-
Epic
-
Resolution: Unresolved
-
 Undefined
Undefined
-
None
-
None
-
None
-
client cache memory improvements
-
Quality / Stability / Reliability
-
50% To Do, 0% In Progress, 50% Done
-
False
-
-
False
-
None
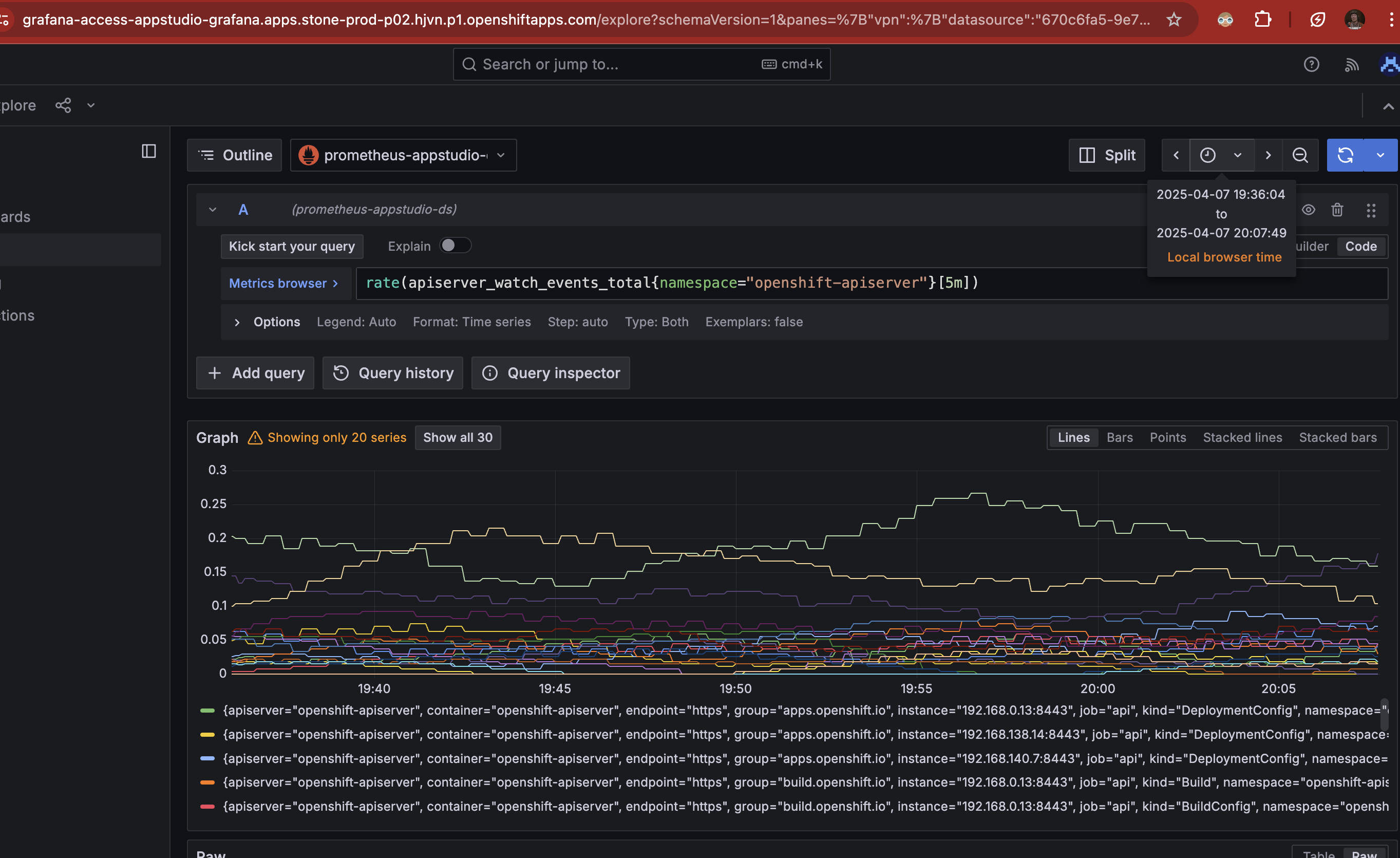
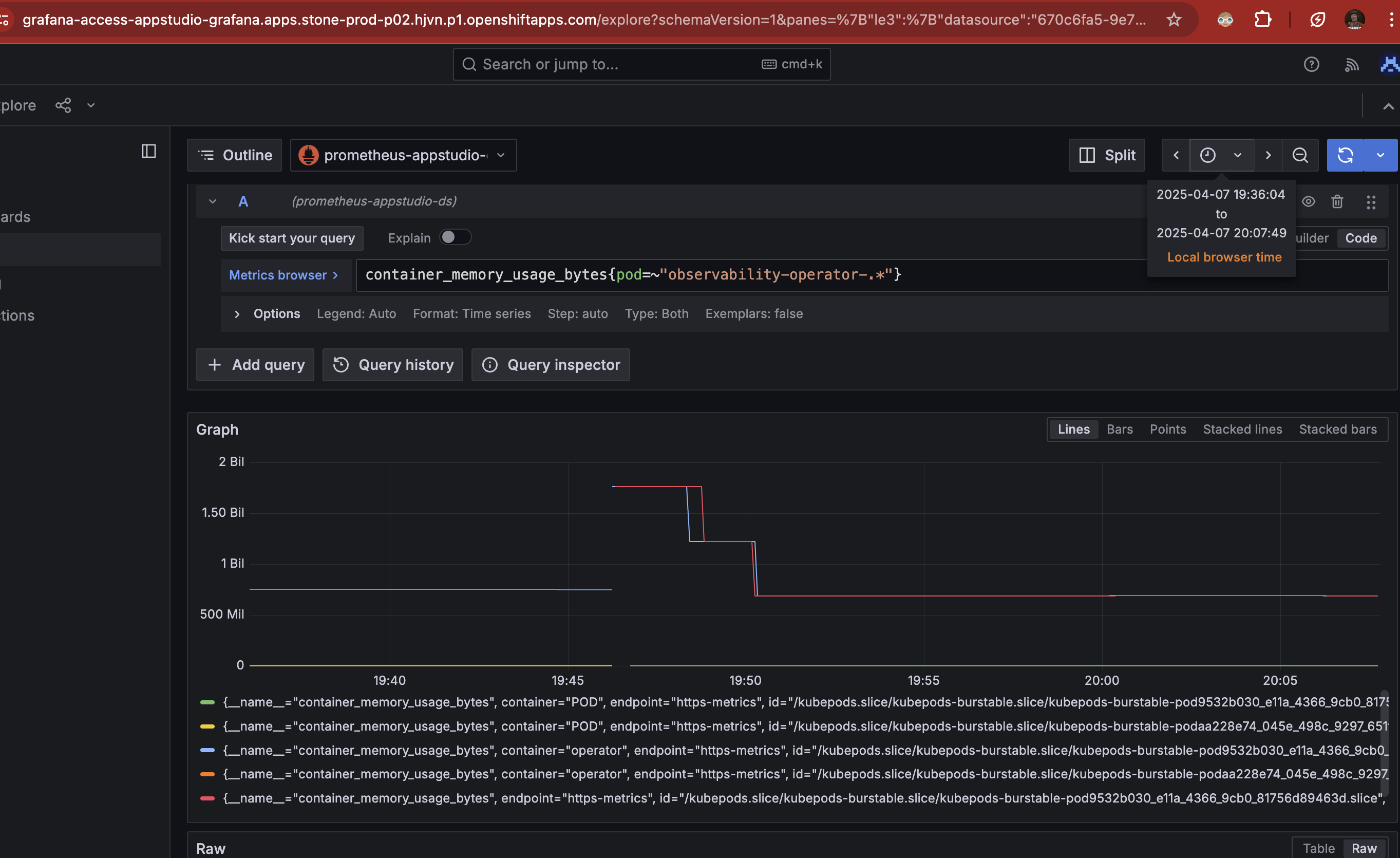
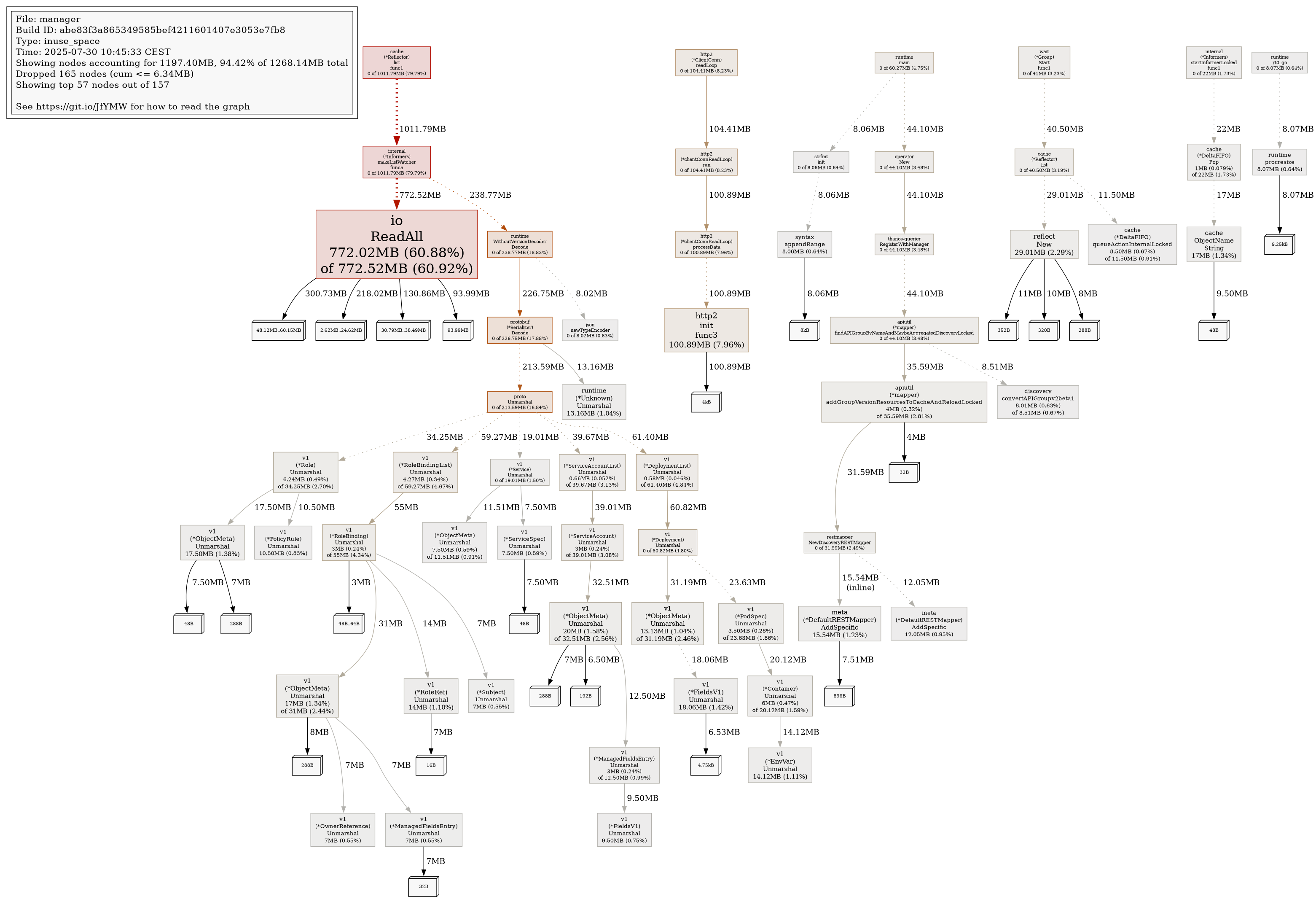
Related to COO-784 and associated workaround (increasing memory limits to address OOMKill events), a customer reports significantly higher memory usage in larger clusters.
In a cluster with ~1300 namespaces, the observability-operator pod consumes up to 1.9Gi of memory on startup, before stabilising around 1Gi. The previously suggested workaround of setting a 512Mi memory limit is insufficient in such environments; the customer required a limit of 2Gi to avoid OOMKill events.
This issue does not appear in smaller clusters, where 512Mi remains adequate.
Engineering suggested a new bug to review the behaviour/requirements specifically in larger clusters. Observability must-gather available in case 04115625.
OpenShift 4.16, Cluster Logging Operator 6.0.6.

{kind=link}
{kind=link}
{kind=link}