-
Bug
-
Resolution: Done
-
 Undefined
Undefined
-
ACM 2.6.4
Description of problem:
While deploying ~2500 SNOs with ACM 2.6.4 for ACM upgrade testing, the managedcluster-import-controller-v2 is OOMing and preventing further clusters from being imported around a scale of ~2400 clusters. Likely we just need the same solution in https://issues.redhat.com/browse/ACM-2275 backported to 2.6
Version-Release number of selected component (if applicable):
ACM - 2.6.4-DOWNSTREAM-2023-01-31-18-35-03
OCP Hub 4.12.1, SNOs 4.12.1
How reproducible:
Steps to Reproduce:
- ...
Actual results:
Expected results:
Additional info:
# oc get po -n multicluster-engine -l app=managedcluster-import-controller-v2
NAME READY STATUS RESTARTS AGE
managedcluster-import-controller-v2-6d4bdb4d8-4xm4r 1/1 Running 79 (4m42s ago) 16h
managedcluster-import-controller-v2-6d4bdb4d8-pw6pw 1/1 Running 80 (4m4s ago) 16h
# oc get managedcluster --no-headers | grep -v Unknown | grep True -c
2413
# oc get deploy -n multicluster-engine managedcluster-import-controller-v2 -o json | jq '.spec.template.spec.containers[0].resources'
{
"limits": {
"cpu": "500m",
"memory": "2Gi"
},
"requests": {
"cpu": "50m",
"memory": "96Mi"
}
}
A describe on one of the pods showing OOM:
# oc describe po -n multicluster-engine managedcluster-import-controller-v2-6d4bdb4d8-4xm4r
Name: managedcluster-import-controller-v2-6d4bdb4d8-4xm4r
Namespace: multicluster-engine
Priority: 0
Service Account: managedcluster-import-controller-v2
Node: e27-h05-000-r650/fc00:1002::7
Start Time: Mon, 13 Feb 2023 21:34:43 +0000
Labels: app=managedcluster-import-controller-v2
ocm-antiaffinity-selector=managedclusterimport
pod-template-hash=6d4bdb4d8
Annotations: k8s.ovn.org/pod-networks:
{"default":{"ip_addresses":["fd01:0:0:1::3c/64"],"mac_address":"0a:58:df:cf:6d:db","gateway_ips":["fd01:0:0:1::1"],"ip_address":"fd01:0:0:...
k8s.v1.cni.cncf.io/network-status:
[{
"name": "ovn-kubernetes",
"interface": "eth0",
"ips": [
"fd01:0:0:1::3c"
],
"mac": "0a:58:df:cf:6d:db",
"default": true,
"dns": {}
}]
k8s.v1.cni.cncf.io/networks-status:
[{
"name": "ovn-kubernetes",
"interface": "eth0",
"ips": [
"fd01:0:0:1::3c"
],
"mac": "0a:58:df:cf:6d:db",
"default": true,
"dns": {}
}]
openshift.io/scc: restricted-v2
scheduler.alpha.kubernetes.io/critical-pod:
seccomp.security.alpha.kubernetes.io/pod: runtime/default
Status: Running
IP: fd01:0:0:1::3c
IPs:
IP: fd01:0:0:1::3c
Controlled By: ReplicaSet/managedcluster-import-controller-v2-6d4bdb4d8
Containers:
managedcluster-import-controller:
Container ID: cri-o://816e98a3aa209f91b5394e7ba8099deca3cee373650ace0a0f69d9d3eb4d266e
Image: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/managedcluster-import-controller-rhel8@sha256:4868d67485b6392985a495ae3fc177e4b090fb252fdd6dffc40e353aa0db126d
Image ID: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/managedcluster-import-controller-rhel8@sha256:4868d67485b6392985a495ae3fc177e4b090fb252fdd6dffc40e353aa0db126d
Port: <none>
Host Port: <none>
State: Running
Started: Tue, 14 Feb 2023 14:51:35 +0000
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Tue, 14 Feb 2023 14:42:27 +0000
Finished: Tue, 14 Feb 2023 14:51:08 +0000
Ready: True
Restart Count: 82
Limits:
cpu: 500m
memory: 2Gi
Requests:
cpu: 50m
memory: 96Mi
Environment:
WATCH_NAMESPACE:
POD_NAME: managedcluster-import-controller-v2-6d4bdb4d8-4xm4r (v1:metadata.name)
MAX_CONCURRENT_RECONCILES: 10
OPERATOR_NAME: managedcluster-import-controller
DEFAULT_IMAGE_PULL_SECRET: multiclusterhub-operator-pull-secret
DEFAULT_IMAGE_REGISTRY:
REGISTRATION_OPERATOR_IMAGE: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/registration-operator-rhel8@sha256:85dc5defbf986e36842dfa8cbf3ff764c1a4636779eb6d0bb553bc52263f6867
REGISTRATION_IMAGE: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/registration-rhel8@sha256:112c8f9f6c237dace9f2137525256ac034b8fd7a853ccd00de3963c84799fa3b
WORK_IMAGE: e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/work-rhel8@sha256:2a1efeda7ce5b3a974078b31b603f157b087d7fc8408e40e4c6e2c03efcf4530
POD_NAMESPACE: multicluster-engine (v1:metadata.namespace)
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-9rkdh (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-9rkdh:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
ConfigMapName: openshift-service-ca.crt
ConfigMapOptional: <nil>
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node-role.kubernetes.io/infra:NoSchedule op=Exists
node.kubernetes.io/memory-pressure:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Started 42m (x75 over 12h) kubelet Started container managedcluster-import-controller
Normal Pulled 15m (x80 over 12h) kubelet Container image "e27-h01-000-r650.rdu2.scalelab.redhat.com:5000/acm-d/managedcluster-import-controller-rhel8@sha256:4868d67485b6392985a495ae3fc177e4b090fb252fdd6dffc40e353aa0db126d" already present on machine
Normal Created 15m (x80 over 12h) kubelet Created container managedcluster-import-controller
Warning BackOff 3m40s (x99 over 11h) kubelet Back-off restarting failed container
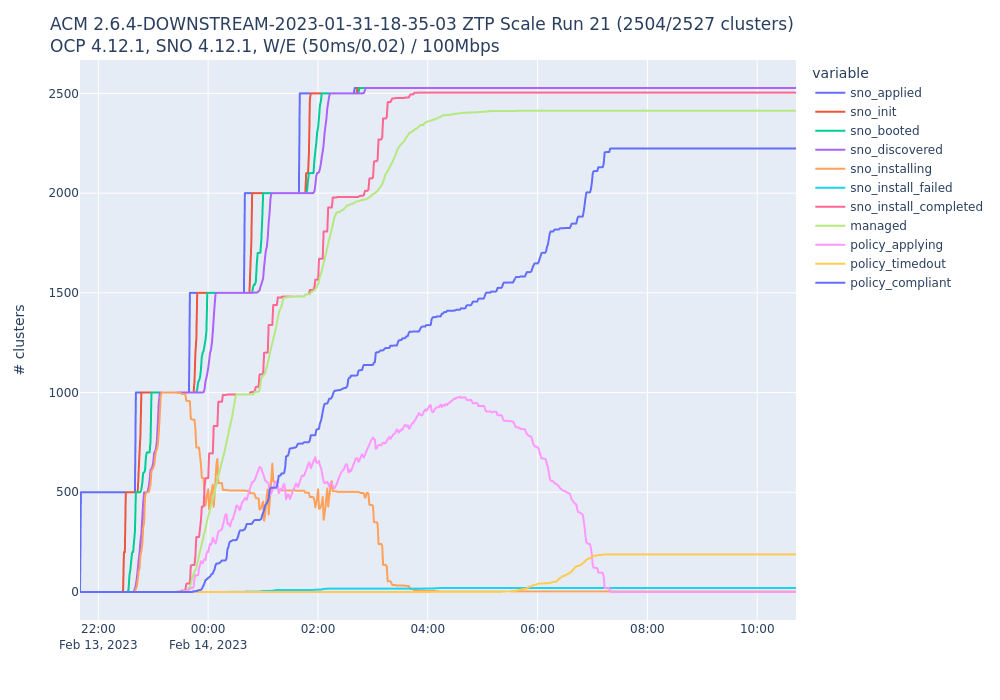
The attached image of a test result shows a ceiling hit before all provisioned clusters were managed (green managed line never meets red sno_install_completed line)
{kind=link}