-
Story
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
None
-
Future Sustainability
-
False
-
None
-
False
-
3
-
None
-
None
-
SDN Sprint 205
There is a little background in https://bugzilla.redhat.com/show_bug.cgi?id=1981872
essentially, there are always some failures in ovn upgrade around i/o timeouts
and what seems like connectivity issues. two things I've noticed:
1) we seem to always have ovsdb and/or openvswitch core dumps in our upgrade
jobs. a story for this work is here
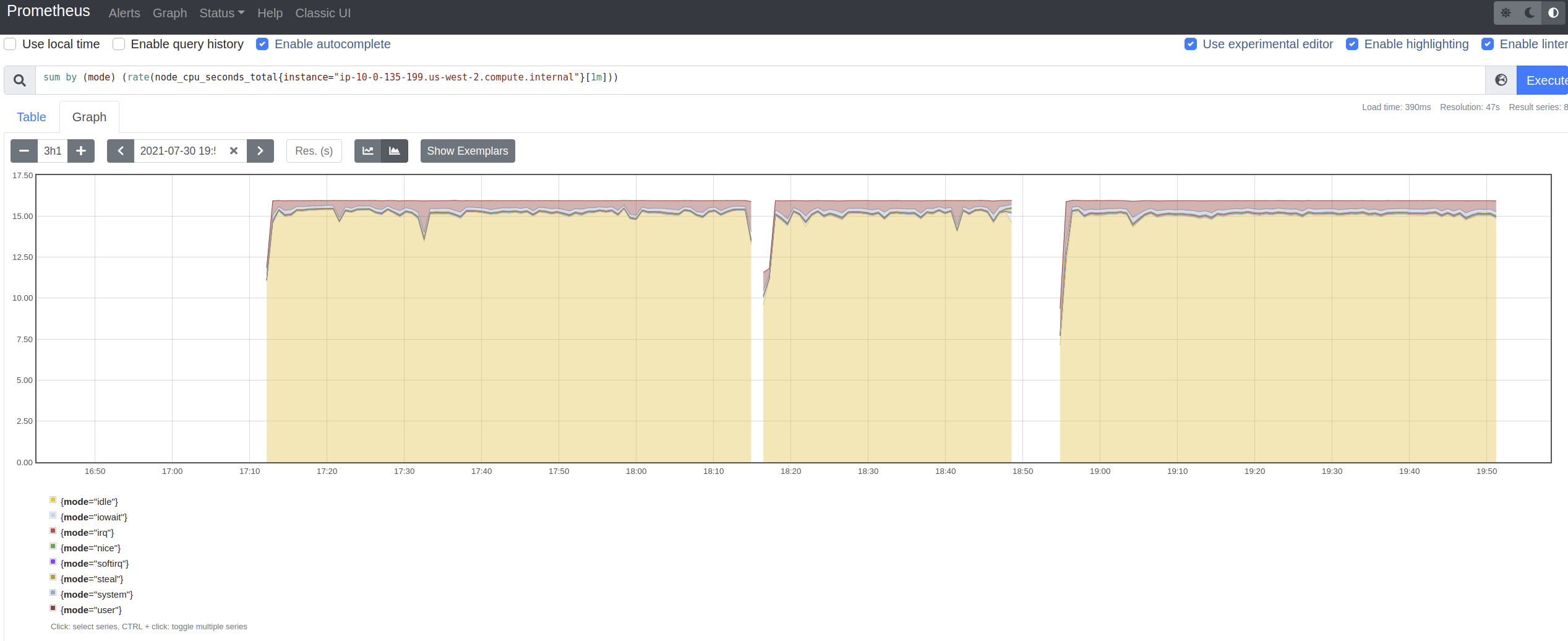
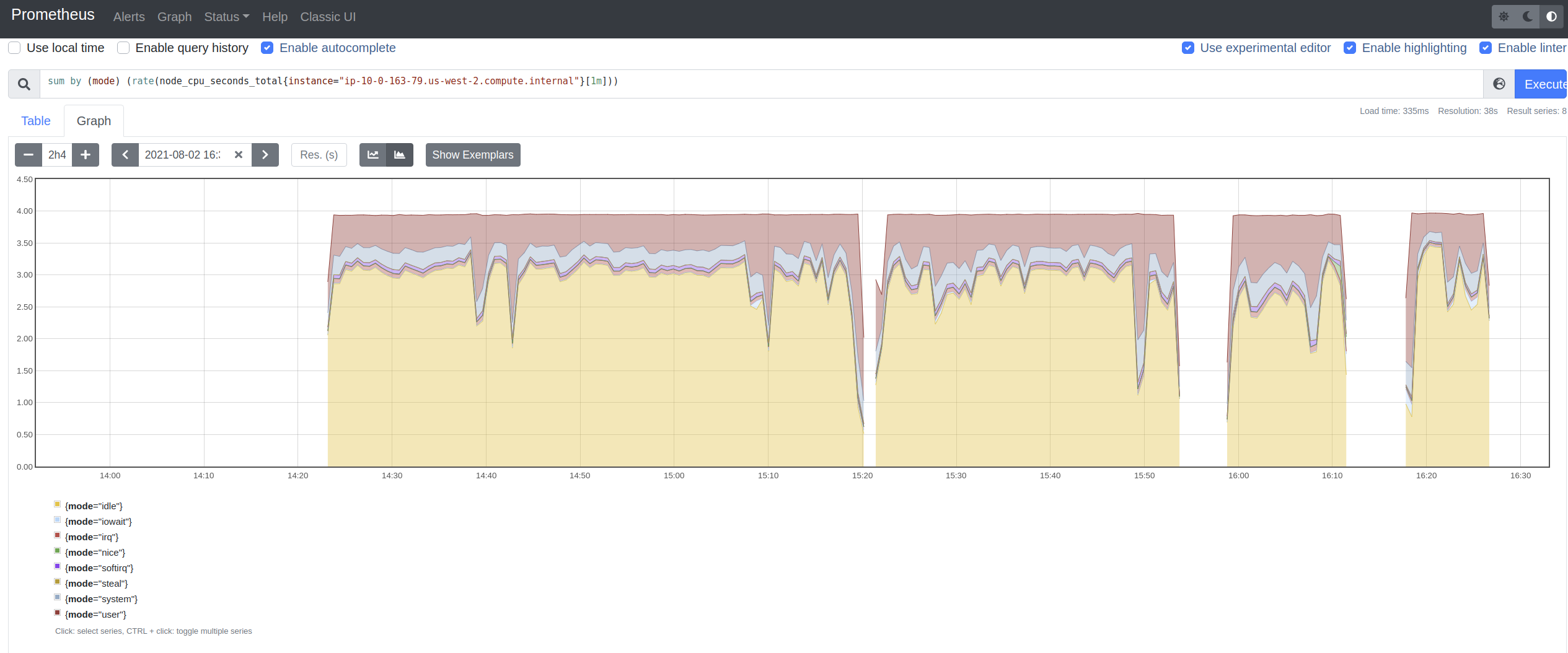
2) sometimes there are failures in some alerts test case that indicate high cpu
usage alerts.
This story is for #2 to see if maybe we are pegging the CPUs and possibly
throwing more resources at the cluster we will see better results in the upgrade
job.