra I did, the maximum OPS of debezium is around 400, which is way behind the performance of Cassandra, it may cause the accumulation of commit log file and leads to write request rejection of Cassandra, by the code reading, I found that bottleneck is on data parsing & enqueueing of ChangeEventQueue process.
Request:
- Is that true?
- Is there any optimising measurement by modifying configurations?
- Enhancing performance of debezium-connector-cassandra.
Bug report
For bug reports, provide this information, please:
What Debezium connector do you use and what version?
Connector: debezium-connector-cassandra
Tag: 2.0.1.Final
What is the connector configuration?
commit.log.relocation.dir=xxx/debezium/relocation/
commit.log.real.time.processing.enabled=true
cdc.dir.poll.interval.ms=1000
commit.log.marked.complete.poll.interval.ms=1000
num.of.change.event.queues=10
What is the captured database version and mode of deployment?
(E.g. on-premises, with a specific cloud provider, etc.)
Database version: Cassandra 4.0.12
Cluster config: 3 nodes, RF=3
Mode of deployment: deployed on AWS, run as a docker image.
Instance-size: c5.2xlarge (8 vCPU 16G MEM 150G+ EBS)
What behaviour do you expect?
Compatible Debezium data process speed with Cassandra (in this case, at least 5000 OPS)
What behaviour do you see?
- Pressing Cassandra with 600 write OPS, Debezium OPS is around 400
- Increasing Cassandra write OPS to 1200, Debezium OPS is still around 400
- No bottleneck is found on resource(CPU, MEM, network bandwidth, disk bandwidth)
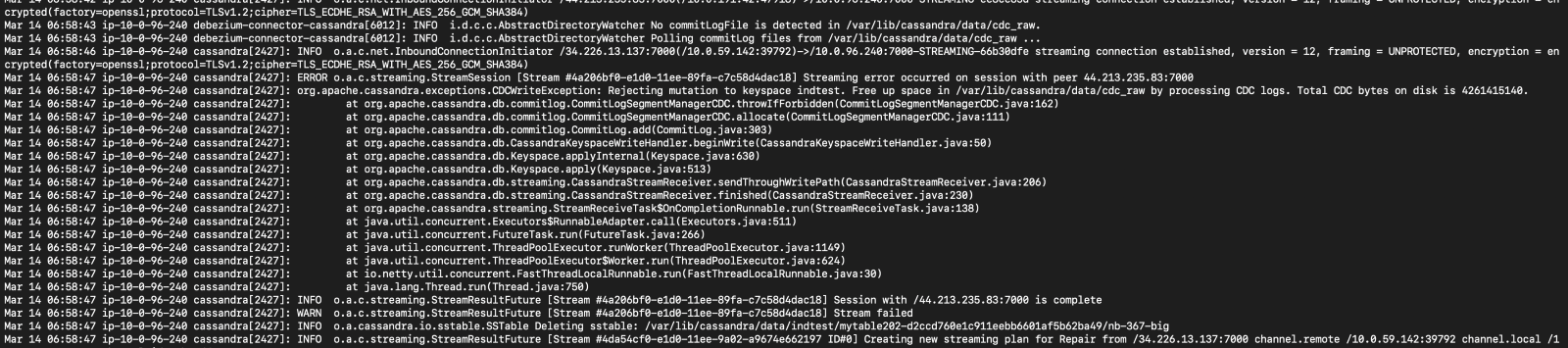
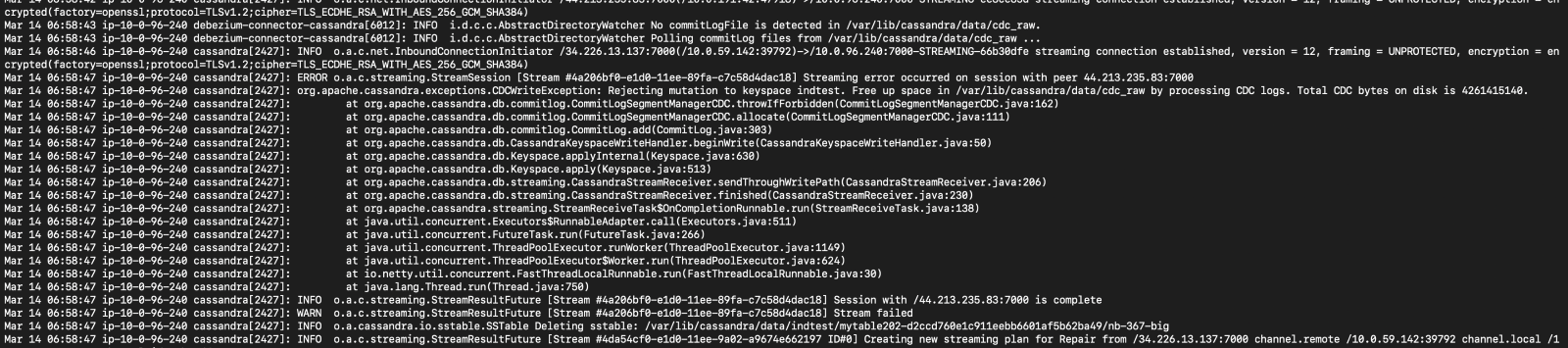
- Commit log files in cdc_raw_dir start to accumulate, once reach the limit (4GB by default), all write request will be rejected by Cassandra
- It can also lead to failure of node decommission (before decommission, node will stream data on it to another node, the streaming process use write path)
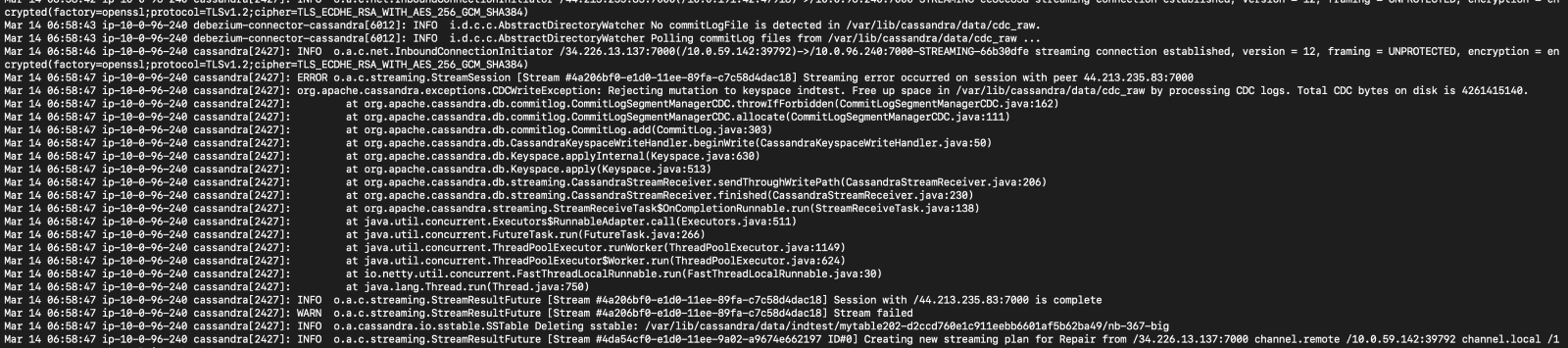

Do you see the same behaviour using the latest relesead Debezium version?
(Ideally, also verify with latest Alpha/Beta/CR version)
Have not tried yet, but base on the testing and code reading, the bottleneck exists in data parsing and enqueueing process (handled by single thread executor, can only process one file at once), and is not be improved in latest version.
Do you have the connector logs, ideally from start till finish?
(You might be asked later to provide DEBUG/TRACE level log)
10 event queue is created. 
Cycle of detection is shortened to 1s. 
Lots of "hungry" QueueProcessor (consumers)

If we track one commit log file, it can be found that, processCommitLog() takes 117s to finish 32MB data processing, performance is not getting better. 
How to reproduce the issue using our tutorial deployment?
null
Feature request or enhancement
For feature requests or enhancements, provide this information, please:
Which use case/requirement will be addressed by the proposed feature?
Elevating the performance of debezium-connector-cassandra to match performance of Cassandra, more specifically, at least 5000 OPS if there is no bottleneck on resource.
Implementation ideas (optional)
Root cause of that limited performance is the architecture and implementation (Queue with Lock; Blocked and serial data process in single thread; Data in same file would be distributed to same queue)
To fix that problem, here is some suggestions:
- Use something else (maybe offset itself) as hash key when publishing mutation to internal queue, to make multi-queue useful.
- Add configuration to make it optional that parsing data concurrently (for those who doesn't care order of request at all, for instance: flow auditing), and can be implemented by:
- Change singleThreadExecutor to FixedThreadPool or
- Add CommitLogProcessor for each queue.
- Refactoring ChangeEventQueue, get rid of Lock.