-
Bug
-
Resolution: Unresolved
-
 Undefined
Undefined
-
None
-
CNV v4.18.8
-
Quality / Stability / Reliability
-
0.42
-
False
-
-
False
-
None
-
-
Critical
-
None
Description of problem:
Outages of 2 worker nodes hosting MON pods(2 out of 3 )in different ODF zones causes some of the windows VMs to crash and transition to recovery mode post chaos after the network latency has been removed. Worker node outage was created by introducing 60 seconds of network latency.
Version-Release number of selected component (if applicable):
openshift-cnv kubevirt-hyperconverged-operator.v4.18.8 OpenShift Virtualization 4.18.8 kubevirt-hyperconverged-operator.v4.18.3 Succeeded openshift-ovirt-infra node-healthcheck-operator.v0.9.0 Node Health Check Operator 0.9.0 node-healthcheck-operator.v0.8.2 Succeeded
How reproducible:
1. label the worker nodes with MON pods with label chaos=odf 2. Introduced 60s network latency for 15mins
Steps to Reproduce:
1. label the worker nodes with MON pods with label chaos=odf
2.Run chaos command, to cause 60s network latency for 15mins
podman run --rm -e LABEL_SELECTOR="chaos=odf" -e INSTANCE_COUNT=2 -e DURATION=900 -e TRAFFIC_TYPE=egress -e EGRESS='{latency: 60000ms}' -e KUBECONFIG=/tmp/config -e KRKN_KUBE_CONFIG=/tmp/config -e DISTRIBUTION='openshift' --net=host -v /tmp/config:/tmp/config:Z quay.io/krkn-chaos/krkn-hub:network-chaos 3.
Actual results:
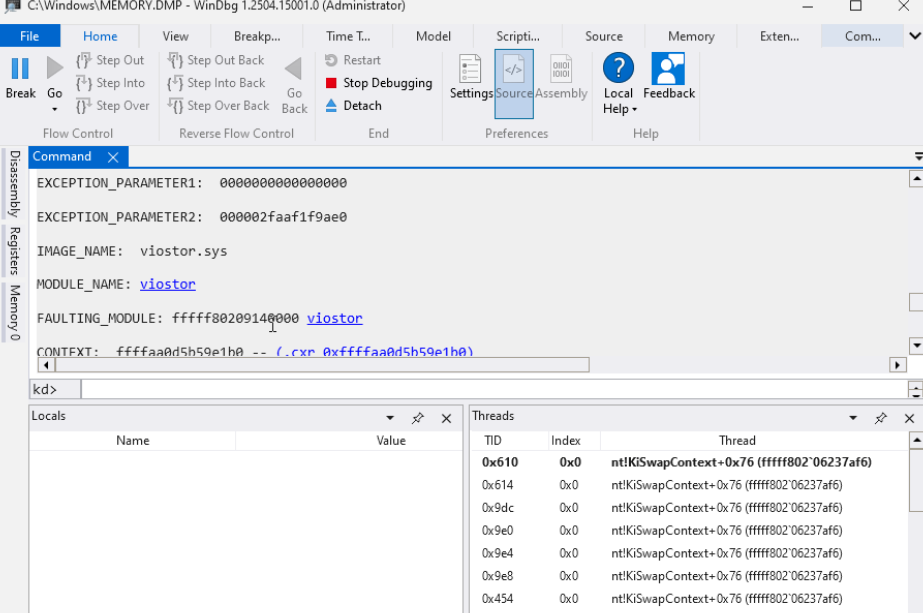
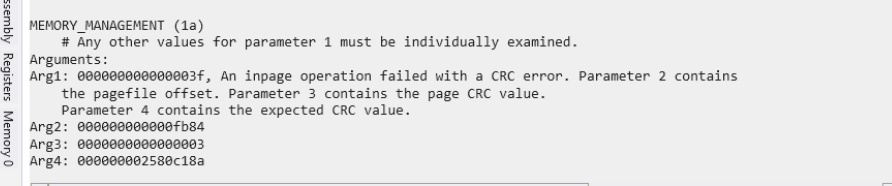
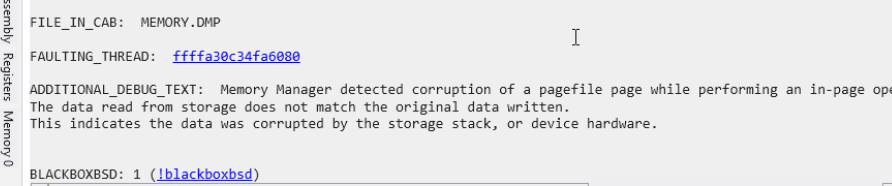
17 out of 255 Windows VM were not accessible through ssh.Of the 17, some of them had blank screen and most were at windows recovery screen post chaos after the MON worker nodes have recovered.
Expected results:
All the Windows VMs should be accessible through SSH post chaos.
Additional info:
- is cloned by
-
-

- Release Pending
-
- split to
-
-
- Closed
-
