-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
1.3.0
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
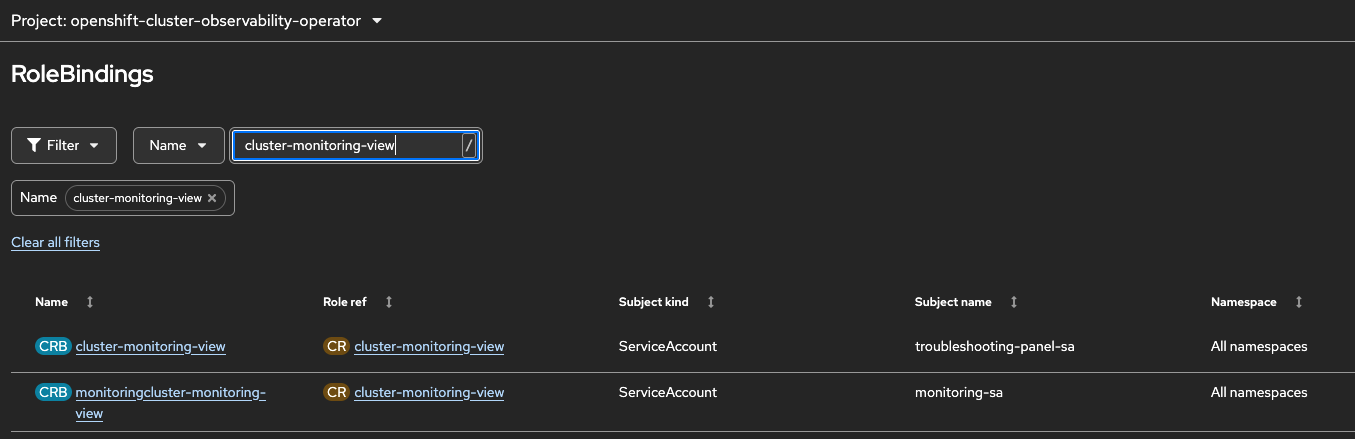
Install cluster OCP 4.19.18
Install COO 1.2.2
Configured all coo components
upgrade to COO 1.3.0
% oc get csv NAME DISPLAY VERSION REPLACES PHASE cluster-logging.v6.3.1 Red Hat OpenShift Logging 6.3.1 cluster-logging.v6.3.0 Succeeded cluster-observability-operator.v1.3.0 Cluster Observability Operator 1.3.0 cluster-observability-operator.v1.2.2 Succeeded loki-operator.v6.3.1 Loki Operator 6.3.1 loki-operator.v6.3.0 Succeeded opentelemetry-operator.v0.135.0-1 Red Hat build of OpenTelemetry 0.135.0-1 opentelemetry-operator.v0.127.0-2 Succeeded tempo-operator.v0.18.0-2 Tempo Operator 0.18.0-2 tempo-operator.v0.18.0-1 Succeeded % oc get pod NAME READY STATUS RESTARTS AGE distributed-tracing-6cf95f7b9f-nktgl 1/1 Running 0 9m health-analyzer-59d784b759-qplgm 0/1 CrashLoopBackOff 6 (2m48s ago) 8m56s korrel8r-667c6fdc4d-dclpt 1/1 Running 0 8m54s logging-777d656f7b-lh7g8 1/1 Running 0 8m58s monitoring-787fd65777-7frpv 1/1 Running 0 8m57s obo-prometheus-operator-6bdcb48887-ndk6l 1/1 Running 0 9m9s obo-prometheus-operator-admission-webhook-5b494c57ff-8f24c 1/1 Running 0 8m42s obo-prometheus-operator-admission-webhook-5b494c57ff-qqvq6 1/1 Running 0 8m43s observability-operator-5d97ff5df6-75rjx 1/1 Running 0 9m8s perses-0 1/1 Running 0 8m54s perses-operator-587bc6bcd9-z62tv 1/1 Running 0 9m8s troubleshooting-panel-d6bccccc5-6z9dl 1/1 Running 0 8m55s % oc logs health-analyzer-59d784b759-qplgm W1107 09:47:33.222076 1 client_config.go:659] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. 2025/11/07 09:47:33 INFO Parameters refresh-interval=30s prom-url=https://thanos-querier.openshift-monitoring.svc.cluster.local:9091/ alertmanager-url=https://alertmanager-main.openshift-monitoring.svc.cluster.local:9094 2025/11/07 09:47:33 INFO Starting server 2025/11/07 09:47:33 INFO Components health evaluation is disabled 2025/11/07 09:47:33 INFO Initializing groups collection start=2025-11-03T09:47:33.873Z end=2025-11-07T09:47:33.873Z step=1m0s 2025/11/07 09:47:33 INFO Loading alerts range 2025/11/07 09:47:33 ERROR Failed to initialize groups collection, terminating err="client_error: client error: 403"
health-analyzer logs:
W1107 09:47:33.222076 1 client_config.go:659] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.2025/11/07 09:47:33 INFO Parameters refresh-interval=30s prom-url=https://thanos-querier.openshift-monitoring.svc.cluster.local:9091/ alertmanager-url=https://alertmanager-main.openshift-monitoring.svc.cluster.local:90942025/11/07 09:47:33 INFO Starting server2025/11/07 09:47:33 INFO Components health evaluation is disabled2025/11/07 09:47:33 INFO Initializing groups collection start=2025-11-03T09:47:33.873Z end=2025-11-07T09:47:33.873Z step=1m0s2025/11/07 09:47:33 INFO Loading alerts range2025/11/07 09:47:33 ERROR Failed to initialize groups collection, terminating err="client_error: client error: 403"