-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
3.4.0.GA
-
None
-
False
-
-
False
-
-
Description of problem:
When undergoing performance testing we noticed that even though our cluster had Machine Autoscaler configured, we were never able to bring the autoscaler operator to spin up new Machines on demand.
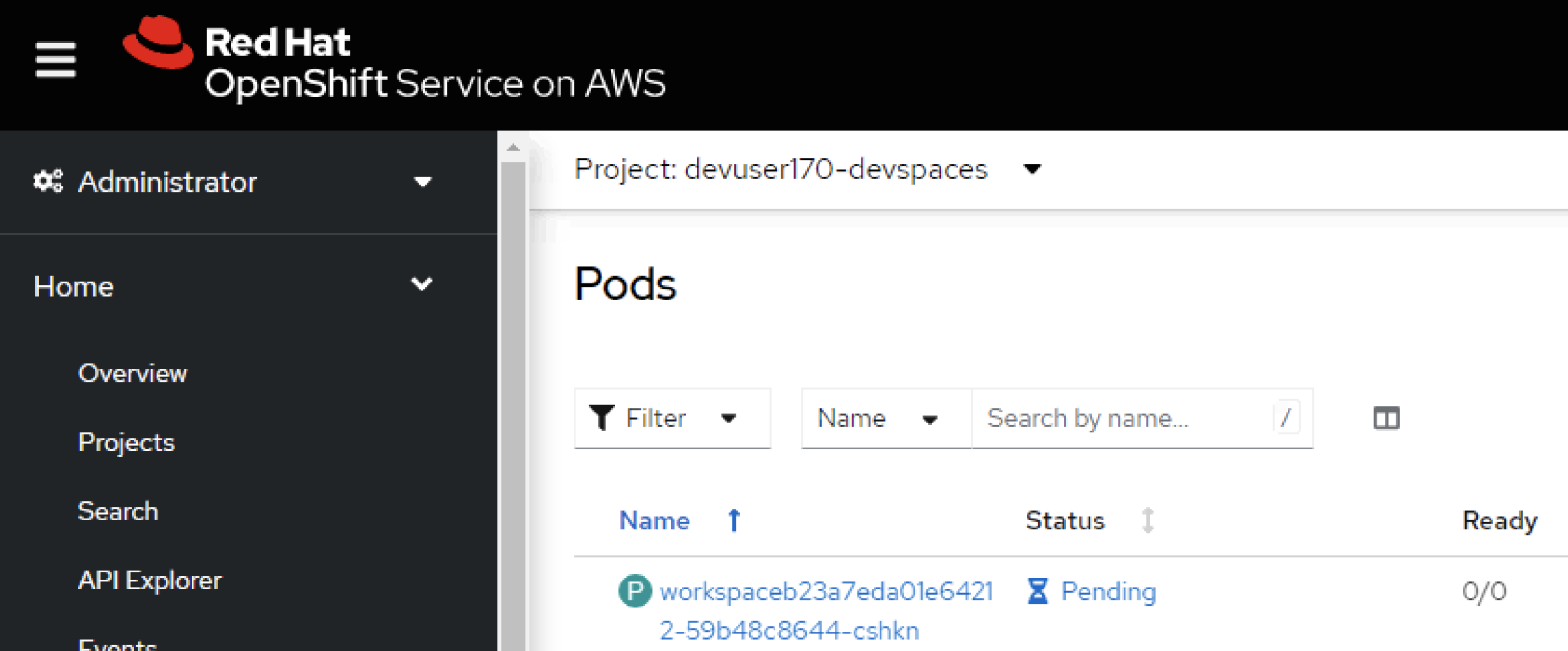
This is because whenever we filled the cluster capacity ( this was with about 170 Workspace instances), the next Workspace failed to start up (because of cluster full capacity) but the Dev Spaces operator immediately marked it as failed and then stopped it. Part of the "stop" routine is to set Deployment replicas 1->0. This means that the Workspace pod is never kept in the "pending" status, which is required for Autoscaler to work.
Prerequisites (if any, like setup, operators/versions):
MachineAutoscaler configured on your cluster
Steps to Reproduce
- Create as many (N) workspaces as required to exhaust the cluster capacity.
Actual results:
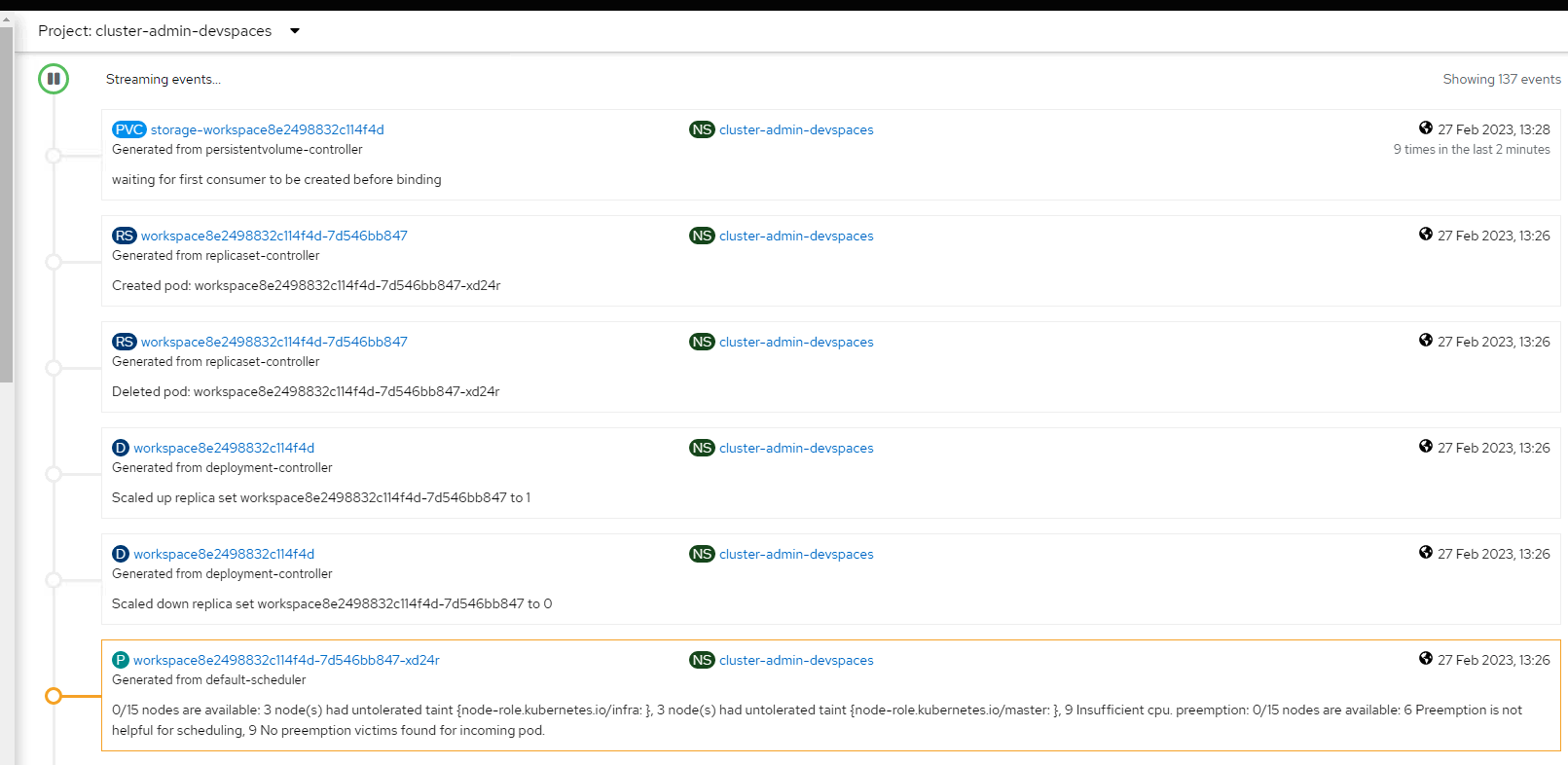
When Nth workspace fails to get created (due to full cluster capacity), the operator stops the deployment and sets replicas from 1 to 0, thus Auto scaler never kicks in.
Expected results:
When Nth workspace fails to get created (due to full cluster capacity), the operator keeps the Workspace pod in Pending phase which allows AutoScaler to kick in.
Reproducibility (Always/Intermittent/Only Once):
Always - as soon as the Cluster capacity is exhausted, we are no longer able to create any Workspace pods even though we have Autoscaler configured for our cluster.
Build Details:
Dev Spaces 3.4
Additional info (Such as Logs, Screenshots, etc):
We see this error in the UI
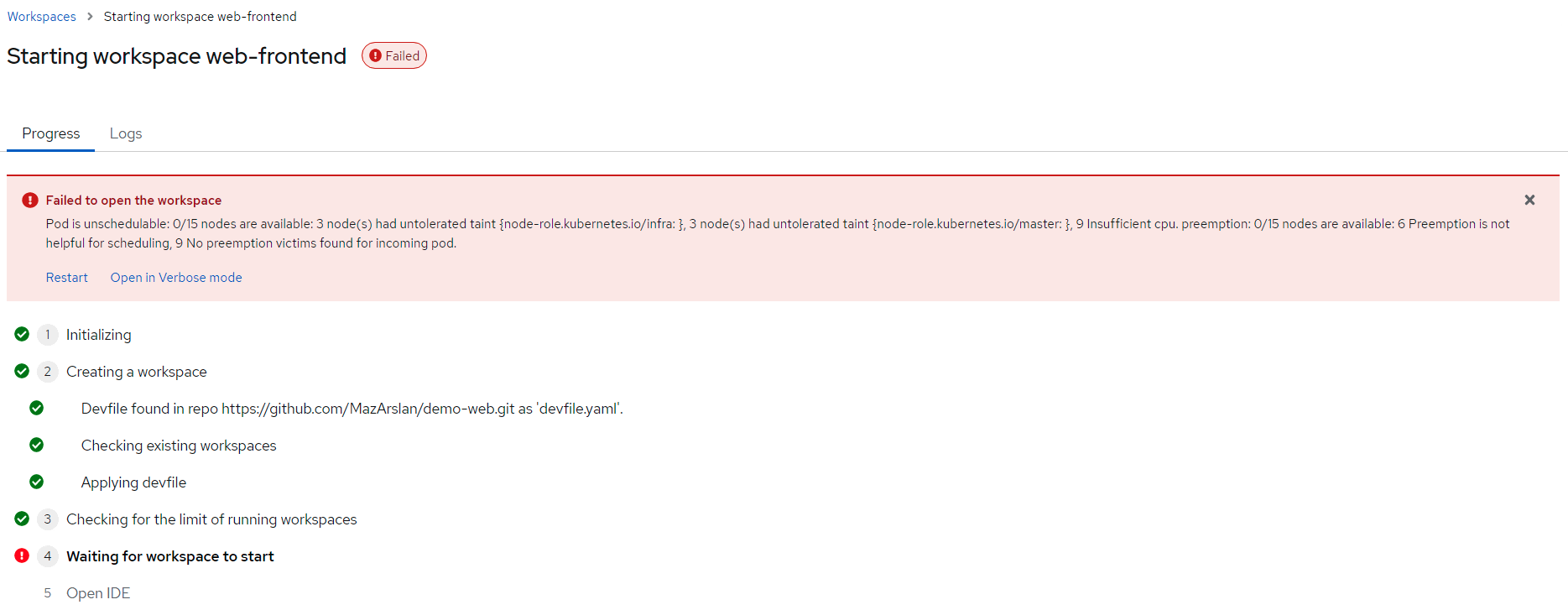
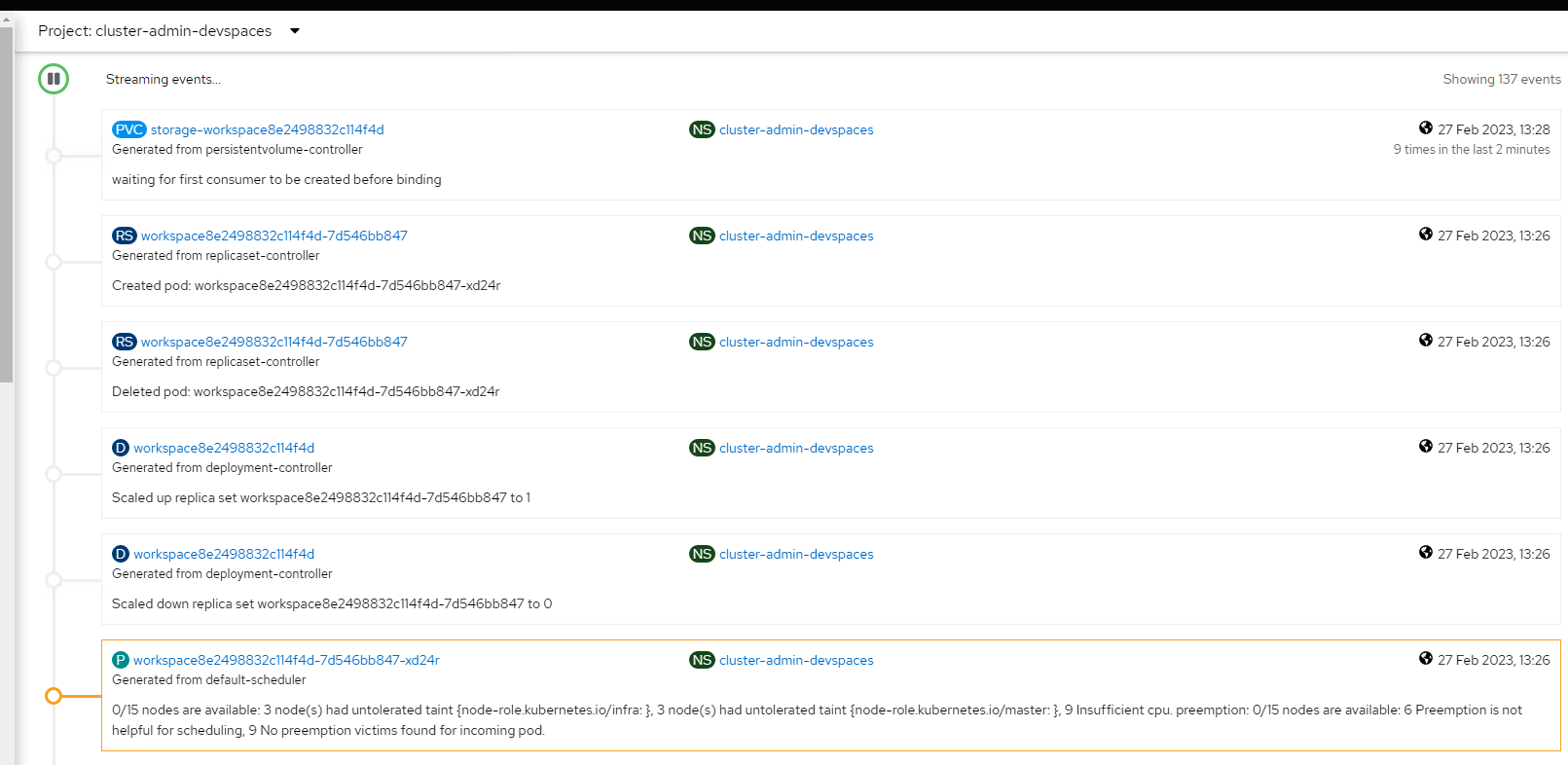
Which matches following OCP events (noticed the scale down to 0 which prevents autoscaler to work):
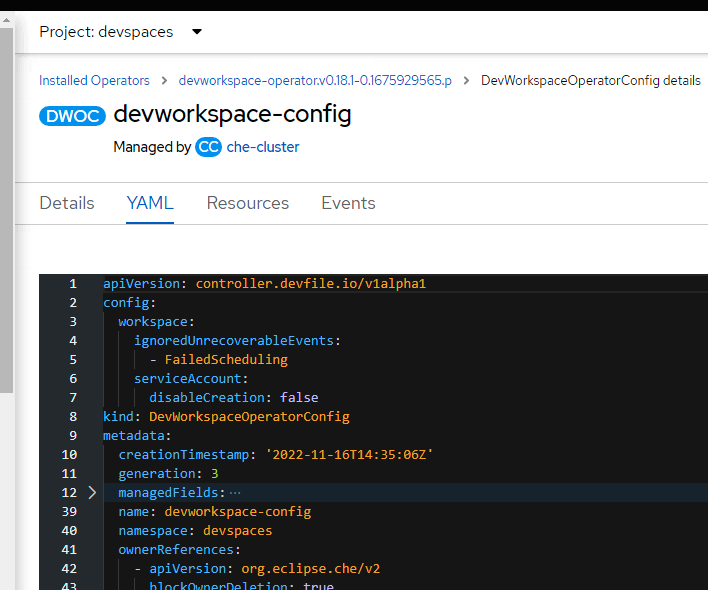
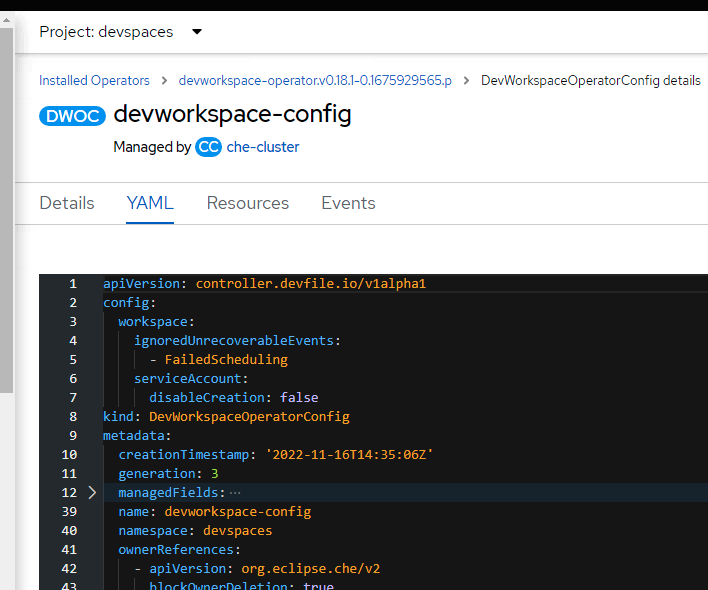
We also tried following workaround with no success:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}