-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
1.4
-
None
-
5
-
False
-
-
False
-
RHIDP-3055 - Support High Availability
-
-
Bug Fix
-
Done
-
-
-
RHDH Plugins 3265, RHDH Plugins 3266
-
Critical
Description of problem:
When scaling the deployment to 3 pods + redis cache, RBAC roles are not synced: only the pod that is actually creating the resource will serve it afterwards. This happens when creating the role with both UI and Rest API. **
Issue found as part of manual testing the HA scenario for 1.4.
Prerequisites (if any, like setup, operators/versions):
Steps to Reproduce
While testing the HA scenario with these steps: **
- Installed an RHDH instance with RBAC enabled, Keycloak authentication, users ingestion, a few catalog resources registered and Redis Cache enabled.
Scaled the deployments to 3 pods.
Changed the Openshift route traffic policy to round-robin (the scenario needed to be forced, ensuring that all pods would receive incoming requests).
Added a static token to the app-config. - Sent batches of 10, 30, 50, 100 REST API calls to add a new location with a random GUID as User-Agent header
Verified the pods logs to ensure all the pods were responding to those requests.
Observed behaviour was: pods replied with a 201 Created status code only once, 500 and 409 Conflict for all the other requests; meaning the backstage is correctly handling the conflicts. - Performed a batch of 50 requests to get the Location just created, all pods responded with the correct resource; meaning all pods are acting in sync.
- Edited the Opensihft service to serve traffic from one pod at a time (by changing the label selectors): created a new location again, UI is showing consistent results across all pods.
- Performed step 1-2-3-4 again, but creating a RBAC Role instead. The results were not consistent and the pods were not aligned.
When creating the Role via UI, only the pod that actually created the resource was serving it after. The other pods didn’t show the new role.
When creating the role via REST API, only the first pod completing the request would return it afterwards; the other pods would return a 404 error.
Example of the role created:
{
"memberReferences": [
"user:default/guest"
],
"name": "role:default/somerole",
"metadata": {
"description": ""
}
}
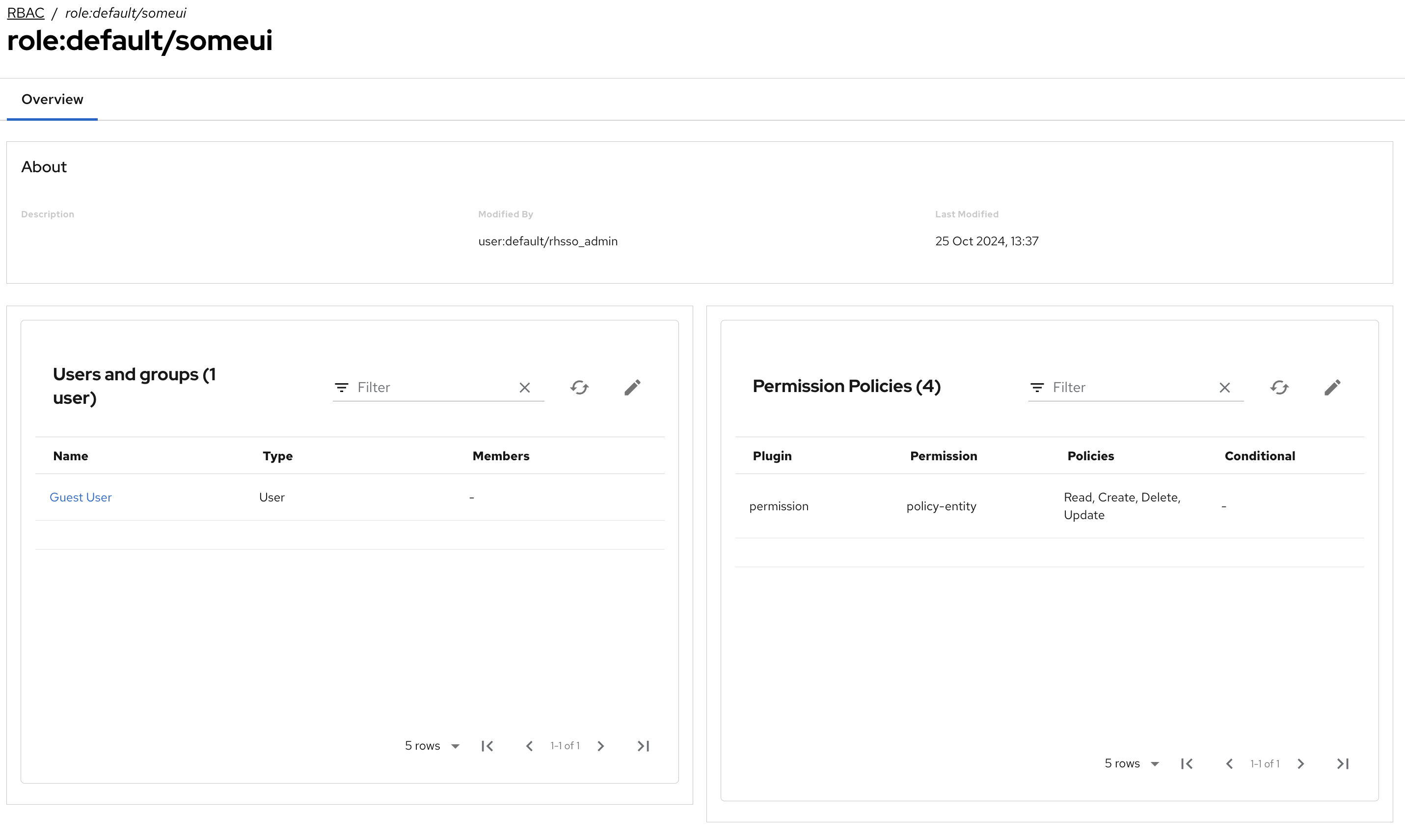
Same role also created with UI:
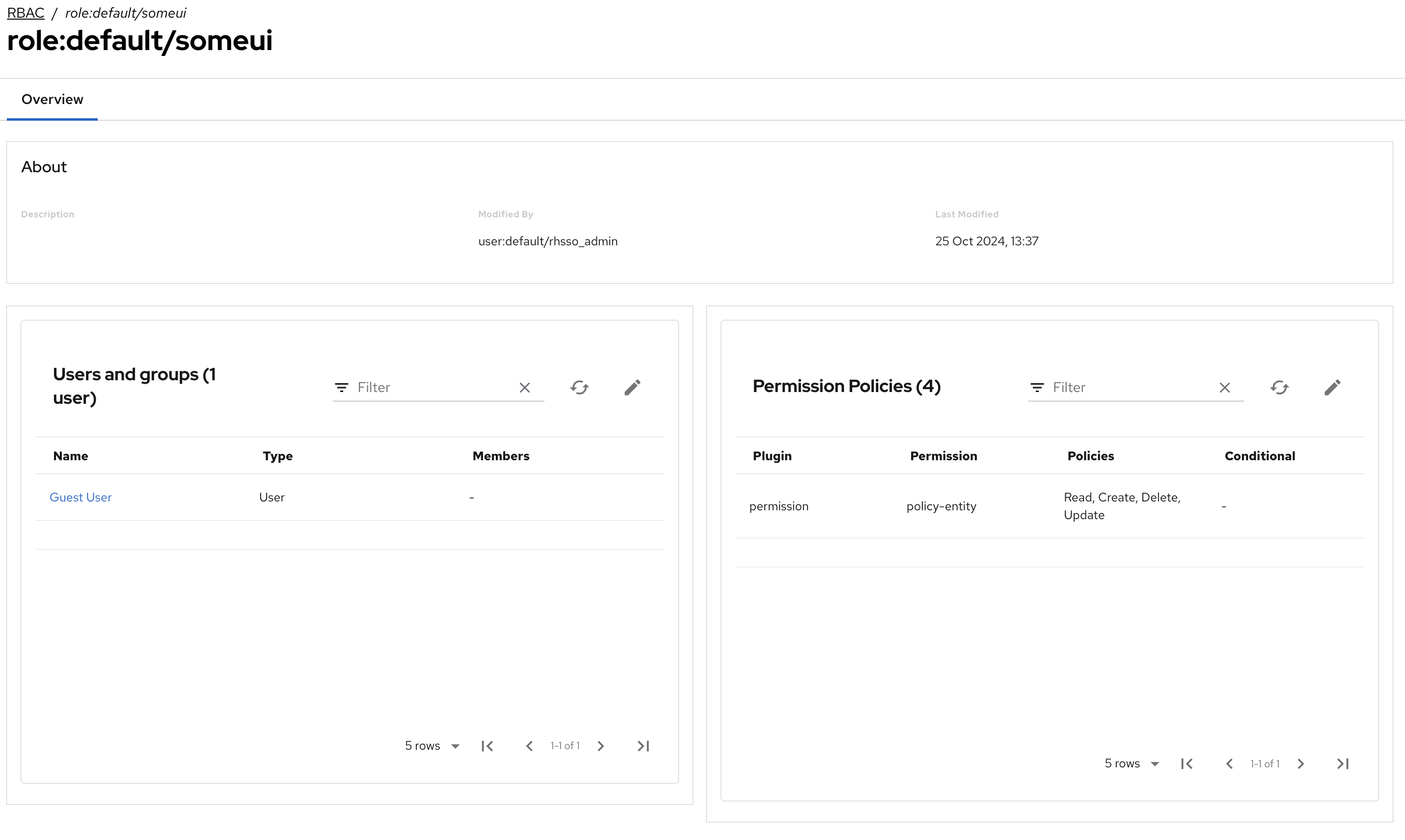
Role is always created successfully. Only the pod that completed the creation request (either via UI or API) will serve the role back afterwards.
This was verified by targeting all the pods one by one (editing the Openshift service selector) and sending a batch of API requests, which returned differently based on the pod that was hit. Logs of each pods were showing 200/404 errors aligned with the UI/API behaviour.
Actual results:
Roles are not served consistently across all pods.
Expected results:
Roles are served consistently across all pods.
Reproducibility (Always/Intermittent/Only Once):
Always. Tested with 1.3.1 **
Build Details:
Additional info (Such as Logs, Screenshots, etc):
- blocks
-
RHIDP-4475 [QE] Investigate how to test the High Availability scenario
-

- In Progress
-
- links to
