-
Bug
-
Resolution: Done
-
 Major
Major
-
1.9.0.Beta1, 1.9.0.Final
-
None
-
False
-
-
False
Timeline of what happened:
- At 2022-03-14 10:15:17 deleted the kafka connector instance and topics, then started fresh run of the connector. logs show:
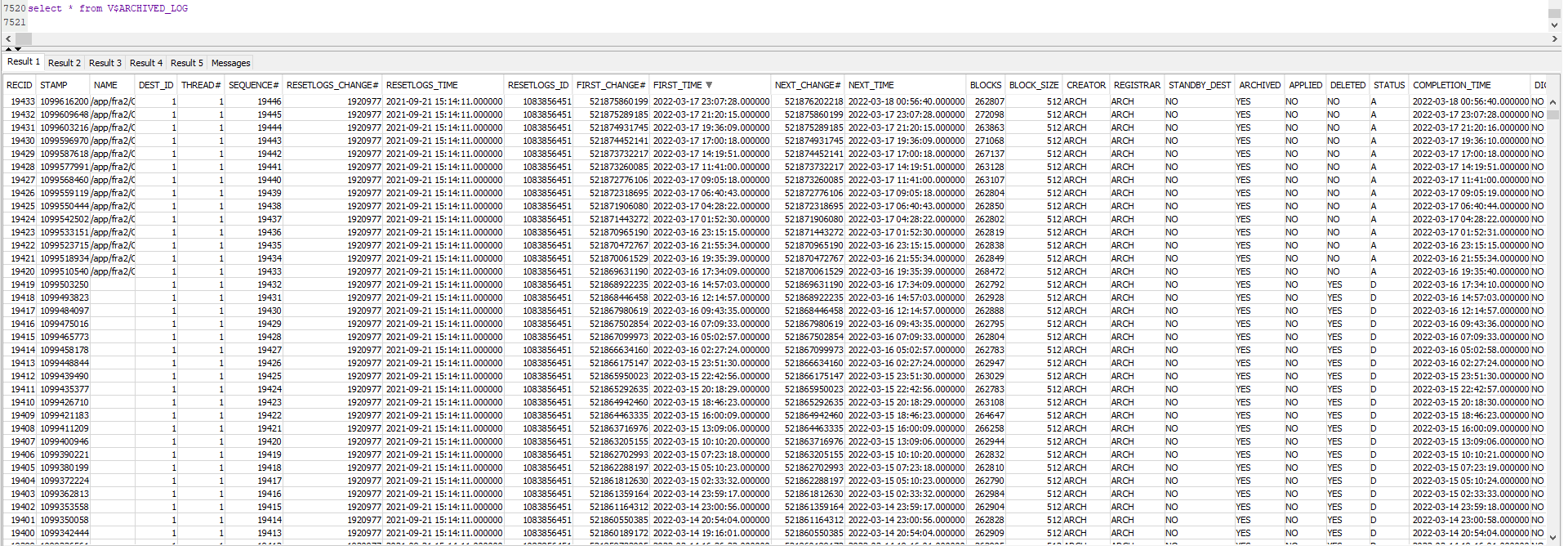
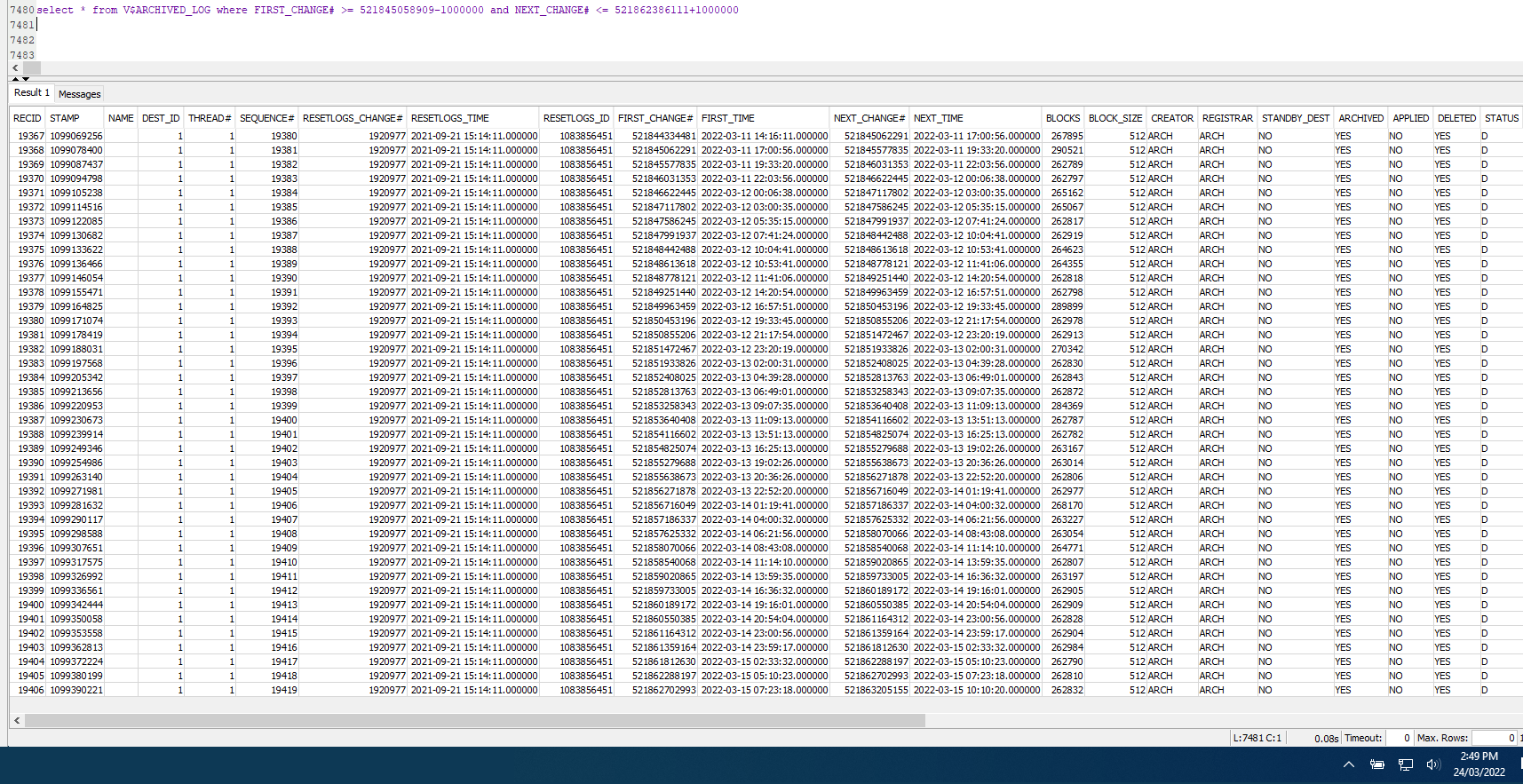
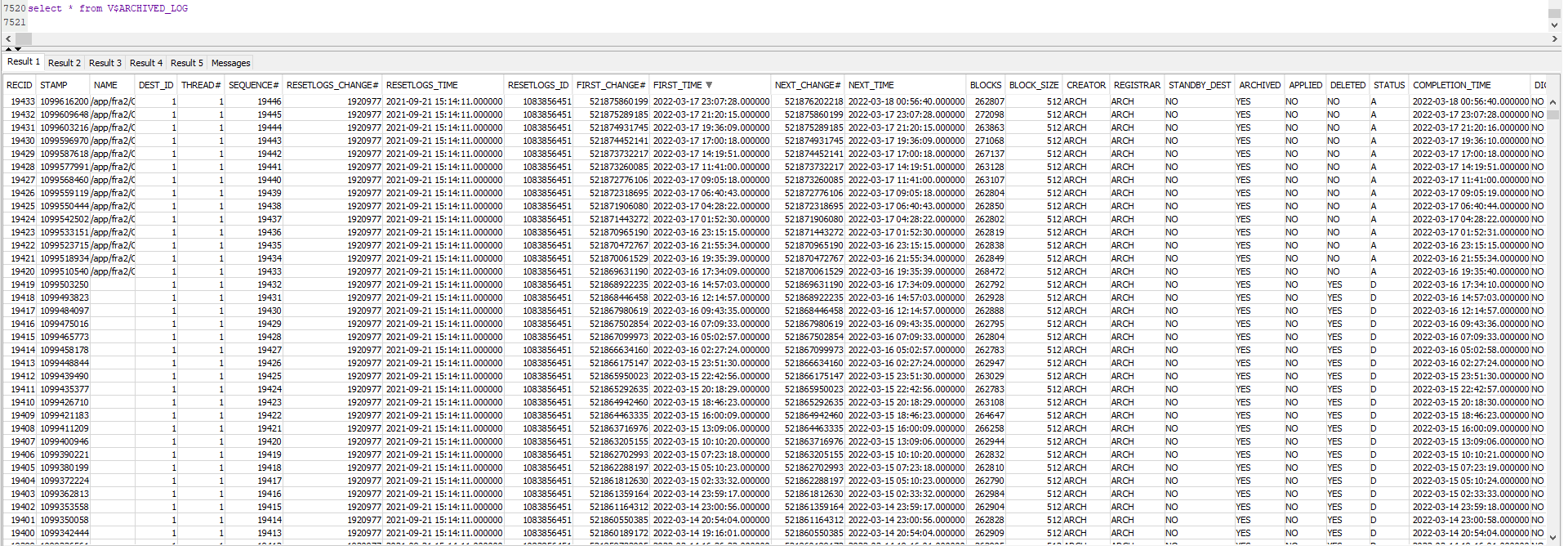
[2022-03-14 10:15:18,543] INFO Found previous partition offset OraclePartition [sourcePartition={server=my-topicoracle}]: {commit_scn=null, transaction_id=null, snapshot_pending_tx=16000b0048522f00:521845058539, snapshot_scn=521845058910, scn=521845058910} [2022-03-14 10:15:32,682] INFO Snapshot ended with SnapshotResult [status=SKIPPED, offset=OracleOffsetContext [scn=521845058910]] (io.debezium.pipeline.ChangeEventSourceCoordinator)\n [2022-03-14 10:15:38,626] INFO Transaction 16000b0048522f00 was pending across snapshot boundary. Start SCN = 521845058539, snapshot SCN = 521845058910 [2022-03-14 10:15:38,627] INFO Setting commit SCN to 521845058909 (snapshot SCN - 1) to ensure we don't double-emit events from pre-snapshot transactions. (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource) [2022-03-14 10:15:38,627] INFO Resetting start SCN from 521845058910 (snapshot SCN) to 521845058539 (start of oldest complete pending transaction) (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource) [2022-03-14 18:42:16,585] INFO No latest table SCN could be resolved, defaulting to current SCN (io.debezium.connector.oracle.OracleSnapshotChangeEventSource) [2022-03-14 18:44:36,575] INFO 1 records sent during previous 00:03:04.517, last recorded offset: {snapshot_pending_tx=01001b003ab92400:521862385676, snapshot_scn=521862386111, snapshot=true, scn=521862386111, snapshot_completed=false} (io.debezium.connector.common.BaseSourceTask) [2022-03-14 18:46:22,285] INFO \u0009 For table 'REDACT ' using select statement: 'SELECT REDACT FROM REDACT AS OF SCN 521862386111' (io.debezium.relational.RelationalSnapshotChangeEventSource) [2022-03-14 18:46:47,226] INFO 20480 records sent during previous 00:02:10.651, last recorded offset: {snapshot_pending_tx=01001b003ab92400:521862385676, snapshot_scn=521862386111, snapshot=true, scn=521862386111, snapshot_completed=false} (io.debezium.connector.common.BaseSourceTask) ...more tables with similar logs... [2022-03-15 03:51:14,271] INFO Snapshot ended with SnapshotResult [status=COMPLETED, offset=OracleOffsetContext [scn=521862386111]] (io.debezium.pipeline.ChangeEventSourceCoordinator) [2022-03-15 03:51:14,520] INFO Transaction 01001b003ab92400 was pending across snapshot boundary. Start SCN = 521862385676, snapshot SCN = 521862386111 (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource) [2022-03-15 03:51:14,520] INFO Setting commit SCN to 521862386110 (snapshot SCN - 1) to ensure we don't double-emit events from pre-snapshot transactions. (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource) [2022-03-15 03:51:14,520] INFO Resetting start SCN from 521862386111 (snapshot SCN) to 521862385676 (start of oldest complete pending transaction) (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)it completed at 2022-03-15 03:51:14 and the connector kept running, waiting for streaming changes BUT i never changed any rows on the oracle db (so no CDC rows to flow to kafka)
- at 2022-03-23 11:41:06 i bounce the pod that debezium is running (distrib mode) but now the task status goes to failed and these errors in the log:
[2022-03-23 11:41:06,523] INFO Found previous partition offset OraclePartition [sourcePartition={server=my-topicoracle}]: {commit_scn=null, transaction_id=null, snapshot_pending_tx=01001b003ab92400:521862385676, snapshot_scn=521862386111, scn=521862386111} (io.debezium.connector.common.BaseSourceTask)
[2022-03-23 11:41:19,486] INFO Snapshot ended with SnapshotResult [status=SKIPPED, offset=OracleOffsetContext [scn=521862386111]] (io.debezium.pipeline.ChangeEventSourceCoordinator)
[2022-03-23 11:41:24,255] INFO Transaction 01001b003ab92400 was pending across snapshot boundary. Start SCN = 521862385676, snapshot SCN = 521862386111 (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)
[2022-03-23 11:41:24,255] WARN Transaction 01001b003ab92400 was still ongoing while snapshot was taken, but is no longer completely recorded in the archive logs. Events will be lost. Oldest SCN in logs = 521869631190, TX start SCN = 521862385676 (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)
[2022-03-23 11:41:24,255] INFO Setting commit SCN to 521862386110 (snapshot SCN - 1) to ensure we don't double-emit events from pre-snapshot transactions. (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)
[2022-03-23 11:41:24,304] ERROR Mining session stopped due to the {} (io.debezium.connector.oracle.logminer.LogMinerHelper)
io.debezium.DebeziumException: Online REDO LOG files or archive log files do not contain the offset scn 521862386111. Please perform a new snapshot.
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:133)\n"
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:57)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.streamEvents(ChangeEventSourceCoordinator.java:173)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.executeChangeEventSources(ChangeEventSourceCoordinator.java:140)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.lambda$start$0(ChangeEventSourceCoordinator.java:109)\n"
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)\n"
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)\n"
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)\n"
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)\n"
at java.base/java.lang.Thread.run(Thread.java:829)\n"
[2022-03-23 11:41:24,304] ERROR Producer failure (io.debezium.pipeline.ErrorHandler)\n"
io.debezium.DebeziumException: Online REDO LOG files or archive log files do not contain the offset scn 521862386111. Please perform a new snapshot.\n"
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:133)\n"
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:57)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.streamEvents(ChangeEventSourceCoordinator.java:173)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.executeChangeEventSources(ChangeEventSourceCoordinator.java:140)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.lambda$start$0(ChangeEventSourceCoordinator.java:109)\n"
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)\n"
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)\n"
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)\n"
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)\n"
at java.base/java.lang.Thread.run(Thread.java:829)\n"
[2022-03-23 11:41:24,304] INFO startScn=521862386111, endScn=null (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)
[2022-03-23 11:41:24,305] INFO Streaming metrics dump: OracleStreamingChangeEventSourceMetrics{currentScn=null, oldestScn=null, committedScn=null, offsetScn=null, logMinerQueryCount=0, totalProcessedRows=0, totalCapturedDmlCount=0, totalDurationOfFetchingQuery=PT0S, lastCapturedDmlCount=0, lastDurationOfFetchingQuery=PT0S, maxCapturedDmlCount=0, maxDurationOfFetchingQuery=PT0S, totalBatchProcessingDuration=PT0S, lastBatchProcessingDuration=PT0S, maxBatchProcessingThroughput=0, currentLogFileName=[], minLogFilesMined=0, maxLogFilesMined=0, redoLogStatus=[], switchCounter=0, batchSize=20000, millisecondToSleepBetweenMiningQuery=1000, hoursToKeepTransaction=0, networkConnectionProblemsCounter0, batchSizeDefault=20000, batchSizeMin=1000, batchSizeMax=100000, sleepTimeDefault=1000, sleepTimeMin=0, sleepTimeMax=3000, sleepTimeIncrement=200, totalParseTime=PT0S, totalStartLogMiningSessionDuration=PT0S, lastStartLogMiningSessionDuration=PT0S, maxStartLogMiningSessionDuration=PT0S, totalProcessTime=PT0S, minBatchProcessTime=PT0S, maxBatchProcessTime=PT0S, totalResultSetNextTime=PT0S, lagFromTheSource=DurationPT0S, maxLagFromTheSourceDuration=PT0S, minLagFromTheSourceDuration=PT0S, lastCommitDuration=PT0S, maxCommitDuration=PT0S, activeTransactions=0, rolledBackTransactions=0, committedTransactions=0, abandonedTransactionIds=[], rolledbackTransactionIds=[], registeredDmlCount=0, committedDmlCount=0, errorCount=1, warningCount=0, scnFreezeCount=0, unparsableDdlCount=0, miningSessionUserGlobalAreaMemory=0, miningSessionUserGlobalAreaMaxMemory=0, miningSessionProcessGlobalAreaMemory=0, miningSessionProcessGlobalAreaMaxMemory=0} (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)
[2022-03-23 11:41:24,305] INFO Offsets: OracleOffsetContext [scn=521862386111] (io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource)
[2022-03-23 11:41:24,781] ERROR WorkerSourceTask{id=kafka-connect-src-01-0} Task threw an uncaught and unrecoverable exception. Task is being killed and will not recover until manually restarted (org.apache.kafka.connect.runtime.WorkerTask)\n"
{"log":"org.apache.kafka.connect.errors.ConnectException: An exception occurred in the change event producer. This connector will be stopped.\n"
at io.debezium.pipeline.ErrorHandler.setProducerThrowable(ErrorHandler.java:50)\n"
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:192)\n"
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:57)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.streamEvents(ChangeEventSourceCoordinator.java:173)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.executeChangeEventSources(ChangeEventSourceCoordinator.java:140)\n"
at io.debezium.pipeline.ChangeEventSourceCoordinator.lambda$start$0(ChangeEventSourceCoordinator.java:109)\n"
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)\n"
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)\n"
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)\n"
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)\n"
at java.base/java.lang.Thread.run(Thread.java:829)\n"
{"log":"Caused by: io.debezium.DebeziumException: Online REDO LOG files or archive log files do not contain the offset scn 521862386111. Please perform a new snapshot.\n"
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:133)
[2022-03-23 11:53:42,641] INFO Found previous partition offset OraclePartition [sourcePartition={server=my-topicoracle}]: {commit_scn=null, transaction_id=null, snapshot_pending_tx=01001b003ab92400:521862385676, snapshot_scn=521862386111, scn=521862386111} (io.debezium.connector.common.BaseSourceTask)
Some Qs:
a) Between 15th March and 23rd March the pod was running happily (although not streaming changes since i did not make any changes on oracle tables), why does deleting the pod (which spawns new pod to replace it) cause it to fail? I would have expected either new pod is ok or between 15-23march that original pod hits same error before.
b) since the original snapshot on 14th March had 'AS OF SCN 521862386111' when it was pulling the data why does the pod on 23rd March care about looking for an SCN <= 521862386111 ? 'Pending transactions' it is mentioning about are not on my tables since these tables have not been touched for many weeks
c) even if there was pending transaction why was it not 'consumed' before 23 march?