-
Bug
-
Resolution: Done-Errata
-
 Major
Major
-
CNV v4.18.0
-
Quality / Stability / Reliability
-
0.42
-
False
-
-
False
-
CNV v4.18.0.rhel9-288
-
-
CNV I/U Operators Sprint 262, CNV I/U Operators Sprint 263, CNV I/U Operators Sprint 264, CNV I/U Operators Sprint 265, CNV I/U Operators Sprint 266, CNV I/U Operators Sprint 267
-
None
Description of problem:
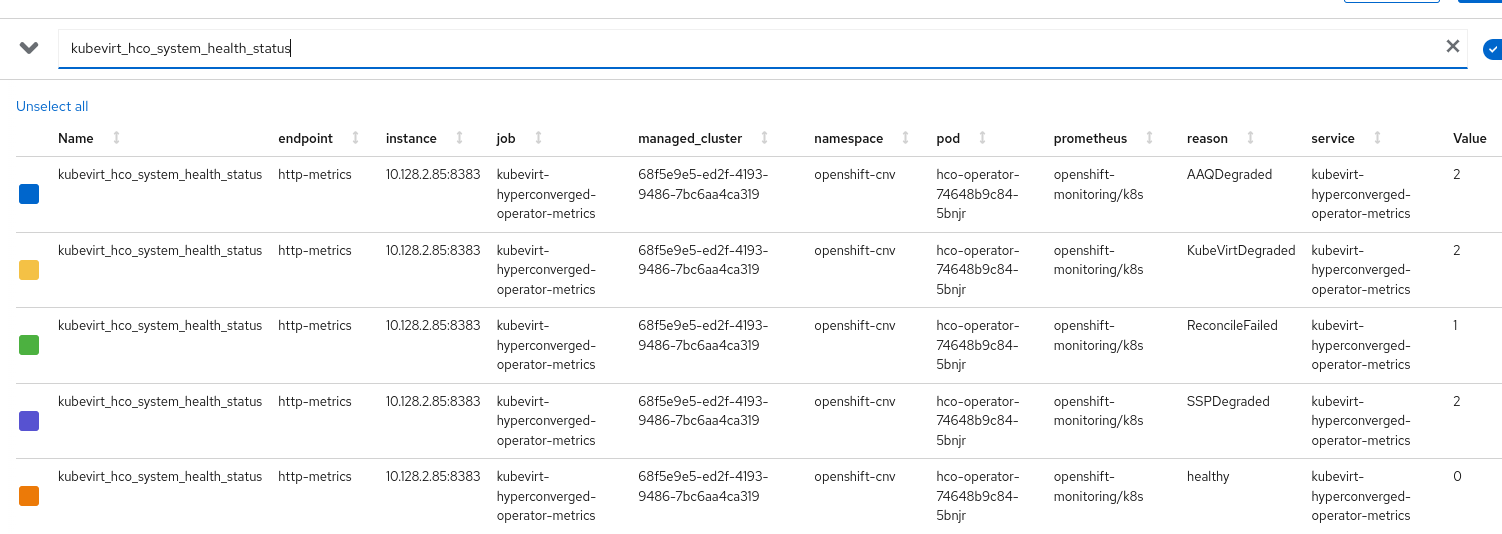
The alert OperatorConditionsUnhealthy should fire only once per cluster and the "kubevirt_hco_system_health_status" metric should only have 1 aggregated value. I dont see an issue in the conditions in the HCO CR page, but the conditions status in the Overview dashboard is in error and there are 3 OperatorConditionsUnhealthy alerts firing. I also see that the alert is firing both in critical and warning severities, which doesnt make sense. We should focus on the higher severity. If we should drop the "reason" label for that, than we should. If there is a way to aggregated the data in the reason label to a single value Like for example in the case in the screenshot : reason: "AAQDegraded, SSPDegraded, KubeVirtDegraded". See screenshots.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
Additional info:
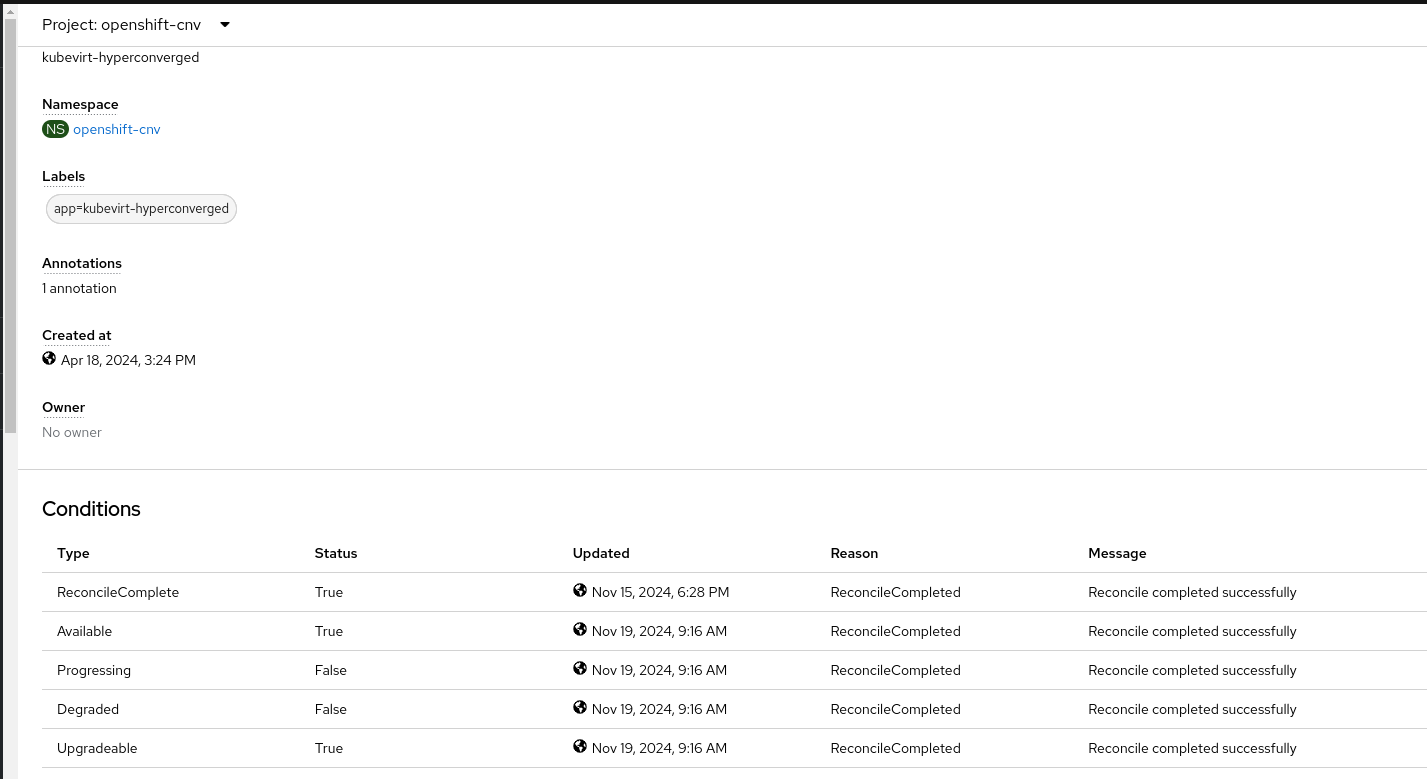
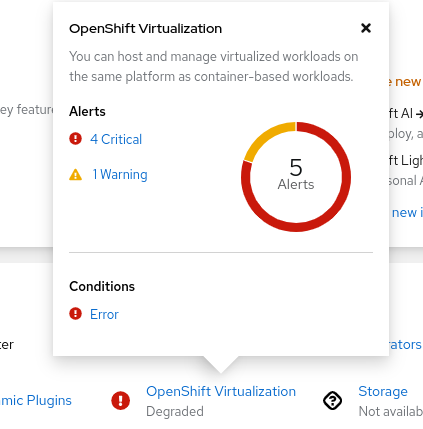
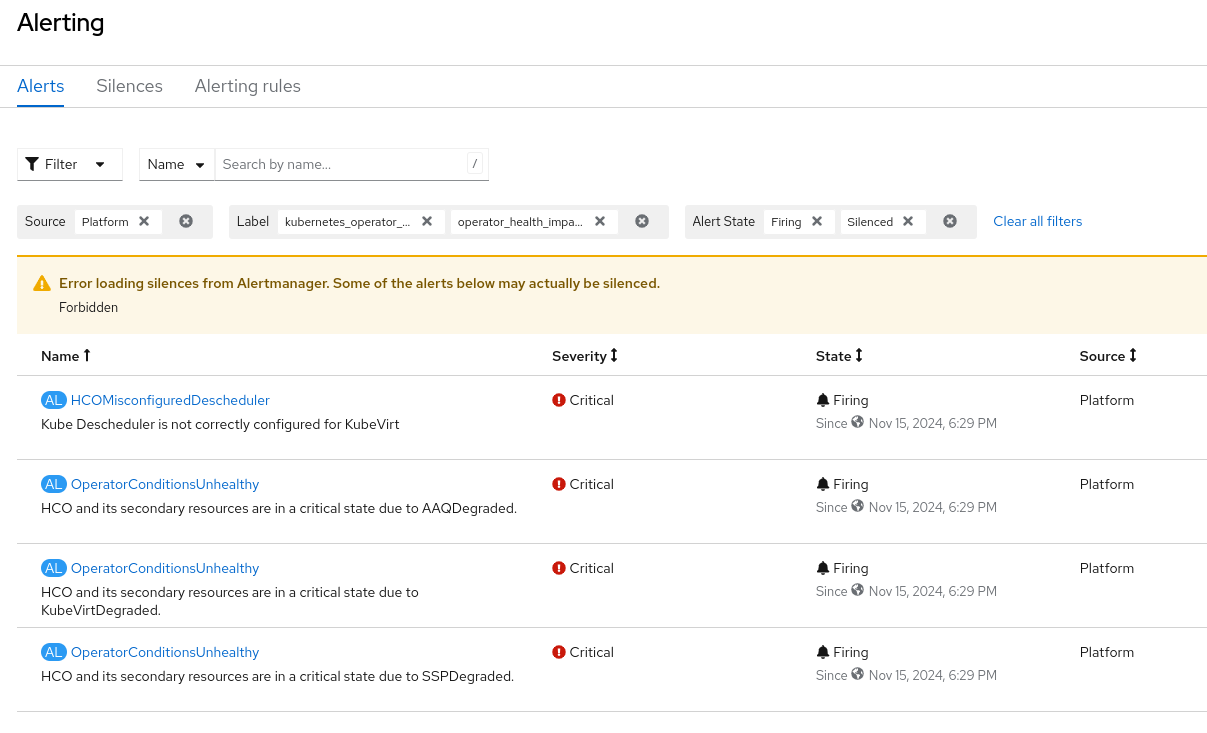
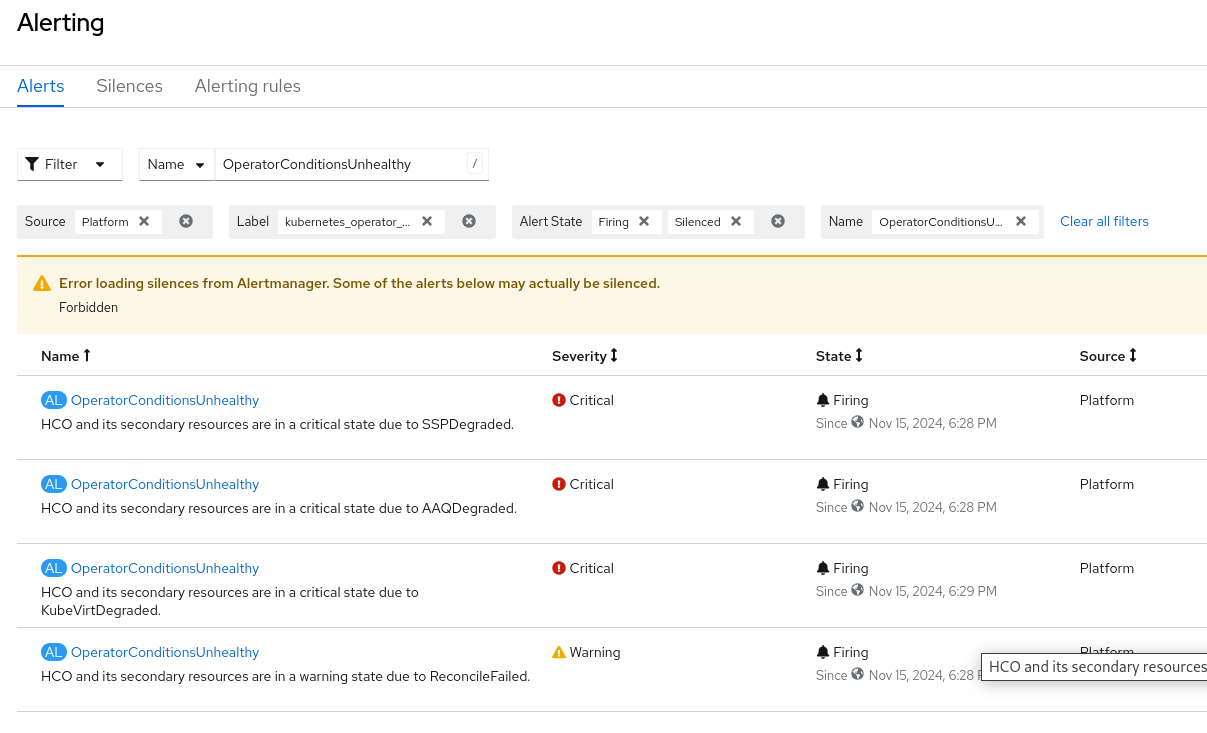
- duplicates
-
-

- Closed
-
- links to
-
 RHEA-2024:139653
OpenShift Virtualization 4.18.0 Images
RHEA-2024:139653
OpenShift Virtualization 4.18.0 Images
- mentioned on
