-
Bug
-
Resolution: Cannot Reproduce
-
 Major
Major
-
None
-
2.2.0.Final
-
None
-
False
-
-
False
-
Important
Bug report
For bug reports, provide this information, please:
What Debezium connector do you use and what version?
2.2.Final MongoDB connector
What is the connector configuration?
collection.include.list: 'dev-api.a,debezium.a_signaling' signal.data.collection: 'debezium.a_signaling' snapshot.mode: never incremental.snapshot.chunk.size: 1024
What is the captured database version and mode of deployment?
MongoDB Atlas 4.4
What behavior do you expect?
I started the incremental snapshot using the signal and then after a while, I paused the snapshot. I expected the snapshot to remain paused until I ran a resume signal.


What behaviour do you see?
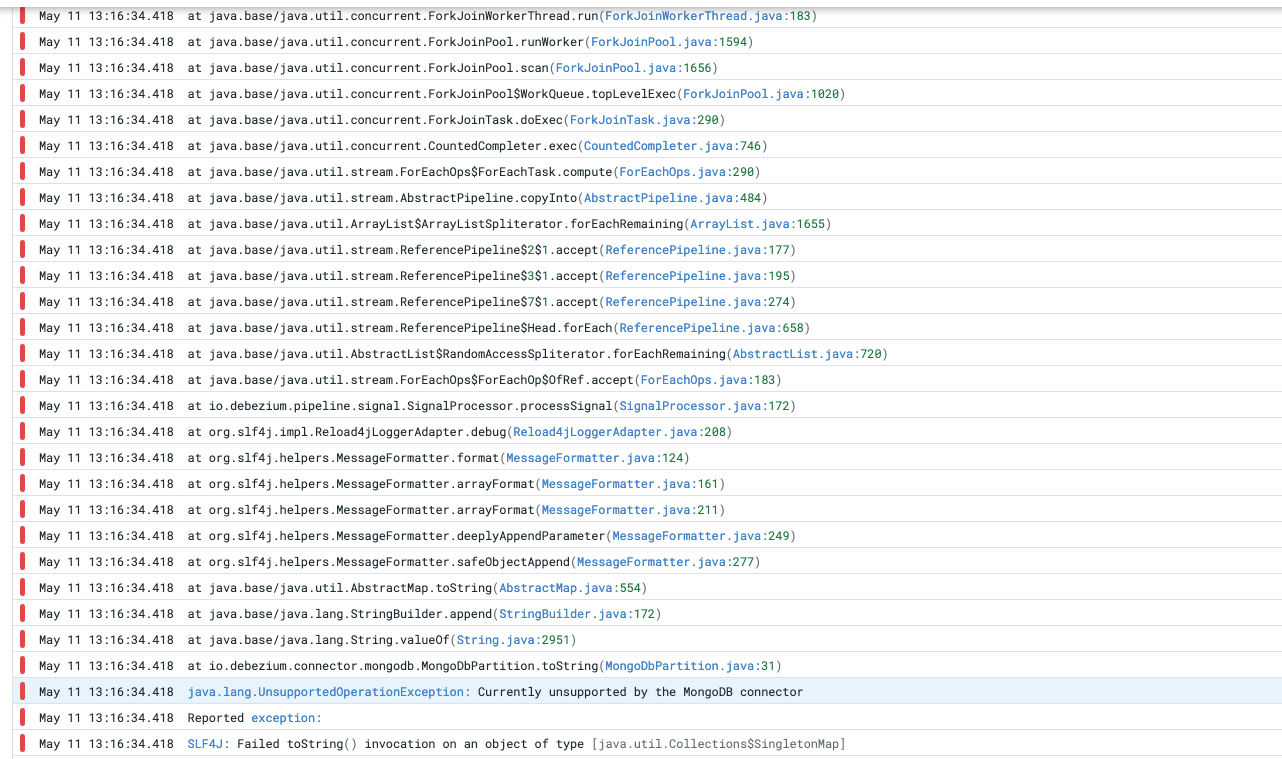
The connector raised an exception because I generated a too-large record in MongoDB. I added the log for the stack trace in the logs and then right after that exception the connector got restarted and the incremental snapshot started again for that collection.
Do you see the same behaviour using the latest released Debezium version?
Yes, I use the latest stable version.
Do you have the connector logs, ideally from start till finish?
Exception:
org.apache.kafka.connect.errors.ConnectException: Unrecoverable exception from producer send callback at org.apache.kafka.connect.runtime.WorkerSourceTask.maybeThrowProducerSendException(WorkerSourceTask.java:312) at org.apache.kafka.connect.runtime.WorkerSourceTask.prepareToSendRecord(WorkerSourceTask.java:126) at org.apache.kafka.connect.runtime.AbstractWorkerSourceTask.sendRecords(AbstractWorkerSourceTask.java:395) at org.apache.kafka.connect.runtime.AbstractWorkerSourceTask.execute(AbstractWorkerSourceTask.java:354) at org.apache.kafka.connect.runtime.WorkerTask.doRun(WorkerTask.java:189) at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:244) at org.apache.kafka.connect.runtime.AbstractWorkerSourceTask.run(AbstractWorkerSourceTask.java:72) at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:829) Caused by: org.apache.kafka.common.errors.RecordTooLargeException: The request included a message larger than the max message size the server will accept.
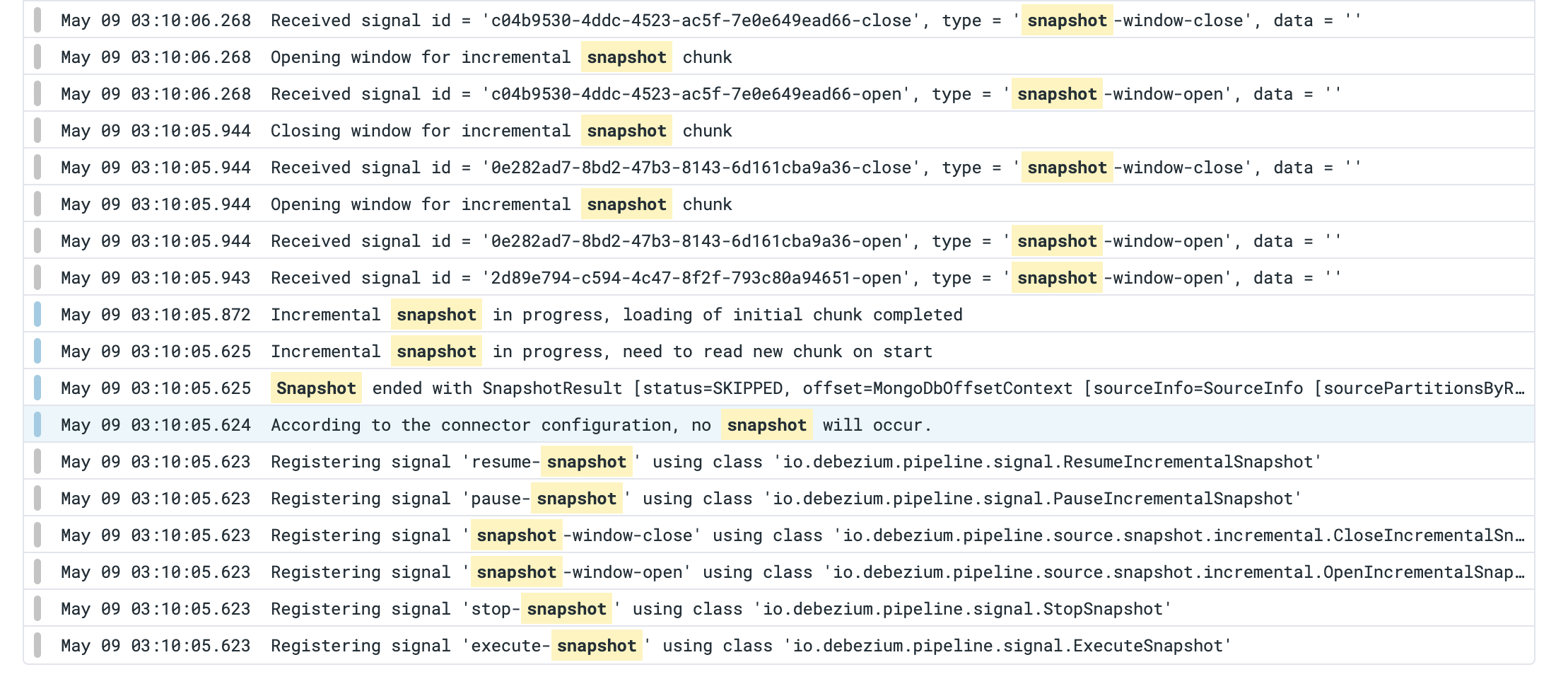
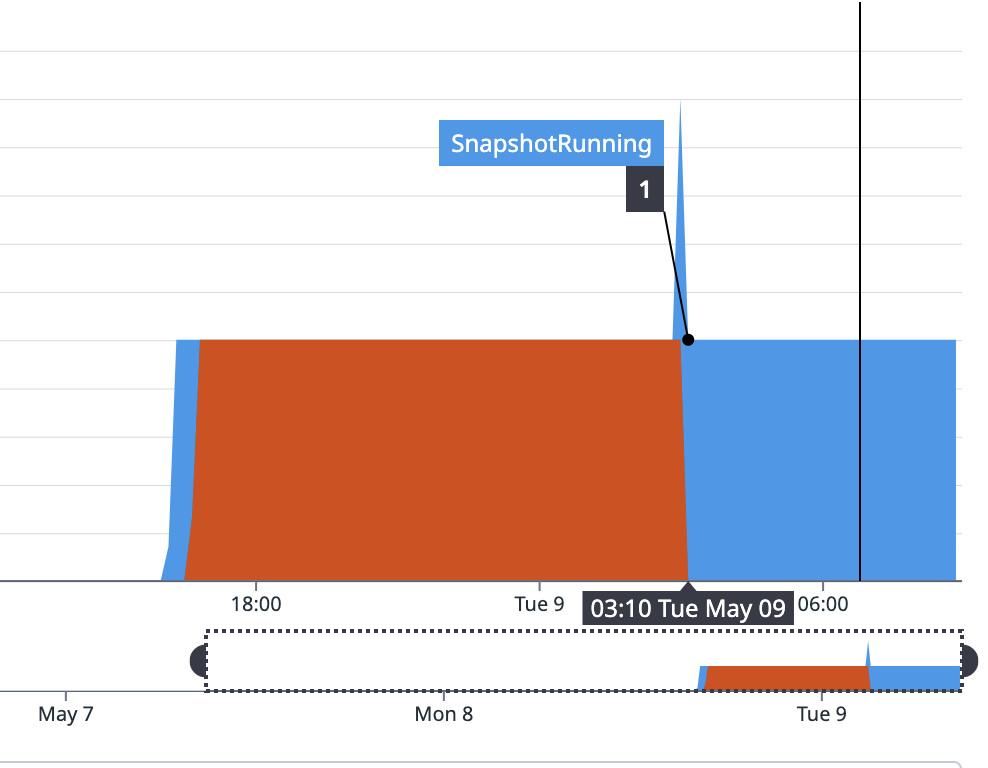
the orange line shows the snapshot paused and the blue shows the snapshot running metric.
How to reproduce the issue using our tutorial deployment?
Run the debezium with the configuration provided above. Start the snapshot then pause it, then save a large record in the collection ( larger than the allowed server size )


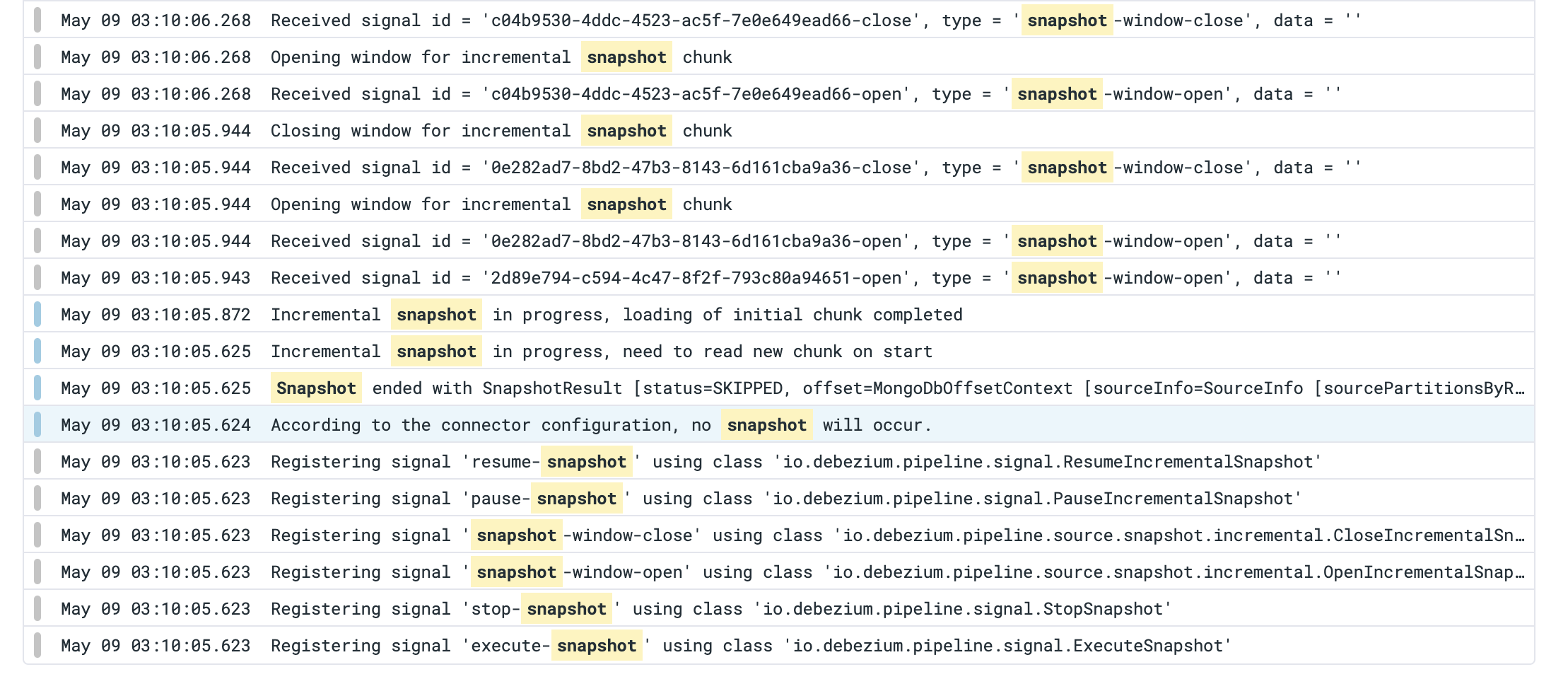
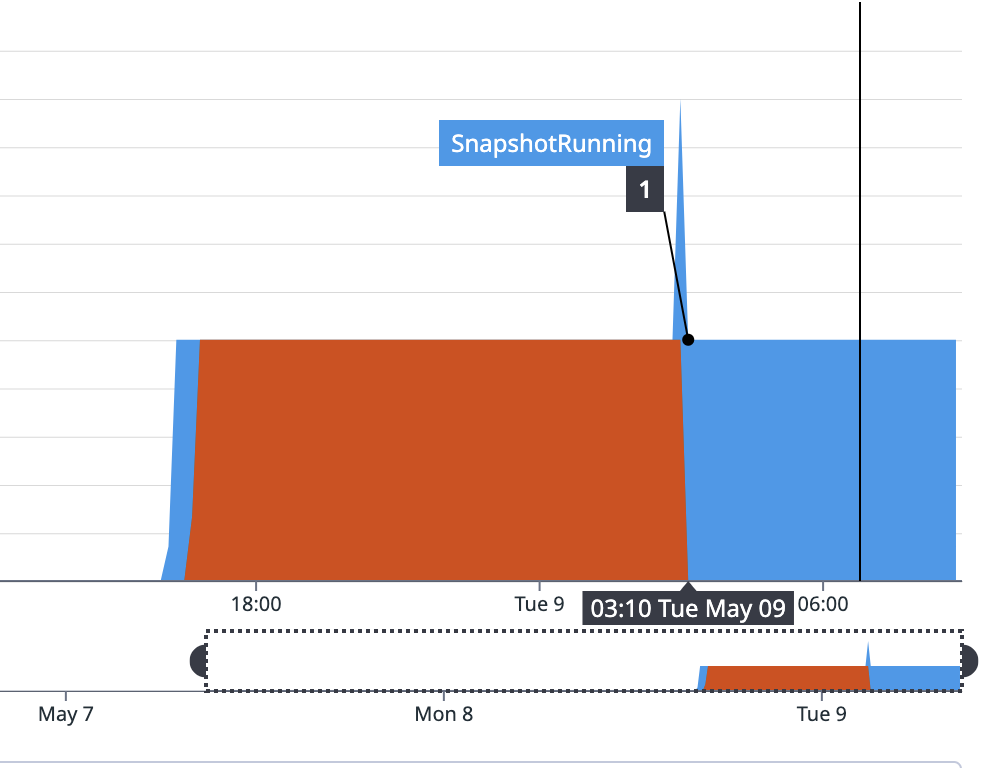
- relates to
-
-
- Closed
-
