-
Bug
-
Resolution: Done
-
 Undefined
Undefined
-
ACM 2.10.0, ACM 2.9.0
-
None
Description of problem:
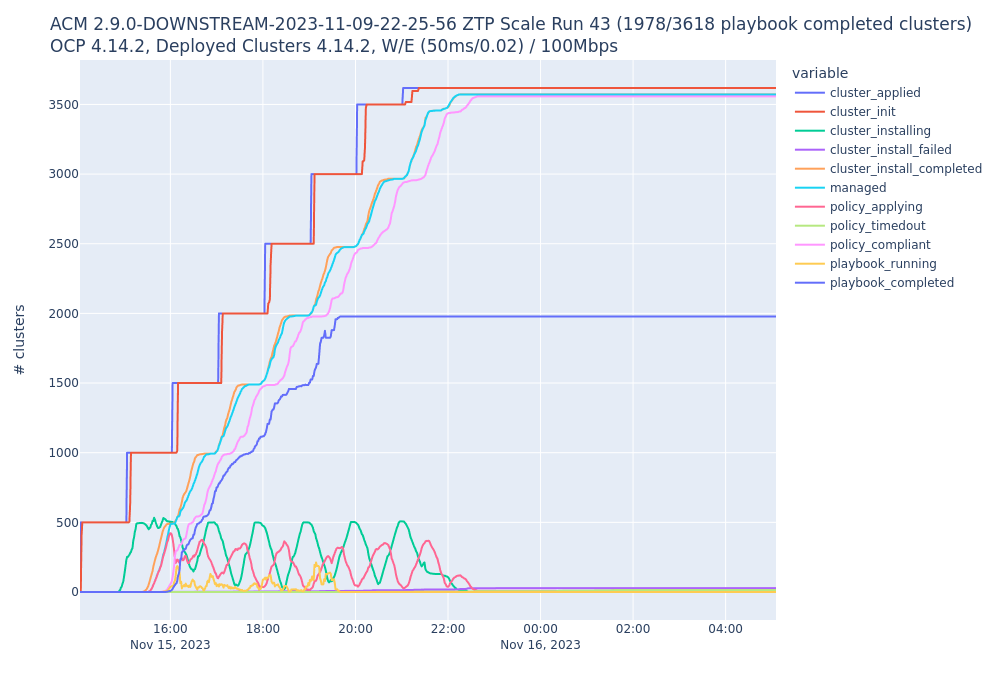
While deploying 3500+ SNO's with the du profile being applied and Ansible Automation Platform running a day2 playbook when clusters become labeled ztp-done=, the multicluster-operators-hub-subscription pod began OOM crashlooping which prevented any new clusters from having the ansiblejob run against them. This ceiling was hit at ~1978 clusters achieving the playbook (labeled ztp-ansible=Completed) but with 3000 clusters initialized for deployment. A complete graph will be available at the end of the test itself.
# oc get po -n open-cluster-management multicluster-operators-hub-subscription-6d6d74ffc9-tt8pj NAME READY STATUS RESTARTS AGE multicluster-operators-hub-subscription-6d6d74ffc9-tt8pj 0/1 CrashLoopBackOff 26 (3m58s ago) 3h27m
Version-Release number of selected component (if applicable):
Hub OCP - 4.14.2
Deployed SNOs - 4.14.2
ACM - 2.9.0-DOWNSTREAM-2023-11-09-22-25-56
AAP - aap-operator.v2.4.0-0.1698896316
How reproducible:
Steps to Reproduce:
- ...
Actual results:
Expected results:
Additional info:
Describe of crashlooping pod:
# oc describe po -n open-cluster-management multicluster-operators-hub-subscription-6d6d74ffc9-tt8pj
Name: multicluster-operators-hub-subscription-6d6d74ffc9-tt8pj
Namespace: open-cluster-management
Priority: 0
Service Account: multicluster-operators
Node: e27-h02-000-r650/fc00:1004::5
Start Time: Wed, 15 Nov 2023 21:09:19 +0000
Labels: app=multicluster-operators-hub-subscription
ocm-antiaffinity-selector=multicluster-operators-hub-subscription
pod-template-hash=6d6d74ffc9
Annotations: k8s.ovn.org/pod-networks:
{"default":{"ip_addresses":["fd01:0:0:1::b63/64"],"mac_address":"0a:58:80:97:e1:29","gateway_ips":["fd01:0:0:1::1"],"routes":[{"dest":"fd0...
k8s.v1.cni.cncf.io/network-status:
[{
"name": "ovn-kubernetes",
"interface": "eth0",
"ips": [
"fd01:0:0:1::b63"
],
"mac": "0a:58:80:97:e1:29",
"default": true,
"dns": {}
}]
openshift.io/scc: restricted-v2
seccomp.security.alpha.kubernetes.io/pod: runtime/default
Status: Running
SeccompProfile: RuntimeDefault
IP: fd01:0:0:1::b63
IPs:
IP: fd01:0:0:1::b63
Controlled By: ReplicaSet/multicluster-operators-hub-subscription-6d6d74ffc9
Containers:
multicluster-operators-hub-subscription:
Container ID: cri-o://48140ea5c494f5235724d89db1047b465a5c4914966253f8a771feac6c617aae
Image: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/multicluster-operators-subscription-rhel8@sha256:53745951f4ec1f22764dcdd5e23284989fb30c8ab093d0d706d69a41c5892c7d
Image ID: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/multicluster-operators-subscription-rhel8@sha256:0ccc316710f31a9ec9feb50db129819999f4967db2cdaed2d21b495173f4ecbd
Port: 8443/TCP
Host Port: 0/TCP
Command:
/usr/local/bin/multicluster-operators-subscription
--sync-interval=60
--leader-election-lease-duration=137s
--leader-election-renew-deadline=107s
--leader-election-retry-period=26s
State: Running
Started: Thu, 16 Nov 2023 00:37:36 +0000
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Thu, 16 Nov 2023 00:29:00 +0000
Finished: Thu, 16 Nov 2023 00:32:29 +0000
Ready: True
Restart Count: 27
Limits:
cpu: 750m
memory: 2Gi
Requests:
cpu: 150m
memory: 128Mi
Liveness: exec [ls] delay=15s timeout=1s period=15s #success=1 #failure=3
Readiness: exec [ls] delay=15s timeout=1s period=15s #success=1 #failure=3
Environment:
WATCH_NAMESPACE:
POD_NAME: multicluster-operators-hub-subscription-6d6d74ffc9-tt8pj (v1:metadata.name)
POD_NAMESPACE: open-cluster-management (v1:metadata.namespace)
DEPLOYMENT_LABEL: multicluster-operators-hub-subscription
OPERATOR_NAME: multicluster-operators-hub-subscription
Mounts:
/etc/subscription from multicluster-operators-subscription-tls (ro)
/tmp from tmp (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-lk57f (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
tmp:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
multicluster-operators-subscription-tls:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
kube-api-access-lk57f:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
ConfigMapName: openshift-service-ca.crt
ConfigMapOptional: <nil>
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node-role.kubernetes.io/infra:NoSchedule op=Exists
node.kubernetes.io/memory-pressure:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Unhealthy 103m kubelet Readiness probe errored: rpc error: code = NotFound desc = container is not created or running: checking if PID of 480d876f97f4c1a8e76a8e7f90146ed23222c486a883d8bf38f44426a9b5793b is running failed: container process not found
Normal Pulled 81m (x19 over 3h31m) kubelet Container image "e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/multicluster-operators-subscription-rhel8@sha256:53745951f4ec1f22764dcdd5e23284989fb30c8ab093d0d706d69a41c5892c7d" already present on machine
Warning BackOff 6m34s (x527 over 3h24m) kubelet Back-off restarting failed container multicluster-operators-hub-subscription in pod multicluster-operators-hub-subscription-6d6d74ffc9-tt8pj_open-cluster-management(59313c70-cd53-4a0c-98b7-daf526b94ac4)
- depends on
-
ACM-9030 Ansible integration performance enhancement in large scale env
-

- Closed
-