-
Enhancement
-
Resolution: Done
-
 Major
Major
-
1.9.0.Final
-
None
-
False
-
-
False
What is the captured database version and mode of deployment?
(E.g. on-premises, with a specific cloud provider, etc.)
Running Debezium Server inside K8S and connected to PG14 database.
What behaviour do you expect?
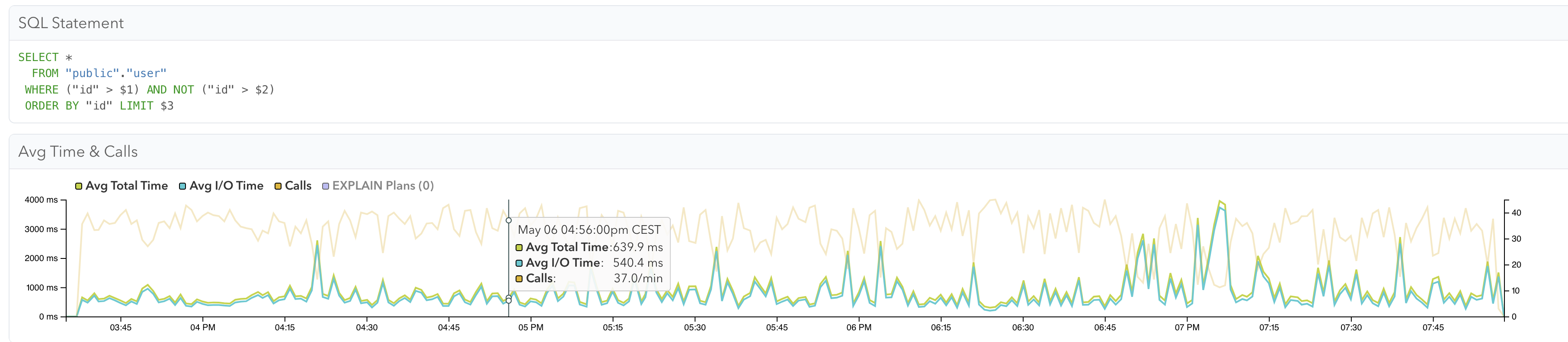
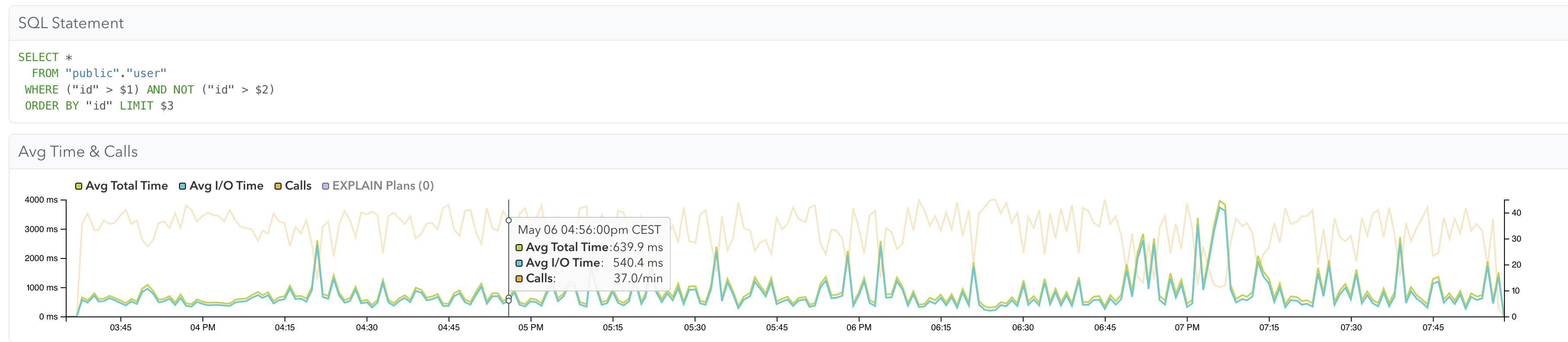
Incremental snapshot queries should perform better when having multi-column PK on the table.
What behaviour do you see?
The query created by debezium for incremental snapshot perform bad.
Do you see the same behaviour using the latest releasead Debezium version?
(Ideally, also verify with latest Alpha/Beta/CR version)
Using Debezium 1.9.0.Final
Do you have the connector logs, ideally from start till finish?
(You might be asked later to provide DEBUG/TRACE level log)
N/A
How to reproduce the issue using our tutorial deployment?
Have this table DDL
create table "user" ( id serial unique, account_id integer not null references account, merged_with integer, external_id text, email text, created_datetime timestamp, updated_datetime timestamp, activated_datetime timestamp, deactivated_datetime timestamp, deleted_datetime timestamp, primary key (id, account_id), foreign key (merged_with, account_id) references "user" );
Try to run an incremental snapshot when this table has a lot of records, say 80mil or even more.
An example of EXPLAIN ANALYZE from my experience
EXPLAIN ANALYZE SELECT * FROM public.user WHERE (("id" > 247000000) OR ("id" = 247000000 AND "account_id" > 15000)) AND NOT (("id" > 495463994) OR ("id" = 495463994 AND "account_id" > 33530)) ORDER BY "id", "account_id" LIMIT 10000; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- Limit (cost=1015.03..74525.87 rows=10000 width=672) (actual time=114042.986..114605.335 rows=1 loops=1) -> Gather Merge (cost=1015.03..3043187.62 rows=413840 width=672) (actual time=114042.984..114605.332 rows=1 loops=1) Workers Planned: 2 Workers Launched: 2 -> Incremental Sort (cost=15.00..2994420.19 rows=206920 width=672) (actual time=114038.991..114038.992 rows=0 loops=3) Sort Key: id, account_id Presorted Key: id Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB Worker 0: Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB Worker 1: Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB -> Parallel Index Scan using user_id_key on "user" (cost=0.57..2985108.79 rows=206920 width=672) (actual time=114038.853..114038.853 rows=0 loops=3) Index Cond: (id <= 495463994) Filter: (((id <> 495463994) OR (account_id <= 33530)) AND ((id > 247000000) OR ((id = 247000000) AND (account_id > 15000)))) Rows Removed by Filter: 25854999 Planning Time: 1.180 ms Execution Time: 114605.492 ms
Also, community chat discussion is here.
Feature request or enhancement
For feature requests or enhancements, provide this information, please:
Which use case/requirement will be addressed by the proposed feature?
Improve performance of incremental snapshot when snapshotting tables with multi-column PK.
Implementation ideas (optional)
<Your answer>
- account is impacted by
-
DBZ-6023 Add support for surrogate keys for incremental snapshots
-
- Closed
-
- links to
-
 RHEA-2024:139598
Red Hat build of Debezium 2.5.4 release
RHEA-2024:139598
Red Hat build of Debezium 2.5.4 release

{kind=link}
{kind=link}