-
Epic
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
None
-
observability: operators should use component-base metrics package
-
To Do
-
Future Sustainability
-
0% To Do, 0% In Progress, 100% Done
-
False
-
None
-
False
-
None
-
None
-
None
Epic Goal
Today, we are not using the full potential of the metrics from client-go in OpenShift, so we don't have any way to easily detect failures in-between the API Server and their clients.
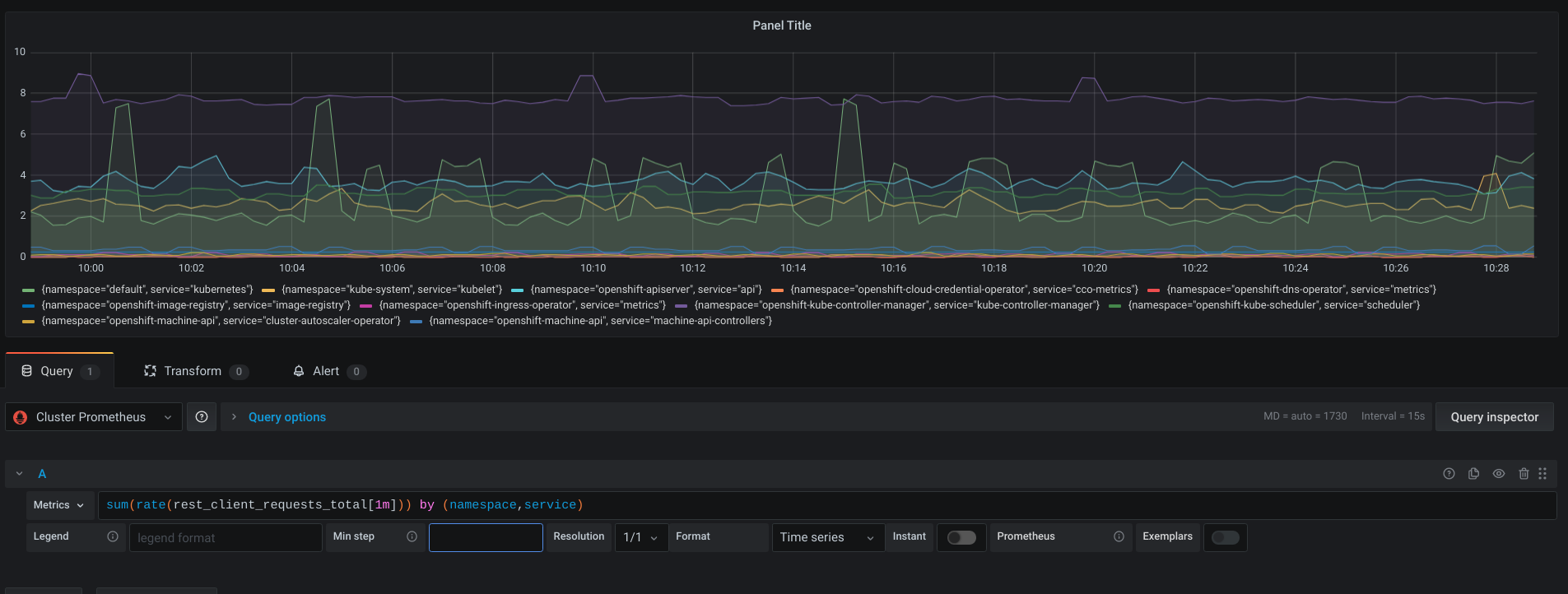
As shown below, only a handful of the operators use component-base to enable client-go metrics:
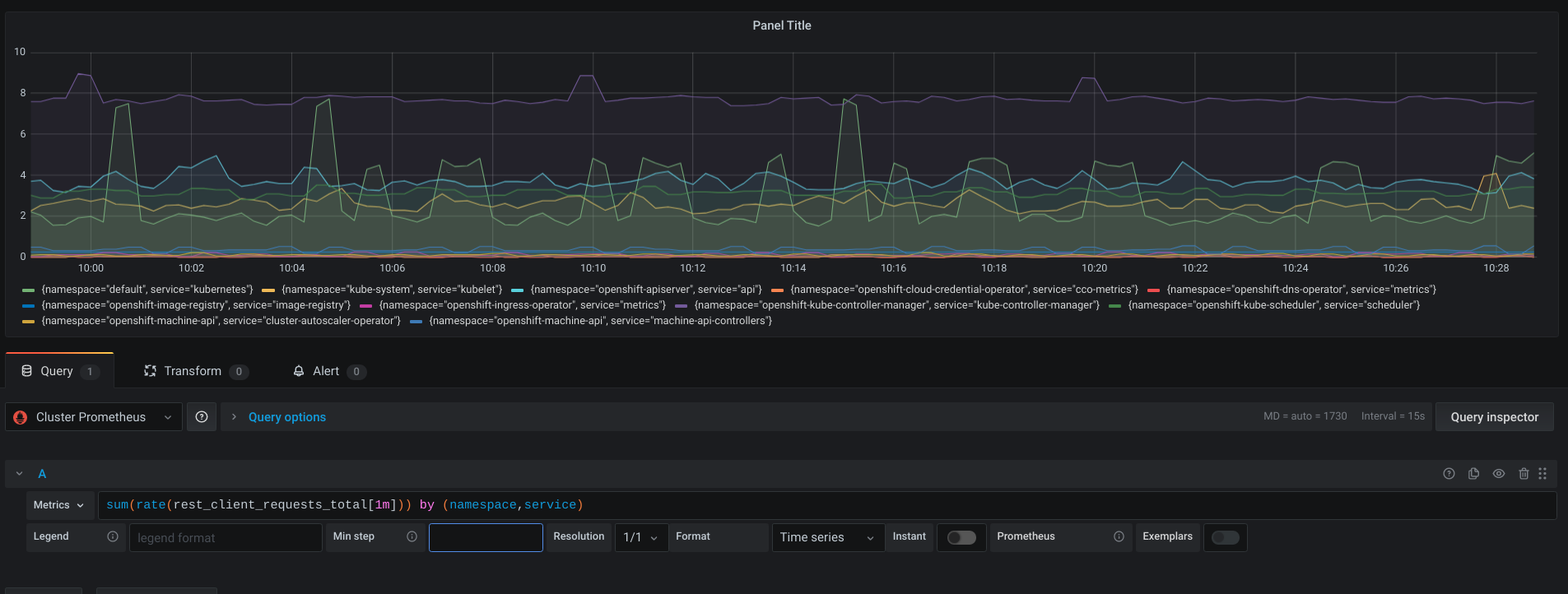
Why is this important?
- it can be insightful when we debug a cluster issue or look into customer escalation.
- it can help us know:
- which components are being heavily impacted?
- is any component being rate limited on the client-side?
- is a component being throttled by the server
Scenarios
An operator isn't behaving as expected and a user is experiencing a high-level issue because of that (UI not working as expected, ...). A cluster admin takes over and looks at the log of the operator where they can see that some API calls fail. Then the cluster-admin are in trouble because they don't really know what to look for and where. If it is a network issue, then it will take them quite some time to figure it out and that's only if they know a lot about their environment. Otherwise, they will have to reach out to support.
After this epic the scenario should change to:
A cluster-admin is paged by an alert mentioning that some client of the API Server is seeing some unavailability. They immediately go through the runbook of the alert and go through the steps provided to diagnose the exact issue. They open the dashboard linked in the runbook and figure out that the clients can't reach out to the API Server by the Kubernetes service anymore, which can be caused by DNS issues. They figure out that something changes and fix it themselves.
Benefits:
- Users aren't (or is less) impacted by the problem. They might not even notice it.
- Cluster-admin have clear steps to follow in order to solve their problem
- Support doesn't need to be involved anymore since admins have the keys to resolve the issues themselves
Acceptance Criteria
- client-go metrics are registered by all the operators that we are responsible for
- alerts are in place to detect issues in between the API Server and its clients
- a runbook is accessible to the admins to document the steps to resolve the issue
- a dashboard is available to help admins during their investigations
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
1.
|
QE Tracker |
|
Closed | |
Rahul Gangwar |
2.
|
TE Tracker |
|
Closed | |
Eric Rich |
3.
|
PX Tracker |
|
Closed | |
Eric Rich |

