-
Initiative
-
Resolution: Unresolved
-
 Critical
Critical
-
None
-
None
-
False
-
-
False
-
50% To Do, 50% In Progress, 0% Done
Intent of the Initiative
This initiative intentionally combines research, architecture, and incremental implementation.
The goal is not to finish GPUaaS end-to-end in one shot, but to:
- Build the foundations
- Validate assumptions through real usage
- Incrementally implement GPUaaS capabilities
- Reduce risk by learning while running
Implementation is part of the initiative, starting at a single-cluster scope and expanding gradually.
Context{}
This initiative is part of the[ GPU as a Non-Issue AIPCC Vision and Plan]
AIPCC is intentionally used as a controlled starting point to validate the model, tooling, and operational principles, with the long-term goal of expanding this approach to all AI engineering teams across the organization.
This initiative focuses on foundational capabilities and research and implementation internally in AIPCC, and is not yet the GPUaaS cross AI-ENG implementation itself.
High-Level Goal
Establish a single, accurate, and continuously updated view of GPU ownership, usage, and availability across teams, and research the right technical building blocks for a future GPUaaS solution.
High-Level Objectives
- Establish a single, live view of GPU ownership and usage
- Replace static spreadsheets with continuously updated data
- Research and validate GPUaaS building blocks
- Incrementally implement GPUaaS, starting with a single cluster (aipcc only)
- Expand gradually across clusters and clouds (aipcc only)
Scope
- Manual GPU inventory (Phase 0) across AIPCC
- Automated, live GPU inventory and visibility
- Central source of truth for GPU ownership, usage, and idle capacity
- GPU inventory architecture and data model
- Hands-on research of GPUaaS building blocks (Run:AI, Kueue, DRA, OpenShift AI)
- GPUaaS requirements definition
- GPUaaS architecture decision
- Incremental GPUaaS implementation
- Single-cluster GPUaaS on GCP
- Multi-cluster GPUaaS within the same cloud
- Expansion to additional clouds (AWS, IBM)
- AIPCC as the initial pilot scope
Out of Scope
- Organization-wide rollout
- Cost chargeback or billing models
- Financial ownership changes
- Fairness guarantees across teams
- SLA guarantees for opportunistic workloads
- Full production hardening
- 24/7 operational support
- Unified cross-cloud scheduler (initially)
- Solving non-GPU infrastructure problems
- Organization-wide rollout
- Cost chargeback or fairness models
- Full production hardening
- Cross-cloud unified scheduling (handled in later initiatives)
Phase Breakdown
Phase 1 – GPU Inventory & Live Mapping (Independent of GPUaaS)
step 1 – Phase 0: Manual GPU Inventory & Baseline
Objective{}
Create a single, authoritative baseline of all GPUs across AIPCC.
Description{}
Manually map all GPUs using a shared spreadsheet as the initial source of truth.
Deliverables{}
- List of all GPUs (cloud + on-prem)
- Owning team (financial ownership)
- Environment, cluster, and cloud
- Intended usage patterns*** (optional)
- Initial identification of idle capacity*** (optional)
step 2 – Automated GPU Inventory Architecture
Objective
Design a unified architecture for automatically collecting GPU data across all teams and environments, and enable a single management view of GPU ownership, access, and cost.
Description
This step includes architecture and design, plus an initial implementation path that results in a single, centralized dashboard view.
The goal is to define how GPU data can be collected live and centrally, regardless of where GPUs run, and how it will be presented to leadership as a trusted “source of truth.”
Key Questions
- What are the data sources (Kubernetes, cloud APIs, DCGM, billing, labels)?
- How do we map GPUs to teams, managers, and financial ownership automatically?
- How do we map “who has access” (projects, namespaces, IAM, clusters) per GPU pool?
- How do we distinguish used vs idle vs reclaimable in a consistent way?
- How do we keep the data accurate and near real time?
- How do we compute cost per GPU pool and roll it up by manager and org?
Deliverables
- Target architecture diagram (collection → normalization → storage → dashboard)
- Defined data model (ownership, manager, access, usage, utilization, cost, metadata)
- Dashboard requirements and mock (manager view: what GPUs exist under me, where, cost, access, current usage)
- Identified gaps and risks (coverage, accuracy, access mapping, cost mapping)
- Clear recommendation for implementation approach and MVP plan (what we can deliver first and what comes later)
Phase 2 – GPUaaS Research & Requirements Definition
step 3 – GPUaaS Requirements Definition
Objective{}
Define and document the functional and non-functional requirements for GPUaaS.
Description{}
As part of this step, we will translate the GPU as a Non-Issue vision into a clear set of requirements that describe expected behavior and constraints.
Example requirement areas include:
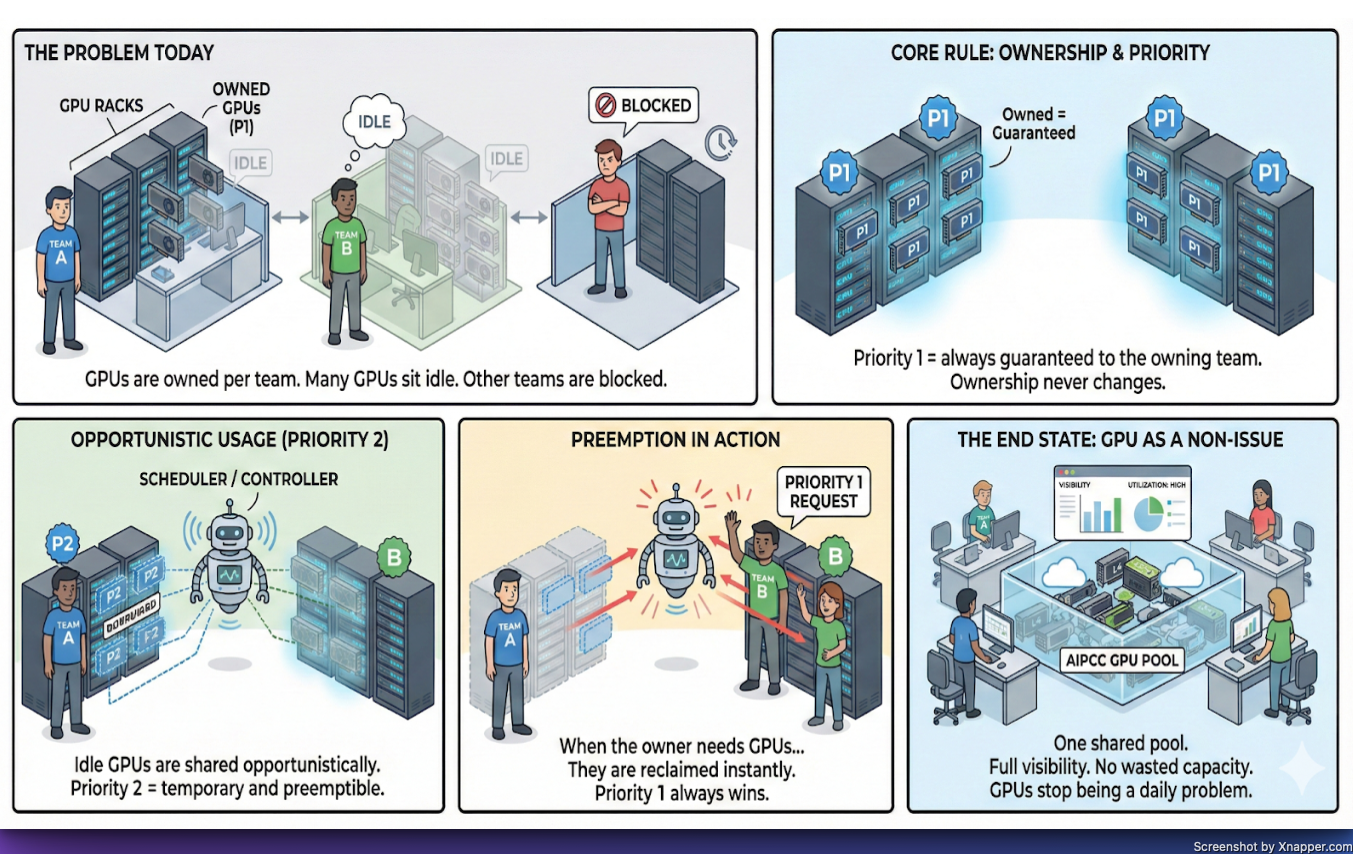
- Priority and ownership model (Priority 1 vs Priority 2)
- Quotas and preemption semantics
- User experience, observability, and transparency expectations
The output of this step is a structured requirements document that will be used as the input for architecture and implementation decisions.
Deliverables{}
- GPUaaS requirements document (e.g[ here|https://docs.google.com/document/d/1Nf9X2WbCiTqFPGEXy4FUObbvZKCRTML4sn-zQmNOVYY/edit?tab=t.0])
Deliverables{}
- GPUaaS requirements document
step 4 – Technology Research & Hands-On Evaluation
Objective{}
Perform a deep, hands-on evaluation of candidate technologies to inform the GPUaaS architecture.
Scope and Principles{}
This step is intentionally hands-on. All candidate solutions will be deployed, configured, and actively used.
Everyone researches all solutions. There is no split by ownership or “one person per tool.”
The goal is shared, deep understanding, not expertise silos.
Technologies to Evaluate{}
- Run:AI
- Kueue
- Kubernetes DRA
- GPUaaS-related capabilities in OpenShift AI
- Turbonomic/KubeTurbo
- Additional relevant options as they emerge
Execution{}
- Build a shared experimentation environment
- Run experiments locally and on the Model Validation GCP environment
- Deploy, configure, and operate each solution in practice
- Actively test real behaviors, not just documentation claims
- Identify limitations, operational complexity, and failure modes
Deliverables{}
- Comparative analysis across all solutions (pros / cons)
- Hands-on operational learnings
- Gap analysis against the requirements defined in step 3
- A comparison matrix showing which requirements are supported by which solution
The resulting is a step 1 for the architecture in the next step.
step 5 – GPUaaS Architecture Decision
Objective{}
Converge research into a single recommended architecture.
Description{}
Based on requirements and hands-on research, define:
- Which components we use
- How they integrate
- What we explicitly do NOT use
Deliverables{}
- Final GPUaaS architecture
- Clear rationale
- Implementation readiness assessment
Phase 3 – Single-Cluster GPUaaS Pilot (GCP)
step 6 – GPUaaS Implementation on GCP (Single Cluster)
Objective{}
Implement GPUaaS on a single GCP cluster with real teams and real workloads.
Scope{}
- At least 2 participating teams
- Explicit GPU quota enforcement per team
- Priority-based scheduling (Priority 1 / Priority 2)
- Preemption enabled and observable
- Production-like workloads (no synthetic or toy tests)
Execution{}
- Deploy the selected GPUaaS architecture on a single GCP cluster
- Onboard multiple teams with defined ownership and quotas
- Run real workloads under contention
- Validate scheduling, preemption, and recovery behavior end to end
Outcome{}
- GPUaaS behavior validated under real contention scenarios
- A dashboard that clearly shows:
- Which GPUs were allocated to which team
- When GPUs were used and by whom
- Which workloads ran opportunistically vs owned capacity
- Preemption events and timelines
- Usage patterns over time
- A concrete, demonstrable POC presented to Tom, backed by real data and observed behavior
Phase 4 – Multi-Cluster GPUaaS (Same Cloud)
step 7 – Multi-Cluster GPUaaS on GCP
Objective{}
Extend GPUaaS across multiple clusters within the same cloud.
Focus{}
- Consistent behavior
- Shared quotas across clusters
- Central observability
Phase 5 – Multi-Cloud Expansion
step 8 – GPUaaS Expansion to AWS / IBM Cloud
Objective{}
Extend the validated model to additional clouds.
{kind=link}